6 - Notions de base en statistique

Notions de base en statistique
Dr Cécile Couchoud

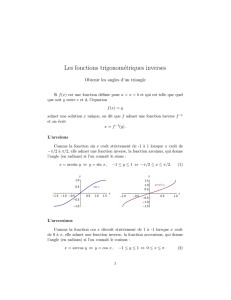
Démarche déductive
« Vraie » valeur prévoir la valeur sur un
échantillon futur < fluctuations d’échantillonnage
Intervalle de fluctuation
Formule générale :
A +/- z α/2 √varΑ
A: moyenne du paramètre
α: risque d’erreur que l’on consent (5%)
z α/2 : donné par la table de la loi normale centrée
réduite
√varΑ: variance du paramètre

Démarche inductive
Valeur observée sur un échantillon : Estimation
ponctuelle p0
Estimation par intervalle : intervalle de confiance
p0+/- z α/2 √var p0
Interprétation : pour α=5%, z α/2 = 1.96
« sur 100 échantillons successifs pris dans la
population, 95 (en moyenne) conduisent à un
intervalle de confiance qui contient le vrai
pourcentage »

Quelques exemples de variances
Prévalence : Var(p0) = p0.(1-p0)/n
Taux d’incidence :
Var (TI) = m / PA²
Moyenne : Var (m) = s² / n
Odds ratio :
Var (LnOR) = 1/a+1/b+1/c+1/d

Étapes d’un test statistique
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
1
/
46
100%