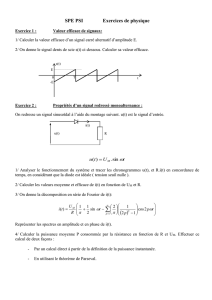
méthode de segmentation automatisée de signaux aléatoires

UNIVERSITE D’ANGERS
ISTIA
ECOLE DOCTORALE D’ANGERS
2006
Master 2 Recherche
Spécialité : Systèmes Dynamiques et Signaux
Présenté par
Jérôme SEVERINI
à l’ISTIA - Université d’Angers
MÉTHODE DE SEGMENTATION
AUTOMATISÉE DE SIGNAUX
ALÉATOIRES
Responsable de stage : François Chapeau Blondeau
Laboratoire : LISA EA4014 - Université d’Angers
62, avenue Notre Dame du Lac - 49000 Angers

REMERCIEMENTS
Qu’il me soit permis de remercier tout dabord Mr le directeur J.L FER-
RIER pour mavoir donné loccasion de réaliser mon stage de master recherche
au sein du LISA, mais aussi mon maître de stage Mr François CHAPEAU
BLONDEAU , pour le temps quil m’a consacré ainsi que pour ces nombreux
conseils.
De même, je remercie tout les doctorants du LISA pour leur patience,
leur soutient ainsi que pour laide quils ont su me donner lorsquelle était
nécessaire.
2

RÉSUMÉ
Une nouvelle méthode de segmentation automatisée de signaux aléatoires
est présentée dans ce document. Cette méthode se compose d’un critère pro-
babiliste principal, la longueur de code d’un signal, et d’un critère d’arrêt de
segmentation. La longueur de code permet de connaître le nombre de bits
par symbole nécessaire au codage d’un signal. Quant au critère d’arrêt, il est
mis en place à partir de l’observation du comportement du gain de longueur
de code des signaux inhomogènes et homogènes.
Cette méthode est tout d’abord appliquées sur des signaux synthétiques
afin d’en définir les limites de fonctionnement. Elle est par la suite appli-
quée sur des signaux réels que sont les indices financiers et les séquences
génomiques afin de juger de son efficacité.
3

Table des matières
I Introduction 5
II Élaboration de la méthode de segmentation 8
1 Principe de base la méthode 9
2 Estimation et codage d’un signal 11
2.1 La longueur de code minimum des données . . . . . . . . . . . 11
2.2 L’estimation et codage des paramètres . . . . . . . . . . . . . 12
2.2.1 Estimation des paramètres . . . . . . . . . . . . . . . . 12
2.2.2 Codage des paramètres . . . . . . . . . . . . . . . . . . 13
3 Observation du gain de longueur de code 14
3.1 Les signaux inhomogènes . . . . . . . . . . . . . . . . . . . . . 14
3.2 Les signaux homogènes . . . . . . . . . . . . . . . . . . . . . . 18
4 Élaboration du critère d’arrêt de segmentation 20
5 Application sur des signaux synthétiques 22
5.1 Application sur une concaténation de 2 signaux . . . . . . . . 22
5.2 Application sur une concaténation de N signaux . . . . . . . . 26
III Application de la méthode sur des signaux réels 31
1 Application sur des indices financiers 32
2 Application sur des séquences génomiques 37
IV Conclusion 41
4

Première partie
Introduction
5
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
1
/
43
100%