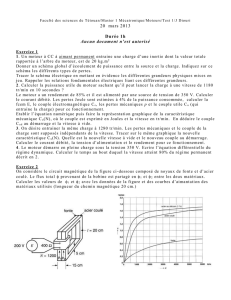
retro3

85
J. AKOKA &I.WATTIAU
Conceptualisation : illustration
•PERSON (ssn, name, address)
•EMPLOYEE(ssn, name, salary, hired-date)
•MANAGER(ssn, rank, promotion-date, deptno)
•CUSTOMER(ssn, custid, name, credit)
•DEPARTMENT(deptno, dept-name, location)
•PRODUCT(pronum, description)
•PRICE(pronum, minprice, maxprice)
•ORDER(ordid, order-date, prodid, custid)
•CARRIER(carrier-id, name, address)
•PROJECT(pronum, deptno, budget)
•WORK-FOR(ssn, deptno, start-date)
•CAN-PRODUCE(deptno, pronum, unit-cost)
•SHIPMENT(pack#, ordid, ship-date, carrier-id).
Le schéma
relationnel
initial

86
J. AKOKA &I.WATTIAU
Etape 1 :
- identification des entités PERSON, EMPLOYEE, MANAGER,
CUSTOMER, DEPARTMENT, PRODUCT, PRICE et ORDER.
-suspicion d’homonymes ou d’héritages entre les clés de PERSON,
EMPLOYEE, MANAGER et CUSTOMER d’une part et PRICE et
PRODUCT d’autre part.
-recherche d’un identifiant pour la table relationnelle CARRIER

87
J. AKOKA &I.WATTIAU
Résultat de la première étape :
les lignes discontinues représentent les homonymes ou les liens de
généralisation soupçonnés :
PERSON
EMPLOYEE MANAGER
CUSTOMER
PRICE
PRODUCT
DEPARTMENT
ORDER

88
J. AKOKA &I.WATTIAU
Etape 2 :
•Confirmation des relations d’inclusion suivantes
PERSON EMPLOYEE MANAGER et PERSON
CUSTOMER
•Infirmation des autres
•Présomption d'associations entre entités :
- EMPLOYEE (ou MANAGER ou CUSTOMER ou PERSON) et
DEPARTMENT ,
- deux associations entre DEPARTMENT et PRODUCT ,
- une association 1-1 entre PRICE et PRODUCT,
- deux associations entre DEPARTEMENT et PRICE,
- ORDER et une entité à déterminer
•Confirmation de Carrier-id comme identifiant de la table CARRIER

89
J. AKOKA &I.WATTIAU
Résultat de la deuxième étape :
(les ovales représentent des associations et les flèches des liens de
généralisation) :
PERSON
EMPLOYEE
MANAGER
CUSTOMER
PRICE
PRODUCT
DEPARTMENT
ORDER
work-for
project
can-produce
? ?
??
? ?
1
1
shipment
?
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
1
/
55
100%