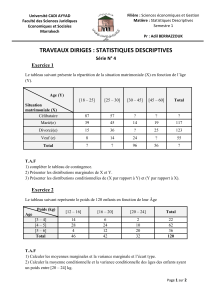
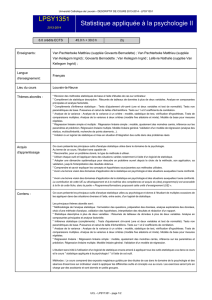
Modèles de régression linéaire : Cours de statistique appliquée
Telechargé par
Lahouel Noureddine

Master Statistique Appliquée
Mention Statistique pour l’Entreprise
Modèles de régression linéaire
Magalie Fromont Renoir


Table des matières
1 Le modèle de régression linéaire simple 7
1.1 Introduction...................................... 7
1.2 De très nombreux exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.2.1 Exemples historiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.2.2 Prix et consommation de tabac . . . . . . . . . . . . . . . . . . . . . . . 8
1.2.3 Consommation d’alcool et espérance de vie par pays . . . . . . . . . . 8
1.2.4 Qualité de l’air en Bretagne . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.2.5 Hauteur des eucalyptus . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.3 Modèle de régression linéaire simple . . . . . . . . . . . . . . . . . . . . . . . . 10
1.3.1 Formulation analytique . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.3.2 Formulation vectorielle . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.4 Estimation (ponctuelle) et prédiction dans le cas général . . . . . . . . . . . . 11
1.4.1 Estimation ponctuelle des cœfficients de régression . . . . . . . . . . . 11
1.4.2 Estimation ponctuelle de la variance, valeurs ajustées et résidus . . . . 14
1.4.3 Le cœfficient de détermination R2..................... 15
1.4.4 Prédiction ................................... 15
1.4.5 Ecritures matricielles et interprétations géométriques . . . . . . . . . . 16
1.5 Inférence sous hypothèse gaussienne . . . . . . . . . . . . . . . . . . . . . . . . 18
1.5.1 Estimateurs du maximum de vraisemblance . . . . . . . . . . . . . . . 18
1.5.2 Intervalles et régions de confiance pour les cœfficients de régression . 19
1.5.3 Tests d’hypothèses sur β0.......................... 19
1.5.4 Tests d’hypothèses sur β1.......................... 20
1.5.5 Intervalles de confiance et tests d’hypothèses sur la variance . . . . . . 20
1.5.6 Intervalles de prédiction . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.6 Exercices........................................ 21
2 Le modèle de régression linéaire multiple 27
2.1 Introduction : retour sur les exemples . . . . . . . . . . . . . . . . . . . . . . . 27
2.2 Modélisation...................................... 27
2.3 Exemples de modèles de régression linéaire multiple . . . . . . . . . . . . . . 28
2.3.1 Variables explicatives quantitatives . . . . . . . . . . . . . . . . . . . . 28
2.3.2 Transformations de variables explicatives quantitatives . . . . . . . . . 29
2.3.3 Variables explicatives qualitatives . . . . . . . . . . . . . . . . . . . . . 29
2.3.4 Interactions .................................. 29
2.4 Estimateur des moindres carrés ordinaires . . . . . . . . . . . . . . . . . . . . . 29
2.5 Valeurs ajustées, résidus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3

