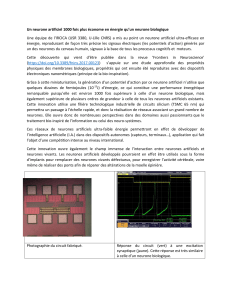
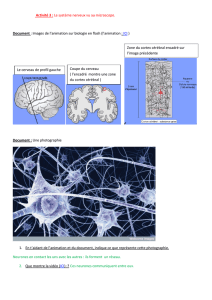
Les réseaux de Kohonen

DIC9310-7
Les réseaux à apprentissage compétitif :
1. Les réseaux de Kohonen

Introduction
L’apprentissage compétitif permet la spécialisation sélective des
neurones pour apprendre les vecteurs stimuli.
Dans sa forme extrême, l’apprentissage avide, un seul neurone par
essai d’apprentissage voit ses poids synaptiques mis à jour, celui avec
la grande activation.
Deux architectures majeures utilisent l’apprentissage compétitif
1
o Les réseaux de Kohonen utilisent une approche d’apprentissage
qui préserve la topologie de l’espace d’apprentissage dans le
réseau final
o Les réseaux ART (« Adaptive Resonnance Theory ») apprennent
en identifiant de formes non connues auparavant.
Dans tous les réseaux, c’est la compétition entre neurones qui
détermine la ou les unités soumises à l’adaptation des poids.
L’apprentissage conséquent peut être supervisé (CPN et LVQ - voir
plus loin) ou non supervisé (SOM et ART).
o Dans l’apprentissage non supervisé, ce sont les « régularités »
dans les patrons d’apprentissage qui permettent d’associer ces
derniers avec certains neurones.
1
Un troisième type de réseau, le CPN (Counter Propagation Network) utilise aussi l’apprentissage
compétitif, mais est vu comme reprenant des caractéristiques des deux architectures principales.

Les réseaux de Kohonen
Développés par Teuvo Kohonen de l’Université d’Helsinki dans les années 70-80
S’inspirent de l’organisation du cortex cérébral où les zones réceptrices sont
organisées suivant une topologie qui respecte celle des récepteurs sensoriels.
o Des zones physiquement proches dans le cortex visuel correspondent à des zones qui le
sont aussi dans la rétine; des neurones proches dans le cortex auditif détecteront des
fréquences voisines.
o On a observé dans le cortex l'existence au niveau des cortex moteur et sensoriel de
cartes somatotopiques qui traduisent la surface sensorielle superficielle du corps.
Le détail de l’organisation n'est pas uniquement d’origine génétique, mais
résulte aussi d'un développement faisant suite à des phases d'apprentissages.
L'homoncule : la surface occupée au niveau cortical est fonction de la sensibilité sensorielle ou
précision motrice de la partie du corps correspondante. Ainsi, la surface occupée par le pouce est
supérieure à celle de la cuisse (arrangement spatial optimal). D'autre part, la topologie est
conservée : les doigts sont l'un à coté de l'autre, etc.
Comment une telle représentation peut-elle se bâtir dans le cortex ?
Comment peut-être se réaliser sans l’aide d’un « professeur »?
Kohonen à proposé plusieurs modèles de RNA pour répondre à ces questions,
en particulier la carte auto-organisatrice qui tente de reproduire l'organisation
topologique des stimuli appliqués au réseau pendant l’apprentissage.

Trois types d’architectures de réseau:
o « Le chapeau mexicain »
o Les cartes auto-organisatrices (« Self-Organizing Maps » ou SOM)
o La quantification vectorielle par apprentissage (« Learning Vector
Quantization » ou LVQ)
Le chapeau mexicain et le SOM utilisent un apprentissage non supervisé, le LVQ
un apprentissage supervisé.
Le LVQ est destiné à des applications de classification, alors que les deux premiers
servent aussi bien à des fins d’association que de classification. Ils sont
particulièrement adaptés aux applications ou les données montrent une cohésion
spatiale ou temporelle.
Apprentissage
La mise à jours des poids synaptiques se fait de manière à rapprocher le vecteur des
poids du prototype à apprendre, ou l’en éloigner dans LVQ.
La distance
),( wxd
entre un vecteur d’apprentissage
x
et un vecteur poids
w
décide des neurones à mettre à jour. À la fin de l’apprentissage cette distance est
idéalement réduite à zéro pour le ou les neurones qui reconnaissent le vecteur
x
.
On a la règle d’apprentissage suivante pour un neurones j, à une itération donnée :
.)(1
.)(.)(.)(
précwx
précwxprécwnouvw
j
jjj
Donc, l’écart entre
x
et
w
sert à l’adaptation des poids synaptiques. La sélection du
neurone j se fait en prenant celui qui a la plus petite distance (euclidienne au autre)
entre le vecteur des poids et le vecteur d’apprentissage.
Si les vecteurs
x
et
w
sont normés et que le carré de la distance euclidienne est utilisé pour
mesurer la distance qui les sépare, on peut remplacer la distance par le produit scalaire des
vecteurs. En effet, on a :
xwwxwx t 2|||||||||||| 222
On peut voir d’après cette équation que si on les vecteurs
x
et
w
sont de longueurs constantes,
l’évaluation de la distance entre eux revient à calculer leur produit scalaire. Noter que dans ce cas,
le calcul de la distance est une forme de calcul du niveau d’activation d’un neurone, où le terme
22 |||||||| wxb
joue le rôle d’un biais ajouté.

Le chapeau mexicain ou réseau à inhibition latérale
Imite le mécanisme d’inhibition latérale observé dans le système visuel.
o On organise les poids synaptiques de manière à ce que chaque
neurone projette des connections excitatrices vers ses voisins
immédiats, des connections inhibitrices plus loin, et des connections
nulles plus loin encore.
Typiquement, chaque neurone possède deux rayons de voisinage R1 et R2
avec des connections excitatrices dans R1 et inhibitrices entre R1 et R2.
o Afin de simplifier les calculs, les poids des deux types de
connections prennent des valeurs constantes.
o On a donc une fonction d’activation de la forme
1
1
..
1
2
2
1
1
1
)()()()1( R
Rk
R
Rk iiinh
R
Rk iexciti kxkxWkxWfkx
f est une fonction en rampe qui va de 0 à xmax
Le choix des poids est fait à priori et les mêmes valeurs sont utilisées
pour tous les neurones.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
1
/
25
100%