DZ - EQUATIONS DIFFERENTIELLES

DZ - EQUATIONS DIFFERENTIELLES
On a regroupé sous ce titre plusieurs morceaux de cours écrits à des époques diverses et pour des
niveaux divers.
Sommaire
Equations différentielles : généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
Méthodes pratiques de résolution..................................................................7
Equations différentielles linéaires. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .19
Systèmes différentiels linéaires....................................................................33


DZ 3
Partie I - Equations différentielles : généralités
Soit Uun ouvert de Rp, et ]α, β [un intervalle de R. Soit une fonction Fde classe C1sur ]α, β [×U
à valeurs dans Rp. On considère l’équation différentielle :
(E) y′=F(t, y),
Une condition initiale est la donnée d’un couple (t0, y0)de ]α, β [×U.
Résoudre l’équation différentielle (E) avec condition initiale (t0, y0), c’est trouver les couples
( ] a, b [, f ), où ]a, b [est inclus dans ]α, β [et contient t0, la fonction fest de classe C1sur ]a, b [,
et vérifie, pour tout tde ]a, b [, la relation
f′(t) = F(t, f′(t))
avec
f(t0) = y0.
Théorème de Cauchy
Existence Sous les conditions ci-dessus on peut toujours résoudre l’équation différentielle, avec
condition initiale donnée.
Unicité Si ( ] a, b [, f)et ( ] c, d [, g)sont deux solutions de la même équation différentielle avec
la même condition initiale, alors fet gcoïncident sur ]a, b [∩]c, d [.
Solution maximale Il existe un plus grand intervalle ]a, b [, et une fonction fde classe C1sur
]a, b [telle que ( ] a, b [, f )soit solution de l’équation (E) avec condition initiale donnée.
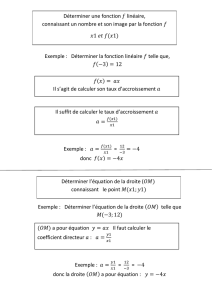
Exemple 1
(E) y′=y
t=F(t, y).
La fonction Fest de classe C1sur R∗×R. Donnons nous (t0, y0)avec t0non nul, et cherchons la
solution maximale.
De manière évidente, les fonctions y=C t sont solutions de l’équation. Il suffit de déterminer la
constante Cen utilisant la relation
y0=C t0.
On obtient
y=y0
t0
t .

DZ 4
Si t0est strictement positif, la solution maximale est donc
( ] 0,∞[, f)où f(t) = y0
t0
t .
Si t0est strictement négatif, la solution maximale est alors
( ] −∞,0 [ , f )où f(t) = y0
t0
t .
Remarquons que dans ce cadre, la solution maximale ne peut “franchir” la valeur t= 0, puisque F
n’est pas définie pour cette valeur.
Si l’on s’intéresse maintenant à l’équation différentielle
(E1)t y′=y ,
qui sort du cadre du théorème, les fonctions y=C t pour une constante Cquelconque, sont solutions
dans Rtout entier de (E1). Mais, si y0est non nul, il n’existe pas de solution de cette équation vérifiant
la condition initiale (0, y0).
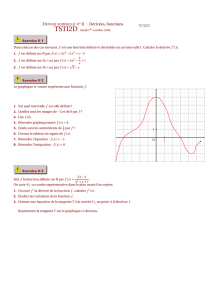
Exemple 2 Considérons l’équation
(E) y′=p1−y2=F(t, y).
La fonction Fest de classe C1sur R×]−1,1 [ .
Donnons nous une condition initiale (t0, y0). Nécessairement y0est dans ]−1,1 [ et donc y0= cos θ0
avec 0< θ0< π.
Soit l’intervalle
I0= ] −π+t0+θ0, t0+θ0[.
On constate que t0appartient à I0. Par ailleurs, si test dans I0alors t−t0−θ0appartient à ]−π, 0 [ ,
et sin(t−t0−θ0)est négatif. Alors si l’on pose sur I0,
f(t) = cos(t−t0−θ0),
on a :
p1−f(t)2=|sin(t−t0−θ0)|=−sin(t−t0−θ0) = f′(t).
On a également
f(t0) = cos(θ0) = y0.
La solution maximale cherchée est donc (I0, f ). (Elle est bien maximale car elle ne peut franchir les
bornes de I0sans devenir égale à 1ou −1).

DZ 5
On pourrait étudier de la même manière l’équation
y=−p1−y2.
Remarquons là aussi que la forme de l’équation est importante. En effet les deux équations précédentes
impliquent
(E) y2+y′2= 1 .
Cette équation a comme solutions
y= cos(t−t0)
quel que soit t0. Elle a également pour solutions y= 1 et y=−1.
Toutes ces solutions sont définies sur Rtout entier. Alors elle possède une infinité d’autres solutions
obtenues en recollant en des points d’ordonnée 1ou −1, des solutions de la première forme. En consé-
quence par un point quelconque (t0, y0)où −1≤y0≤1, il passe une infinité de solutions de (E).
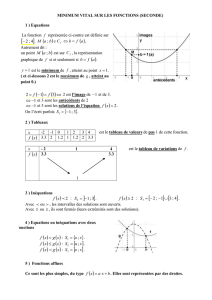
Application du théorème de Cauchy aux équations d’ordre 2
Considérons l’équation différentielle du second ordre
(E) y′′ =G(t, y, y′),
où Gest une application de classe C1de ]α, β [×]α′, β′[×]α′′, β′′ [dans R. Posons
y′=z , Y = (y, z), F (t, Y ) = (z, G(t, y, z))
et
U= ] α′, β′[×]α′′, β′′ [.
La fonction Fest de classe C1sur ]α, β [×Uà valeur dans R2. De plus l’équation (E) équivaut au
système
y′=z
z′=G(t, y, z)
c’est-à-dire à
(y′, z′) = F(t, y, z),
où encore à
Y′=F(t, Y ).
Résoudre l’équation (E) revient donc à trouver une fonction fde classe C1sur un ouvert de R2telle
que
f′(t) = F(t, f(t)) .
Le théorème de Cauchy s’applique dans ce cas. En particulier une condition initiale est un couple
(t0, Y0)tel que
f(t0) = Y0= (y0, z0) = (y(t0), z(t0)) ,
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
1
/
39
100%