Cours 2 - Florian Boudin

Machine Learning avec Weka
Module X8II090 - Cours 2
Florian Boudin
Département informatique, Université de Nantes
Révision 1 du 4 janvier 2012


Quiz sur les notions vues précédemment
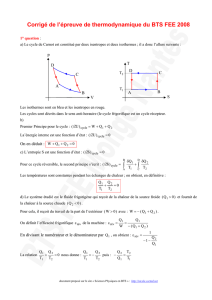
1. Qu’est ce que Weka ?
ISuite de logiciels d’apprentissage automatique et d’exploration de
données écrite en Java
2. Quel est l’évaluation la plus fiable ? l’algo le plus performant ?
IAlgo1, 81.3% d’instances correctement classées en découpage 2
3/1
3
IAlgo2, 78.4% de précision en validation croisée 10 strates
IAlgo3, 72.1% de f-mesure en validation croisée 10 strates
3. A quoi sert une matrice de coût ?
ILes erreurs des classifieurs sont inévitables puisqu’aucun modèle n’est
parfait ! Les matrices de coût permettent d’intégrer le fait que
certaines erreurs sont pires que d’autres
04 jan 2012 / Rév. 1 - page 3 sur 47

Quiz sur les notions vues précédemment
1. Qu’est ce que Weka ?
ISuite de logiciels d’apprentissage automatique et d’exploration de
données écrite en Java
2. Quel est l’évaluation la plus fiable ? l’algo le plus performant ?
IAlgo1, 81.3% d’instances correctement classées en découpage 2
3/1
3
IAlgo2, 78.4% de précision en validation croisée 10 strates
IAlgo3, 72.1% de f-mesure en validation croisée 10 strates
3. A quoi sert une matrice de coût ?
ILes erreurs des classifieurs sont inévitables puisqu’aucun modèle n’est
parfait ! Les matrices de coût permettent d’intégrer le fait que
certaines erreurs sont pires que d’autres
04 jan 2012 / Rév. 1 - page 3 sur 47

Le problème des probabilités nulles
Taille Style Utilité Mignon
petit coloré utile oui
petit pas coloré inutile oui
grand coloré inutile non
grand pas coloré utile non
petit coloré inutile ? ? ?
ICalculer P(oui|E)et P(non|E)
IRappel : P(H|E) = P(E|H)×P(H)
P(E)
P(oui|E) = P(petit|oui)·P(coloré|oui)·P(inutile|oui)·P(oui)/P(E)
P(oui|E) = 2/2·1/2·1/2·1/2=0.125
P(non|E) = P(petit|non)·P(coloré|non)·P(inutile|non)·P(non)/P(E)
P(non|E) = 0/2·1/2·1/2·1/2=0→Lissage
04 jan 2012 / Rév. 1 - page 4 sur 47
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
1
/
78
100%