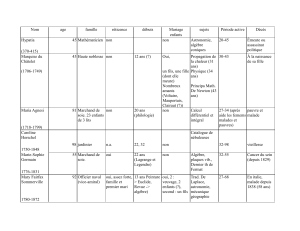
Processus de Lévy libre sur des groupes duaux et matrices

Processus de Lévy libre sur des groupes duaux et
matrices aléatoires
Introduction au Domaine de Recherche
Michaël Ulrich
Sous la direction d’Uwe Franz 1
15 octobre 2013
1. Professeur à l’Université de Franche-Comté

Table des matières
1 Une théorie des probabilités non commutatives 1
1.1 Introduction............................ 1
1.2 Cumulants............................. 4
1.3 Lien avec les matrices . . . . . . . . . . . . . . . . . . . . . . 4
2 Le concept de groupe dual 7
2.1 Motivation ............................ 7
2.2 Une première généralisation : la notion de groupe quantique . 7
2.3 Produit libre et groupe dual . . . . . . . . . . . . . . . . . . . 8
2.4 Retour sur les processus de Lévy . . . . . . . . . . . . . . . . 10
Bibliographie 11
1

Résumé
Ce document vise à introduire le domaine des probabilités libres et à tracer
quelques liens avec les matrices aléatoires. Il s’attachera en particulier à
définir la notion de processus de Lévy dans le contexte non-commutatif. Il
fournira ainsi des éléments permettant de comprendre le contexte de la thèse
commencée par l’auteur et qui s’intitule : "Processus de Lévy libre sur des
groupes duaux et matrices aléatoires" 1.
1. Je souhaite tout particuliérement utiliser cette occasion pour remercier toutes les
personnes qui m’ont accompagnées au cours de ma scolarité à l’ENS et m’ont fait partager
leur goût pour les Mathématiques... Des remerciements particuliers vont à ceux qui ont
encadré mes mémoires ou thèse : Grégory Miérmont, Lorenzo Zambotti et Uwe Franz.

Chapitre 1
Une théorie des probabilités
non commutatives
1.1 Introduction
Nous allons briévement réintroduire le concept de probabilités non-commutatives.
L’idée de base est que pour un espace de probabilités "classique" (Ω,F,P),
l’ensemble des variables aléatoires forment une algèbre qui est bien sûr com-
mutative. On cherche alors à définir une théorie des probabilités sur une
algèbre qui n’est plus forcément commutative. On peut ainsi donner une
première définition :
Définition 1 On appelle espace de probabilité non commutatif un couple
(A, τ)où Aest une algèbre unitaire et τune forme linéaire unitaire.
Citons deux exemples de tels espaces :
– L’ensemble des variables aléatoires réelles "classiques" sur Ω, muni
de l’espérance, est un espace de probabilités non-commutatif (c’est
normal, on l’a défini pour cela !).
– On prend A=Mn(L∞− (Ω)), l’algèbre des matrices dont les coeffi-
cients sont des variables aléatoires ayant tous leurs moments de tous
ordres finis et on le munit de la forme
τ(M) = 1
nE[T r (M)]
.
Remarque 1 Selon le cas, on peut imposer de la structure supplémentaire
sur A. On peut ainsi définir :
– un espace de probabilité non commutatif et involutif si on impose qu’il
existe une involution ∗sur Aet que τ(XX∗)est positif (ou nul).
1

– un C∗-espace de probabilité si on impose que Aest une C∗-algèbre (et
que τest continue et vérifie la proprieté de positivité précédente)
– un W∗-espace de probabilité si on impose que Aest une algèbre de von
Neumann et τvérifie les propriétés précédentes.
On peut en plus montrer que si Xest un élément auto-adjoint d’un des
espaces définis précédemments, alors il a une "loi au sens classique", c’est-
à-dire qu’il existe une mesure de probabilité µtelle que pour tout kentier :
τXk=Zxkdµ (x)
Remarque 2 Rappelons rapidement ici, pour éclairer les définitions qui
viennent d’être données, ce que l’on entend par des C∗-algèbres et des W∗-
algèbres :
Une C∗-algèbre est une algèbre normée munie d’une involution, notée ∗, et
telle que pour tous Xet Yde A:||XY || ≤ ||X||||Y||,||X∗|| =||X||,||XX∗|| =
||X||2
Il se trouve que l’on peut toujours voir une telle algèbre comme une sous-
algèbre de B(H), algèbre des opérateurs bornés sur un certain espace de
Hilbert, via ce que l’on appelle la constructionde Gelfand-Naimark-Segal, ou
GNS en abrégé.
Soit Aune sous-algèbre de B(H), alors on dit que Aest une algèbre de von
Neumann si elle est fermée pour les semi-normes :
X7→ | < ζ, Xη > |, ζ, η ∈H
On peut alors définir une notion analogue à celle de l’indépendance dans le
cas classique. On l’appellera ici la liberté.
Définition 2 Soient A1et A2des sous-algèbres de A. On dira que A1et
A2sont libres si pour tout n∈N, tout X1,...Xntel que :
– Pour tout i∈ {1, . . . , n},τ(Xi)=0
– Pour tout i,Xiest pris dans Ajiavec j16=j26=. . . 6=jn
Alors :
τ(X1. . . Xn)=0
Remarque 3 On remarque que si A1et A2sont libres, alors on connait la
valeur de τsur le produit libre 1des deux algèbres simplement en la connais-
sant sur chacune d’elles. En effet, pour X∈A1, Y ∈A2:
τ(XY ) = τ((X−τ(X)) (Y−τ(Y))) + τ(X)τ(Y)
1. Sans vouloir rentrer dans les détails techniques de la définition du produit libre de
deux algèbres unitaires, on peut intuitivement considérer la chose comme l’ensemble des
combinaisons linéaires de mots de longueurs quelconque formés à partir des éléments des
deux algèbres et en identifiant les unités respectives.
2
 6
7
8
9
10
11
12
13
14
6
7
8
9
10
11
12
13
14
1
/
14
100%