BoostMySales - WordPress.com

Documentation Technique
BoostMySales
Stage
Page 1 sur 41
Dossier d’études
techniques
BoostMySales
Présenté par
David Bonnet
Yannis Machouri
Maxime Couteau
Stanislas Leduc
Pierre Freneau
Stage de 2ème année BTS Services Informatiques aux Organisations
option SLAM - 14 janvier 2013 – 1er mars 2013
Stage effectué à
BoostMySales
Immeuble le Mercure
10, Rue Gaëtan Rondeau
44 200 Nantes

Documentation Technique
BoostMySales
Stage
Page 2 sur 41

Documentation Technique
BoostMySales
Stage
Page 3 sur 41

Documentation Technique
BoostMySales
Stage
Page 4 sur 41
Remerciements
Nous tenons à remercier avant tout notre tuteur de stage Mr
Nabil Belcaid Le Guyader ainsi que son frère Mr Ali Belcaid pour leur
patience ainsi que pour leurs compétences dans leur domaine
spécifique.
Nous remercions également nos professeurs d’informatique Mr
Bourgeois et Mr Beauvais qui nous ont accompagnés et suivis
pendant toute la durée de notre stage.
Nous exprimons également notre reconnaissance au professeur
d’informatique Mr Gaddhar qui nous a aidé à trouver ce stage ainsi
que pour son soutien tout au long du projet.

Documentation Technique
BoostMySales
Stage
Page 5 sur 41
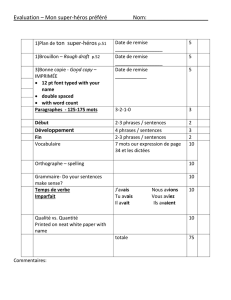
Tables des matières
Introduction
1.1. Installation du serveur ……………………………………………………………...6
I. Prérequis
II. Installation de HBase 0.90.6
III. Installation de Nutch 2.1
IV. Installation de TomCat
V. Installation de Solr 4.0
VI. Intégration de Solr à Nutch
1.2. Installation de Grails.……………………………………………………………....11
I. Qu’est ce que Grails ?
II. Installation
1.3. Développement d’une interface de tests…………………………………12
I. Pourquoi une interface de tests ?
II. Captures d’écrans et extraits de codes
1.4. Intégration de Tika…………………………………………………………………15
I. Qu’est ce que Tika ?
II. Implémentation de Tika dans Nutch
III. Essais et tests de Tika
1.5. Création de la base MySQL………………………………………………………18
I. Création des tables pour stocker les paramètres de Nutch
II. Contenus des tables
1.6. Intégration de Nutch, HBase dans Grails…………………………………24
I. Définition et exécution d’un crawl
II. Visualisation d’un crawl
Conclusion………………………………………………………………………………………..36
Ressources………………………………………………………………………………………..37
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
1
/
41
100%