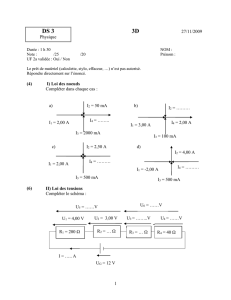
PROJET DE FIN D`ETUDE Le DIPLÔME d`INGENIEUR

PROJET DE FIN
D’ETUDE
présenté pour obtenir
Le DIPLÔME d’INGENIEUR et MATER 2
RECHERCHE
de SUPELEC et l’UNIVERSITE PAUL VERLAINE
par
Abdelmounaim Lokman ABBAS-TURKI
SUJET:
Monte Carlo sur GPU
Encadrants :
Bernard Lapeyre Enseignant chercheur au CERMICS, ENPC
Renaud Keriven Directeur du CERTIS, ENPC
Septembre 2007


Aux deux femmes qui
ont rempli mon coeur
d’amour et d’affection.


Remerciements
Mes premiers remerciements vont à Monsieur Bernard Lapeyre, d’une part, de m’avoir
proposé un sujet que j’ai énormément aimé pour sa richesse scientifique théorique et ap-
pliquée et, d’autre part, pour ses conseils avisés, son aide et sa confiance continue en mon
travail.
Je remercie aussi très chaleureusement Monsieur Renaud Keriven qui a rendu, lui et
son équipe, mon travail tellement agréable que j’ai eu l’impression de passer mes meilleures
vacances avec eux.
Ce travail a été effectué au CERMICS et principalement au sein de l’équipe du CER-
TIS. Que tous les membres de ces départements trouvent ici l’expression de ma gratitude,
en particulier Monsieur Jean-François Delmas et Alexandre Chariot. Leur gentillesse
et leur disponibilité ont grandement contribué à rendre ma tâche facile et mon séjour
agréable.
Je tiens également à remercier Messieurs Stéphane Vialle, Olivier pietquin et Michelle
Barret d’avoir suivi l’état d’avancement de mon travail et de me faire l’honneur d’assister
à ma soutenance.
Je suis très reconnaissant à tous les enseignants que j’ai eus durant mes dix-sept années
d’étude et de formation, sans lesquels ce mémoire n’aurait pas eu son contenu actuel.
Le travail modeste que je présente n’est qu’une goutte dans l’océan de savoir détenu
par des chercheurs d’exception comme Messieurs Knuth, Niederreiter, Fishman et tant
d’autres. Qu’ils trouvent ici l’expression de ma reconnaissance envers leur travaux de très
hauts niveaux scientifique.
Enfin, on dit souvent que l’on ne choisit pas ses parents. En ce qui me concerne, si
j’avais à le faire, j’aurais certainement retenu les miens. Qu’ils trouvent en moi l’enfant
redevable toute sa vie.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
1
/
97
100%