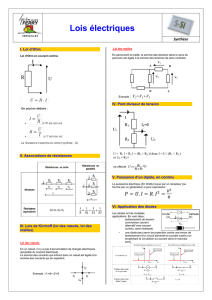
Objectifs - RepMus

..
&,
be]e[jYekb[khi
Wffb_YWj_edi[jZYb_dW_iedi
B[iYekb[khiZkbe]e
Kd^X^idjiZhaZhYXa^cV^hdchedhh^WaZh
Yjad\dineZJEB8#
'Yekb[khYehfehWj[F-+&*9
AZad\dineZZcXdjaZjgXdgedgViZ
Zhiji^a^hedjgaVeVeZiZg^Z#
F)/&9
9(&C%@&%%D(
H&-'L&.&8%
F',,9
9%C,-@&%%D%
H'')L-'8+
F-&)9
9,C.*@).D&+
H&-&L*+8,.
FFhe$CW]9
9%C&%%@%D%
H'%.L%8&&+
F9eeb=hWo'&9
9)%C(&@'%D,%
H.,L..8&%&
F-+*,9
9,&C)(@'(D+(
H*,L,)8--
F+-*)9
9*)C')@-+D-&
H+)L,)8)&
F-+)(9
9'(C(+@)(D++
H&%'L-*8,%
F+'/+9
9)*C,)@'&D+(
H&%%L+-8-.
F-+&*9
9&,C(+@),D(-
H&)*L&'%8.&
*Yekb[khiZ[hkfjkh[
F)/&9>F',,9>F-&)9>FFhe$CW]9
AZhÈeZi^ihedcihÉYjad\dineZ
eZjkZciZm^hiZgVjX]d^m!
YVchjcZYZh)XdjaZjghYZgjeijgZ#
+Yekb[khiYecfbc[djW_h[i
F-+)(9>F+'/+9>F+-*)9>F-+*,9>
F9eeb=hWo'&9>
AZad\dineZji^a^hZYZhXdjaZjgh
XdbeabZciV^gZhedjgaZhY^i^dch!
aZhV[ÒX]ZhZiaZhVccdcXZhegZhhZ#
.
MPIL(LI332)
Année 2013/2014
Projet final MPIL
..
Objectifs
1. Structures complexes
2. Parcours d’arbres et de graphes
3. Programmation orientée objet
4. Inter-opérabilité avec C
Le but de ce projet est d’étendre notre librairie de traite-
ments en informatique musicale par OCaml. Nous allons donc
continuer le travail entrepris sur les fichiers MIDI pour passer
à un niveau supérieur de modélisation. Ce projet se basera
donc sur le travail effectué lors du premier mini-projet. Vous
pouvez réutiliser votre propre implémentation des interac-
tions MIDI, ou utiliser le module mis à votre disposition sur la
page http ://repmus.ircam.fr/esling/mpil.html. Vous
disposerez ainsi des fonctions de transformations musicales
de base, mais surtout des deux fonctions essentielles à la
réalisation du projet loadMidi et saveMidi. Nous utiliserons
la même représentation des objets musicaux que celle utilisée
dans le mini-projet.
Le style musical peut être représenté et modélisé par
l’ensemble de successions de notes utilisées par un musicien.
Généralement chaque musicien utilise un ensemble précis de
motifs plus ou moins récurrents. L’idée est donc d’arriver à
capter ces motifs et leur utilisation pour être par la suite
capable de regénérer des mélodies ayant une similarité
avec le style d’un musicien particulier. Dans tout les exer-
cices (sauf le dernier exercice bonus), nous considèrerons
uniquement des mélodies à une voix. Ainsi l’objet musi-
cal prinicipal ne peut être qu’une Sequence qui contiendra
éventuellement des objets Parallel représentant des accords.
Exercice 1 : Structures arborescentes
Pour modéliser (puis plagier) le style musical d’un artiste,
nous allons utiliser des méthodes par dictionnaire utilisant des
structures arborescentes. L’idée est donc de créer des arbres
(n-aires) qui permettent de structurer les répétitions d’une
musique sous forme de liens (d’un nœud vers un autre) entre
les différents motifs musicaux. Chaque motif musical (note,
accord, mélodie) fera donc partie de notre dictionnaire. Nous
allons ici séparer les représentations des nœuds et des arbres,
et également considérer les arbres comme étant un cas parti-
culier de graphe acyclique orienté.
Q.1.1 Définir le type musicalNode sous forme d’une classe,
qui devra contenir
– Un objet musical.
– Une liste de probabilités.
– Un index entier.
– Une liste de nœuds voisins.
