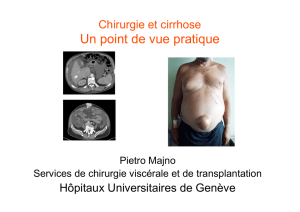
exemple


2/59
Plan
1Indexation/ImplantationdesOpérateurs/Calculdecoût✔
2RappelsJDBC/ImpedanceMismatch/JPA&Hibernate✔
3XML:Généralités,langageXPath
3.1Introduction
3.2XML
3.3Validationdedocuments
3.4Modèled'arbre
3.5XPath,introduction
3.6Évaluationdesprédicats
3.7Axescomplexes
3.8Syntaxeabrégée

3/59
Qu'est-cequeXML?
XML (eXtensible Markup Language) est un standard de représentation de
données
Conçu pour être lisible par un humain, mais traitable simplement par les
machines
Permetlareprésentationdedonnéesimbriquées
Estnormalisé(parleW3C)
Typé(notiondeschématrèsfine)

4/59
Ena-t-onbesoin?
Quelssontlesautresmoyendereprésenterlesdonnées?
Tablerelationnelle
Fichierstextesnonstructurés
Formatbinaires
ad-hoc
Quelssontlesdésavantagesdesreprésentationsci-dessus?
Nonéchangeable(ilfautfaireun
dump
delabase),contraintessimples
Lisible,maissansstructuredoncdifficilementutilisableparunprogramme,
pasdeschéma
Liéàuneutilisationparticulière

5/59
Historique
Findesannées1980:SGMLadoptépourlapublicationdemédia
Milieudesannées1990:ungroupedetravailcommenceàétudierl'utilisation
deSGMLpourleWeb(quidébutait)
1998:XML1.0devientunerecommandationduW3C
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
1
/
59
100%