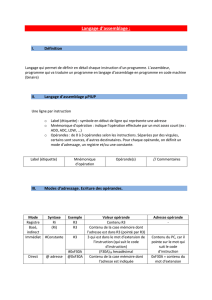
Un micro-processeur 32 bits


r0, . . . , r15
sp
i0, i1, i2
o0, o1, o2
pc
f
max
1 + max sp

z o
o
a b
c
a z o
f
z o
f
b c
b c z
b c o
b c f

a
b z
z c
c z ∨z0→z
z∧z0→z
z0
sp
pc
(v−v)

o1
o2a0, a1, . . . , a5
d0d1
o1o2
a0a1d0a2a3d1a4a5
a0, a1, . . . , a5d0
a1a2d1a3a4
b0, b1, . . . , b6
b6
b4b5
b3
b1b2
b0
i1
 6
7
8
9
10
11
12
13
14
15
6
7
8
9
10
11
12
13
14
15
1
/
15
100%