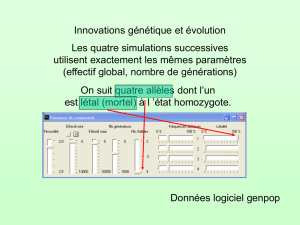
+ p

Deuxième partie de la première journée
1. Comparaison de deux populations
2. Fréquences alléliques et fréquences génotypiques
3. Equilibre de Hardy-Weinberg

L’histoire de l’évolution est aussi une histoire des mathématiques appliquées
3 étapes de la génétique des populations, qui sont aussi trois étapes de la réflxion
1. Histoire des statistiques:
-Galton invente le coefficient de corrélation et la droite de régression.
-Pearson invente le Khi-deux (χ2)
-Fisher invente l’analyse de variance et la vraisemblance
2. Histoire des mathématiques
-Fisher, Wright et Haldane, inventent le modèle de la sélection
-Malécot, Kimura et Kingman inventent le modèle neutre
3. Depuis les années 1990, la génomique des populations est l’un des domaines
préférés des applications numériques, qui font beaucoup appel à la théorie des
probabilités, mais heureusement, les logiciels disponibles épargnent leurs
utilisateurs de trop entrer dans la théorie. Néanmoins, il faut en savoir les principes
pour interpréter des résultats.

Mid-parent
offspring
L’histoire de l’évolution est aussi une histoire des mathématiques appliquées
3 étapes de la génétique des populations, qui sont aussi trois étapes de la réflxion
1. Histoire des statistiques:
-Galton invente le coefficient de corrélation et la droite de régression.
-Pearson invente le Khi-deux (χ2)
-Fisher invente l’analyse de variance et la vraisemblance

L’histoire de l’évolution est aussi une histoire des mathématiques appliquées
3 étapes de la génétique des populations, qui sont aussi trois étapes de la réflxion
1. Histoire des statistiques:
-Galton invente le coefficient de corrélation et la droite de régression.
-Pearson invente le Khi-deux (χ2)
-Fisher invente l’analyse de variance et la vraisemblance
2. Histoire des mathématiques
-Fisher, Wright et Haldane, inventent le modèle de la sélection
-Malécot, Kimura et Kingman inventent le modèle neutre
3. Depuis les années 1990, la génomique des populations est l’un des domaines
préférés des applications numériques, qui font beaucoup appel à la théorie des
probabilités, mais heureusement, les logiciels disponibles épargnent leurs
utilisateurs de trop entrer dans la théorie. Néanmoins, il faut en savoir les principes
pour interpréter des résultats.

L’histoire de l’évolution est aussi une histoire des mathématiques appliquées
3 étapes de la génétique des populations, qui sont aussi trois étapes de la réflxion
1. Histoire des statistiques:
-Galton invente le coefficient de corrélation et la droite de régression.
-Pearson invente le Khi-deux (χ2)
-Fisher invente l’analyse de variance et la vraisemblance
2. Histoire des mathématiques
-Fisher, Wright et Haldane, inventent le modèle de la sélection
-Malécot, Kimura et Kingman inventent le modèle neutre
Malécot et Wright
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
1
/
50
100%