Q.1.2 Définir les fonctions permettant d’accéder et modi-
fier les différentes variables de la classe ainsi qu’une fonction
addProba permettant d’ajouter une valeur à la liste de proba-
bilités et une fonction changeProba permettant de modifier
une des valeurs de la liste.
Q.1.3 Définir la fonction isEq permettant de tester si deux
nœuds sont équivalents en termes d’évènements musicaux.
Nous allons représenter les structures arborescentes comme
un cas particulier de graphe.
Q.1.4 Écrire la classe graphList qui définit un graphe comme
– Une liste de nœuds
– Un nombre de nœuds
– Un index indiquant la racine du graphe
Q.1.5 Écrire la fonction addNode (permettant d’ajouter un
nœud au graphe), putEdge (permettant d’ajouter un lien
entre deux nœuds) et getEdge (vérifiant l’existence d’un lien
entre 2 nœuds).
Exercice 2 : Incremental Parsing (IP)
Dans un premier temps, nous allons utiliser une struc-
ture simpliste pour modéliser les motifs musicaux. Nous al-
lons utiliser pour ce faire un des premiers algorithmes ayant
été développé dans ce but. La première question permet de
construire l’arbre représentant le style musical et les suivantes
permettent de le parcourir pour générer des musiques simi-
laires.
Q.2.1 Écrire la fonction constructIPTree qui permet
de construire l’arbre IP à partir d’une séquence musicale.
L’algorithme de construction se fait de la manière suivante
– Construire un arbre vide contenant une racine de proba-
bilité 1.0
– Établir le nœud courant comme étant la racine
– Parcourir la séquence musicale, en effectuant pour
chaque élément elt(i)
– Si le nœud courant contient un fils égal à elt(i)
– Augmenter la probabilité du nœud courant de 1.0
– Le nœud courant devient le fils
– Sinon on crée un nouveau fils (de probabilité 1.0) au
nœud courant puis le nœud courant devient la racine
Q.2.2 Écrire la fonction chooseProbabilistic qui choisit
aléatoirement le fils d’un nœud en fonction des probabilités
de tous ses fils.
Q.2.3 Écrire la fonction chooseContinuation qui parcourt
l’intégralité des nœuds d’un arbre et trouve un nœud égal à
un élément musical donné en paramètre.
Q.2.4 Écrire la fonction computePlagiatIP qui construit
un plagiat en parcourant un arbre IP. L’idée est de par-
tir de la racine avec une séquence musicale vide, puis choi-
sir à chaque fois un fils du nœud courant avec la fonc-
tion chooseProbabilistic. Si le nœud courant n’a pas de
fils, alors on utilise la fonction chooseContinuation avec
comme paramètre l’élement musical courant. A chaque choix
de nœud, on ajoute l’élement musical courant à la séquence.
Le parcours s’arrête lorsqu’on obtient une séquence dont le
nombre de notes dépasse une longueur définie.
Q.2.5 Testez votre fonction de plagiat en générant plusieurs
plagiats que vous sauvegarderez et écouterez au format MIDI.
Exercice 3 : Probabilistic Suffix Tree (PST)
Le gros problème de l’algorithme IP est qu’il n’est capable
de modéliser que le contexte local d’une musique. Ainsi, pour
prendre en compte le contexte global, nous allons utiliser les
Probabilistic Suffix Trees (PST). Cet algorithme se base sur
une structure d’arbre représentant les suffixes d’une séquence.
1

Chaque chemin de l’arbre représente une séquence possible et
chaque nœud contient les probabilités de passer de la séquence
courante à un des éléments de notre dictionnaire. Un exemple
d’arbre PST est présenté dans la figure suivante
.
a r
ca ra
bra
(.2,.2,.2,.2,.2)
(.6,.1,.1,.1,.1)(.05, .5, .15, .2, .1)
(.05, .4, .05, .4, .1)
(.05, .25, .4, .25, .05)
(.1, .1, .35, .35, .1)
ar
cr
b
Pour pouvoir utiliser l’algorithme PST, nous allons donc
devoir utiliser un dictionnaire, que nous allons représenter
sous forme d’une liste de couples (élément, probabilité). Ici la
probabilité d’un élément représente simplement son nombre
d’occurrences dans l’ensemble de la séquence musicale (divisé
par le nombre total d’éléments de la séquence).
Q.3.1 Écrire la fonction computeEmpiricalProbability qui
calcule la probabilité empirique (nombre d’occurrences) d’un
objet musical donné à l’intérieur d’une séquence complète.
Q.3.2 Écrire la fonction computeDictionnary qui calcule
un dictionnaire d’objets musicaux avec leurs probabilités em-
piriques à partir d’une séquence complète.
