Notes

Notes :
EII2
Traitement Numérique du Signal
Daniel MENARD
Olivier SENTIEYS
http://r2d2.enssat.fr/enseignements/Tns/Tns.php

Notes :
Digital signal processing (DSP) is a segment of the IC industry where advanced digital
and analog technologies merge. The typical function of the DSP device is to perform real-
time processing of a digitized analog signal, changing that signal using arithmetic
algorithms, and then passing the signal on. The process is very math intensive and quite
complicated. In fact, finding competent DSP designers and programmers is often a
challenge for many DSP manufacturers.
2
Traitement Numérique du Signal
(Digital Signal Processing)
Analog
Signal
Processing
Digital
Signal
Processing
Converter
Technology
Provides the
Bridge
A/D
D/A
Analog or
Real-World
Signals
Digital or
Computer-
World
Signals
[ICE97]
Video/Image/Graphics Audio/Speech/Control
100M 10M 1M 100k 10k
High Data Rate
Fcl Low Data Rate

Notes :
3
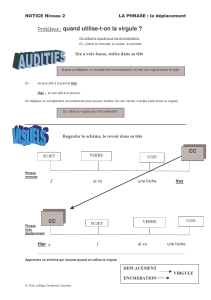
Cycle de développement
Besoin
Spécifications
technologiques
Spécifications
opératoires
Spécifications
fonctionnelles
Contraintes
temps réel,
Consommation
d’énergie,
Flexibilité
Coût
Contraintes
temps réel,
Consommation
d’énergie,
Flexibilité
Coût
Spécification
Spécification
Implantation
Matérielle
Implantation
Matérielle Implantation
Logicielle
Implantation
Logicielle
Partitionnement
Partitionnement
Implantation
Performances
Conception fonctionnelle
Conception fonctionnelle
Définition de
l'algorithme
Définition de
l'algorithme Simulation
Simulation Description de
l’algorithme
Spécifications
fonctionnelles

Notes :
4
Contenu du cours de TNS et PTS
•Analyse et conception de systèmes de TNS
– Analyse des filtres numériques
–Transformées en TNS
– Synthèse des filtres numériques RII
– Synthèse des filtres numériques RIF
– Analyse spectrale
– Systèmes multi-cadences
•Implantation de systèmes de TNS
– Arithmétique virgule fixe (codage - évaluation de la précision)
– Implantation logicielle : processeurs de traitement du signal
Implantation matérielle : module conception des circuits intégrés (S4)

Notes :
5
Plan du cours
I. Introduction
1. Introduction, problématique, caractéristiques, solutions architecturales
2. Caractéristiques des algorithmes
3. Applications typiques de TNS
4. Chaîne de traitement et problèmes temps réel
II. Processeurs de traitement du signal
I. Introduction
2. Description des différentes unités
3. Panorama des processeurs
4. Outils de développement
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
1
/
159
100%