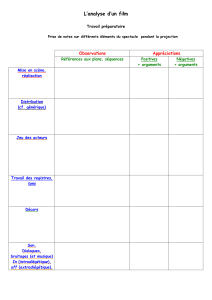
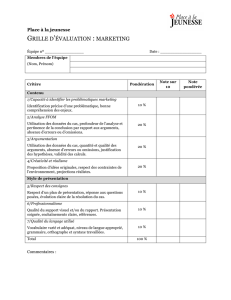
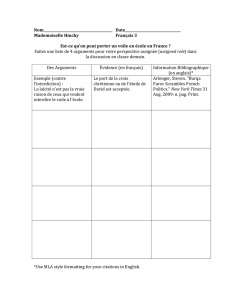
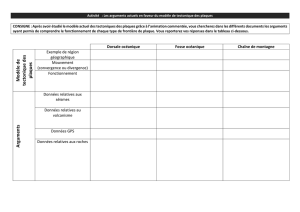
Extraction d`arguments de relations n

Extraction d’arguments de relations n-aires dans les
textes guid´ee par une RTO de domaine
Soumia Lilia Berrahou
To cite this version:
Soumia Lilia Berrahou. Extraction d’arguments de relations n-aires dans les textes guid´ee par
une RTO de domaine. Traitement du texte et du document. Universit´e Montpellier, 2015.
Fran¸cais. <NNT : 2015MONTS019>.<tel-01333058>
HAL Id: tel-01333058
https://tel.archives-ouvertes.fr/tel-01333058
Submitted on 16 Jun 2016
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-
entific research documents, whether they are pub-
lished or not. The documents may come from
teaching and research institutions in France or
abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est
destin´ee au d´epˆot et `a la diffusion de documents
scientifiques de niveau recherche, publi´es ou non,
´emanant des ´etablissements d’enseignement et de
recherche fran¸cais ou ´etrangers, des laboratoires
publics ou priv´es.

Délivrée par l’Université Montpellier
Préparée au sein de l’école doctorale I2S∗
Et des unités de recherche UMR IATE & UMR 5506 LIRMM
Spécialité: Informatique
Présentée par Berrahou Soumia Lilia
Extraction d’arguments de
relations n-aires dans les textes
guidée par une RTO de domaine
Soutenue le 29/09/2015 devant le jury composé de :
M. Thierry Charnois Professeur LIPN - Univ. Paris 13 Rapporteur
M. Ollivier Haemmerlé Professeur IRIT - Univ. Toulouse Rapporteur
Mme. Brigitte Grau Professeur ENSIIE LIMSI-CNRS Présidente de jury
Mme. Fatiha Saïs Maître de Conférences LRI - Univ. Paris Sud Examinatrice
M. Mathieu Roche Directeur de recherche CIRAD Directeur de thèse
Mme. Juliette Dibie Professeur AgroParisTech Co-directrice de thèse
M. Patrice Buche Ing. de recherche, HDR INRA IATE Co-directeur de thèse
∗I2S : École doctorale Information Structures Systèmes


Remerciements
Je veux adresser mes sincères et infinis remerciements à mes directeurs de thèse Ju-
liette Dibie, Patrice Buche et Mathieu Roche pour leur excellent encadrement scientifique.
Je suis heureuse d’avoir eu la chance de vous rencontrer et travailler avec vous. Je veux
également vous exprimer ma profonde gratitude pour vos encouragements, votre patience
et tolérance à mon égard dans les moments fragiles. Votre soutien sans faille m’a permis
de garder confiance et concentration pour l’aboutissement de la thèse.
Je remercie sincèrement Mme Brigitte Grau, Professeur à l’ENSIIE et LIMSI, Mme
Fatiha Saïs, Maître de Conférences au LRI - Université Paris, M. Thierry Charnois, Pro-
fesseur au LIPN - Université Paris ainsi que M. Ollivier Haemmerlé, Professeur à l’IRIT -
Université Toulouse, de me faire l’immense honneur de participer à mon jury de thèse et
évaluer mon travail. Un remerciement particulier à M. Charnois et M. Haemmerlé d’avoir
accepté la relecture approfondie du manuscrit et pour leurs remarques constructives.
Je souhaite adresser mes chaleureux remerciements à Maguelonne Teisseire, directrice
de recherche IRSTEA et membre de l’équipe ADVANSE au LIRMM. Notre rencontre,
notre travail et nos échanges passionnants et enrichissants à la Maison de la Télédétection
sont clairement à l’origine de la décision de m’initier au travail de recherche durant ces 3
années de thèse. Maguelonne m’a également fait l’honneur de suivre et évaluer l’avance-
ment de mes travaux à l’occasion des comités de suivi de thèse. Je te remercie Maguelonne
pour tes encouragements et ton enthousiasme. Je n’oublierai jamais ces bons moments
partagés à la MTD.
Je remercie Madalina Croitoru, Maître de Conférences et membre de l’équipe GraphiK
au LIRMM de m’avoir également fait cet honneur de suivre et évaluer l’avancement de
mon travail au cours des comités de suivi de thèse.
Mes remerciements vont également aux membres du LIRMM, et plus particulièrement
aux membres de l’équipe ADVANSE pour l’accueil toujours bienveillant des doctorants.

Mes remerciements à Nicolas Serrurier pour sa disponibilité et sa gentillesse à répondre
aux questions administratives.
Je souhaite dire un grand merci à mes camarades : Le grand et authentique Antonio
avec sa spontanéité, son sens de l’humour unique et son rire communicatif et curatif ! À
Manel, de l’équipe TEXTE qui voit la vie en rose ;) À Guillaume notre talentueux cinéaste
et aux plus "anciens" maintenant Hugo et Mickaël.
À ma famille et mes amis pour leur amour et réconfort quotidien : À Fred, mon âme
soeur. À mes petites soeurs, Assia et Neïla. À Noah, Cheyenne, Peter et Isabelle, les
enfants, Tineke et John, Pieter et Klaske et toute ma famille hollandaise. À Bärbara et
Dietrich, pour m’avoir ouvert avec une immense générosité les portes de Can Garous,
havre de paix niché dans les montagnes des Pyrénées Orientales chères à mon coeur pour
me ressourcer. À mes copines de toujours Aurélie et Jessica. À Dali et Jacques, ma famille
montpelliéraine. À mes amis ariégeois.
Soumia Lilia BERRAHOU 4
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
1
/
150
100%