Table des matières
2.6 Somme des carrés résiduelle et estimation ponctuelle de la variance . . . . . . 32
2.7 Equation d’analyse de la variance, cœfficient de détermination . . . . . . . . . 32
2.8 Prédiction ....................................... 32
2.9 Estimation par intervalles de confiance et tests d’hypothèses asymptotiques . 33
2.9.1 Théorèmeslimites .............................. 33
2.9.2 L’idée du bootstrap non paramétrique . . . . . . . . . . . . . . . . . . . 33
2.10Exercices........................................ 35
3 Le modèle de régression linéaire multiple sous hypothèse gaussienne 39
3.1 Introduction...................................... 39
3.2 Estimateurs du maximum de vraisemblance . . . . . . . . . . . . . . . . . . . 40
3.3 Loisdesestimateurs ................................. 40
3.4 Intervalles et régions de confiance pour les paramètres - Intervalles de prédiction 41
3.4.1 Intervalles et régions de confiance pour les cœfficients de régression . 41
3.4.2 Intervalles de confiance pour la variance σ2................ 42
3.4.3 Intervalles de prédiction . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.5 Tests d’hypothèses sur les cœfficients de régression . . . . . . . . . . . . . . . 42
3.5.1 Test de nullité d’un cœfficient ou de (non) significativité d’une variable
explicative................................... 42
3.5.2 Tests d’hypothèses linéaires sur les cœfficients.............. 43
3.5.3 Test du rapport de vraisemblance maximale . . . . . . . . . . . . . . . 43
3.6 Exercices........................................ 47
4 Détection (et correction) des écarts au modèle 53
4.1 Introduction...................................... 53
4.2 Analysedesrésidus.................................. 54
4.2.1 Les différentsrésidus............................. 54
4.2.2 Détection des écarts au modèle . . . . . . . . . . . . . . . . . . . . . . . 55
4.2.3 Donnéesaberrantes.............................. 56
4.3 Analyse de la matrice de projection, effetlevier.................. 56
4.3.1 Propriétés de la matrice de projection . . . . . . . . . . . . . . . . . . . 56
4.3.2 Effetlevier................................... 57
4.4 Mesuresd’influence.................................. 57
4.4.1 DistancedeCook............................... 57
4.4.2 Distance de Welsh-Kuh (DFFITS) . . . . . . . . . . . . . . . . . . . . . . 58
4.5 Correction des écarts au modèle . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.5.1 Ajout d’une variable explicative . . . . . . . . . . . . . . . . . . . . . . 58
4.5.2 Transformation des variables . . . . . . . . . . . . . . . . . . . . . . . . 59
4.5.3 Cas particulier d’hétéroscédasticité : Moindres Carrés Généralisés . . . 59
4.6 Exercice : Compléments /questions de cours . . . . . . . . . . . . . . . . . . . 60
5 Sélection de variables 63
5.1 Introduction...................................... 63
5.2 Critères de qualité d’un modèle . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
5.2.1 Qualité de l’estimation, erreur quadratique moyenne (EQM) . . . . . . 64
5.2.2 Qualité de la prédiction, erreur quadratique moyenne de prédiction
(EQMP) .................................... 64
4

Table des matières
5.3 Critères de sélection de variables . . . . . . . . . . . . . . . . . . . . . . . . . . 65
5.3.1 Cadre général (conditions standards) . . . . . . . . . . . . . . . . . . . 65
5.3.2 Cadregaussien ................................ 66
5.4 Liens entre les différentscritères .......................... 68
5.4.1 R2
aet test de validité de sous-modèle . . . . . . . . . . . . . . . . . . . . 68
5.4.2 Cpet test de validité de sous-modèle . . . . . . . . . . . . . . . . . . . . 68
5.4.3 Critères de vraisemblance pénalisée et test de validité de sous-modèle 68
5.5 Méthodes algorithmiques de sélection . . . . . . . . . . . . . . . . . . . . . . . 68
5.5.1 Méthode de recherche exhaustive . . . . . . . . . . . . . . . . . . . . . 68
5.5.2 Méthode de recherche descendante (backward) . . . . . . . . . . . . . 68
5.5.3 Méthode de recherche ascendante (forward) . . . . . . . . . . . . . . . 69
5.5.4 Méthode de recherche progressive (stepwise) . . . . . . . . . . . . . . . 69
5.6 Exercices ........................................ 69
6 Annales corrigées 73
6.1 Examenspartiels ................................... 73
6.1.1 Sujet 1 (durée : 1h30) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
6.1.2 Sujet 1 : éléments de correction . . . . . . . . . . . . . . . . . . . . . . . 77
6.1.3 Sujet 2 (durée : 1h30) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
6.1.4 Sujet 2 : éléments de correction . . . . . . . . . . . . . . . . . . . . . . . 83
6.1.5 Sujet3(durée:2h) .............................. 85
6.1.6 Sujet 1 - Éléments de correction . . . . . . . . . . . . . . . . . . . . . . . 91
6.2 Examensterminaux.................................. 94
6.2.1 Sujet1(durée:3h) .............................. 94
6.2.2 Sujet 1 - Éléments de correction . . . . . . . . . . . . . . . . . . . . . . . 100
6.2.3 Sujet2(durée:3h) .............................. 104
6.2.4 Sujet 2 : Éléments de correction . . . . . . . . . . . . . . . . . . . . . . . 109
6.2.5 Sujet 2 bis (durée : 2h) - Entraînement . . . . . . . . . . . . . . . . . . . 113
6.2.6 Sujet3(durée:2h) .............................. 117
6.2.7 Sujet 3 : Éléments de correction . . . . . . . . . . . . . . . . . . . . . . . 123
5
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
1
/
127
100%