Modélisation et prédiction de structure de protéines: une introduction

Modélisation et prédiction
de structure de protéines:
une introduction

Glycolyse . Transport d'oxygène . Capture d'énergie lumineuse . Pompage d'ions .
Métabolisme des acides aminés . Synthèse d'ARN. Transport de métabolites .
Motilité cellulaire . Photosynthèse . Transport d'ions . Synthèse d'ATP . Synthèse
d'acides gras . Cycle de Krebs . Cytosquelette . Respiration . Synthèse de sucres .
Mort cellulaire. Contraction musculaire . Croissance des tissus . Répertoire
immunitaire. Maturation d'ARN. Synthèse de lipides. Anticorps . Traduction du
code génétique. Réplication d'ADN . Capsides virales . Cheveux . Inflammation
Coagulation . Signalisation . Répression de gènes . Gluconéogénèse. Hormones .
Dégradation d'aliments . Neurotransmission . Oxidoréduction . Bioluminescence .
Réparation d'ADN . Synthèse de protéines . Thermogénèse . Fusion cellulaire.
Détoxification . Compaction d'ADN . Chaperones . Catabolisme ADN/ARN .
Transport vésiculaire . Maturation protéique . Choc thermique . Épissage .
Transport nucléaire . Fuseau mitotique . Communication cellulaire . Homéostase .
Neurotoxines et biodéfense . Biosynthèse d'acides aminés . Sécrétion . Cycle de
l'urée . Biosynthèse de nucléotides . Recombinaison génétique . Chimiorécepteurs
. Transport de protéines . Moteurs . Intégration du métabolisme . Neurotoxines .
Biosynthèse d'hormones . Tissus connectifs . Dégradation d'antibiotiques . Vision

Séquence Structure
Fonction
A
U
G
C
G
C
U
U
A
U
A
G
C
C
A
A
G
G
:
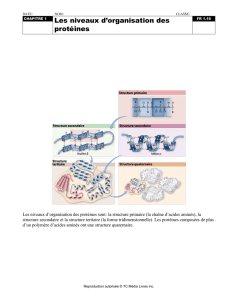
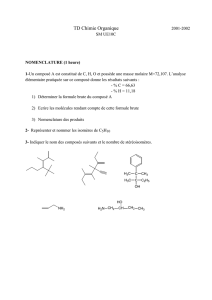
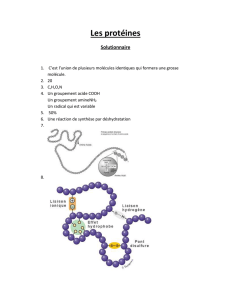
Ingénierie de la structure et fonction des biomolécules

● Organisation structurale et stabilité des protéines
● Prédiction de structure secondaire
● Modélisation moléculaire, dynamique moléculaire
● Prédiction de structure 3D: modélisation par homologie

Le problème du repliement
la structure native est un minimum d'énergie libre
K
L
H
G
G
P
M
L
D
S
D
Q
K
F
W
R
T
P
A
A
L
H
Q
N
E
G
F
T
Nétats ~ 3n
n = 100-300 Googols...
Un acide aminé possède 3 conformations; un polypeptide de longueur n
en possède... 3n. Et pourtant, il se replie en un temps très court (10-6 – 1 s).
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
1
/
72
100%