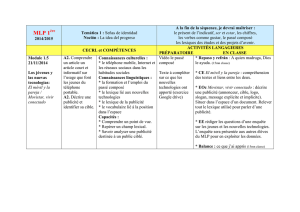
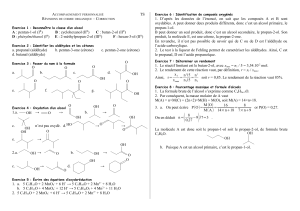
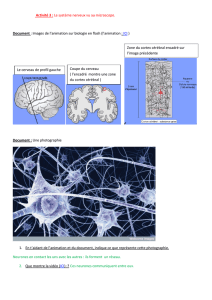
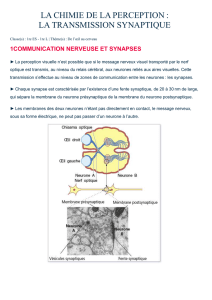
Document

Auto-organisation et
Quantification vectorielle
IV
B. Gas - V 0.6 (2014)
UE 5AI02/5AK03 - ISIR/UPMC

! "#$%&'&()*+,-*.&+"/012"31-"41(%56(5-"
"
! "7*(%1-"*$%&"&()*+,-*+%1-"81"9&0&+1+"
"
! "#3)&(,%0:1-";<="
Auto-organisation
Le neurone biologique
Le neurone formel
Le perceptron
élémentaire
Mémoires associatives
Le perceptron
Multi-couches (MLP)
MLP : optimisation
MLP : classification
MLP : généralisation
Auto-organisation
DEA IARFA, DEA RESIN
2003 Certaines parties de ce document (auto-organisation
chez les vertébrés) proviennent du projet bibliographique
réalisé par Nicolas DEBRAY.
DEA IARFA, DEA RESIN (2003)

Apprentissage non supervisé
Le neurone biologique
Le neurone formel
Le perceptron
élémentaire
Mémoires associatives
Le perceptron
Multi-couches (MLP)
MLP : optimisation
MLP : classification
MLP : généralisation
Auto-organisation
Les découvertes récentes à propos du cortex cérébral, rendues possible
grâce aux progrès de l’imagerie médicale et des techniques de mesure
électrique, ont permis de mettre à jour un mécanisme d’auto-organisation
des neurones corticaux.
Les systèmes auto-organisateurs sont des systèmes qui s’organisent à l’aide
d’algorithmes d’apprentissage non supervisés.
Un apprentissage non supervisé est un apprentissage qui s’effectue
sans professeur. On ne dispose donc plus des «!sorties désirées!». La
tâche d’apprentissage consiste alors à découvrir les catégories et les
règles de catégorisation.
-
apprentissage non
supervisé
- Chez les vertébrés
- Les cartes de Kohonen
- Algorithmes LVQ

Apprentissage non supervisé
Le cortex cérébral possède une structure
macroscopique uniforme d’un individu à un
autre.
Il est organisé en aires spécifiques aux
traitements de signaux particuliers. On
distingue 2 types d’aires :
- les aires sensorielles primaires qui
perçoivent les sensations élémentaires
telles que la vision, l’ouie, le toucher, le
goût.
- les aires sensorielles secondaires situées
à la périphérie des aires sensorielles
primaires qui réalisent la construction de
l’imagerie mentale.
Le neurone biologique
Le neurone formel
Le perceptron
élémentaire
Mémoires associatives
Le perceptron
Multi-couches (MLP)
MLP : optimisation
MLP : classification
MLP : généralisation
Auto-organisation
-
Apprentissage non
supervisé
- Chez les vertébrés
- Les cartes de Kohonen
- Algorithmes LVQ

Aires sensorielles primaires"
Une des caractéristiques fondamentales de l'organisation des voies
sensorielles primaires est l'existence d'une correspondance topique, c'est à
dire point par point, entre le récepteur périphérique et son aire de projection
corticale.
Le neurone biologique
Le neurone formel
Le perceptron
élémentaire
Mémoires associatives
Le perceptron
Multi-couches (MLP)
MLP : optimisation
MLP : classification
MLP : généralisation
Auto-organisation
-
Apprentissage non
supervisé
- Chez les vertébrés
- Les cartes de Kohonen
- Algorithmes LVQ
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
1
/
30
100%