Q.3.3 Écrire la fonction filterDictionnary qui retourne le
dictionnaire ne contenant que les éléments dont la probabilité
est supérieure à un paramètre donné.
Q.3.4 La subtilité de l’algorithme PST consiste à utiliser les
probabilités des suffixes d’une séquence. Il faut donc écrire
une fonction computeSuffixProbability qui rend la proba-
bilité empirique d’une suite d’objets musicaux, divisée par
la probabilité empirique de cette suite sans son premier élé-
ment.
Q.3.5 Toujours dans l’optique de travailler sur les suffixes
des séquences, on va maintenant devoir créer des chemins de
nœuds depuis la racine (contrairement à la simple création de
nœuds de l’algorithme IP). Coder la fonction addNodePath
qui ajoute à l’arbre un nœud, ainsi que tous les nœuds (si
nécessaires) sur le chemin depuis la racine vers celui-ci.
Q.3.6 Écrire la fonction constructPSTTree qui permet
de construire l’arbre PST à partir d’une séquence musicale.
L’algorithme de construction se fait de la manière suivante
(avec les paramètres pMin,qThresh et maxLen donnés)
– Initialiser l’arbre ne contenant qu’une racine vide
– Initialiser puis filtrer le dictionnaire
– Construire une liste toAnalyze, qu’on remplit avec les
éléments restants du dictionnaire
– Tant que toAnalyze est non vide
– Retirer le premier élément eltAn de toAnalyze
– Ajouter le chemin correspondant à cet élément dans
l’arbre jusqu’au nœud nodeEnd
– Pour chaque élément eD du dictionnaire
– Créer une séquence seqAD en concaténant eltAn et
l’élément du dictionnaire eD.
– Calculer la probabilité suffixe de la séquence seqAD
et l’ajouter au nœud nodeEnd.
– Créer une deuxième séquence seqDA concanténant
eD au début de eltAn
– Si la longueur de seqDA < maxLen, calculer la proba-
bilité complète pComp et la probabilité suffixe pSuff
de la séquence seqDA
– Si pComp > pMin et (pSuff >= qThresh ou pSuff <=
(1 / qThresh)), ajouter seqDA à la liste toAnalyze.
Q.3.7 Implémenter la fonction permettant de parcourir
l’arbre de manière aléatoire pour recréer de nouvelles mélo-
dies dans le même style que l’artiste original. On utilisera la
même fonction de choix probabiliste que pour IP mais cette
fois sur la liste des probabilités de chaque nœud.
Q.3.8 Tester vos fonctions en générant plusieurs plagiats à
partir de différents fichiers MIDI et différents paramètres (que
vous sauvegarderez dans de nouveaux fichiers MIDI).
Exercice 4 : Bonus : Plagieur automatique de
style par graphe (oracle des facteurs)
Après avoir testé l’algorithme PST, vous aurez sûrement
remarqué que les imitations générées ne sont pas toujours
trés convaincantes. En effet, les deux gros problèmes de cette
modélisation sont
– L’analyse génère l’intégralité des séquences possibles
(même celles n’étant pas dans la musique originale)
– Le parcours de l’arbre ne permet aucun retour en arrière
est se cantonne donc à repartir de la racine
L’oracle des facteurs permet de résoudre tout ces pro-
blèmes en utilisant une structure de graphe avec liens suffixes,
qui permet de générer des plagiats extrêmement convain-
cants et réalistes. La structure ainsi que les algorithmes
de création et parcours sont décrits dans l’article suivant :
http ://hal.archives-ouvertes.fr/docs/00/61/98/46/
PDF/9911-sofsem.pdf.
Q.4.1 Écrire les fonctions de création et de parcours de la
structure.
Q.4.2 Tester vos fonctions en générant plusieurs plagiats
à partir de différents fichiers MIDI (que vous sauvegarderez
dans de nouveaux fichiers MIDI).
Exercice 5 : Bonus : Créativité
Maintenant c’est votre tour de nous vendre du rêve ... Ici
le choix est libre sur la créativité et funkyness. Voici un petit
problème ouvert que vous pouvez implémenter absolument
comme vous le souhaitez.
On considère que notre fichier MIDI contient une suite
d’accords, que nous souhaitons orchestrer. L’idée est donc
d’affecter chaque note d’un accord à un instrument différent.
On peut bien évidemment imaginer de tirer au sort les ins-
truments pour avoir un joyeux bordel mais on aimerait être
un peu plus malin ... Donc
1. Comment choisir les notes vers quels instruments
2. Contraintes de continuité d’un accord au suivant
3. Tenir compte de la tessiture des instruments
2
1
/
2
100%