Commande neuronale inverse des systèmes non linéaires

4th International Conference on Computer Integrated Manufacturing CIP’2007 03-04 November 2007
Commande neuronale inverse des systèmes non
linéaires
Mohammed Salem1, Djamel Eddine Chaouch1, M. Fayçal Khelfi2
1Centre Universitaire Mustapha Stambouli, Mascara, Algérie
2Université d’Oran Es-Senia, Algérie
Abstract- Le présent article relevant du domaine de
l’Automatique en général, et de l’Intelligence Artificielle en
particulier, est consacré à l’utilisation des réseaux de neurones
pour la commande d’un système dynamique non-linéaire. Il
constitue une contribution de l’Intelligence Artificielle pour
l’analyse et la commande des systèmes dynamiques. L’approche
proposée passe par l’identification d’un modèle neuronal inverse,
dont l’apprentissage est effectué avec la rétro-propagation
standard et modification des poids au moyen de l’algorithme de
Levenberg-Marquardt. Le modèle est utilisé dans une première
approche, comme contrôleur en boucle ouverte avec le système,
(Direct inverse control) pour un objectif de régulation. Dans la
deuxième approche le modèle inverse est utilisé conjointement
avec un contrôleur PID classique dans une structure de
commande hybride pour améliorer ses performances. Il contribue
au rejet des perturbations. La dernière section présente une
application de ces structures sur un système non-linéaire
didactique : masse ressort. Les travaux sont validés par des
simulations sous l’environnement MATLAB.
Mots clés : Réseaux de neurone, Apprentissage, Commande
neuronal, Système non-linéaire, Intelligence artificielle.
Levenberg-Marquardt, Modèle inverse
I. INTRODUCTION
Les principales difficultés dans la théorie de la commande
des systèmes dynamiques réels sont les non-linéarités et les
incertitudes. Or la commande passe par l’élaboration d’un
modèle mathématique du système en trouvant une relation
entre les entrées et les sorties, ce qui suppose une bonne
connaissance de la dynamique du système et ses propriétés.
Dans le cas des systèmes non-linéaires, les techniques
conventionnelles ont montré souvent leur insuffisance surtout
quand les systèmes à étudier présentent de fortes non-
linéarités. Le manque de connaissances à priori nécessaire pour
l’élaboration du modèle mathématique était en quelque sorte
dans cet échec.
Face à ce problème, le recours aux méthodes de commandes
par apprentissage est devenu une nécessité car les système de
commande obtenus ainsi procèdent par collecter des données
empiriques, stocker et extraire les connaissance contenues dans
celle-ci et utiliser ces connaissances pour réagir à de nouvelles
situations : on est passé à la commande intelligente (intelligent
control)[1].
Parmi les techniques d’apprentissage, les réseaux de
neurones, par le faite qu’ils sont des approximateurs universels
et parcimonieux [10] [4] et par leur capacité de s’adapter à une
dynamique évoluant au cours du temps, sont de bons candidats,
de plus, en tant que systèmes multi-entrées multi-sorties, ils
peuvent être utilisés dans le cadre de la commande des
systèmes multi-variables.
Un réseau de neurones non bouclé réalise une ou plusieurs
fonctions algébriques de ses entrées, par composition des
fonctions réalisées par chacun de ses neurones.[3]. Ceux-ci
sont organisés en couches et interconnectés par des connexions
synaptiques pondérées. L’apprentissage supervisé d’un réseau
à N sortie, consiste à modifier les poids w pour avoir un
comportement donné en minimisant une fonction de coût
représentée souvent par l’erreur quadratique [2]
2
1
1
() ( )
2
N
di i
i
Ew y y
=
=−
∑. (1)
Où d
y est la sortie désirée du réseau, i
yest la sortie
calculée.
Plusieurs chercheurs ont essayé d’exploiter les avantages des
réseaux de neurones pour commander un système dynamique,
et plus précisément, dans le domaine de la robotique [6] [20] et
pour la commande d’un moteur asynchrone [21] [24]. On peut
trouver plus de détails sur les structures de commandes avec
modèle neuronal dans [18] [19].
Le présent travail est une mise en exergue des capacités des
réseaux de neurones multicouches à reproduire la dynamique
inverse des systèmes non-linéaires et l’utilisation du modèle
neuronal inverse ainsi reproduit dans la conception des
structures de commande neuronale d’un système non-linéaire
La première section est consacrée à l’élaboration du modèle
neuronal inverse et la présentation des architectures utilisées
pour l’apprentissage de ce modèle. Ensuite, en section 2, deux
structures de commande sont étayées : une, basée sur
l’utilisation du modèle inverse comme contrôleur (Direct
inverse control), et dans l’autre, le modèle inverse intervient à
coté d’un contrôleur PID classique dans une structure de
commande hybride.
La dernière section présente une application de ces
structures sur un système non-linéaire masse ressort et les
résultats sont validées par des simulations MATLAB.
II. LE MODELE NEURONAL INVERSE
Bien que le modèle inverse de système joue un rôle important
dans la théorie de la commande, l'accomplissement de sa
forme analytique est assez laborieuse. Plusieurs méthodes de

4th International Conference on Computer Integrated Manufacturing CIP’2007 03-04 November 2007
modélisation des systèmes ont été présentées dans la littérature
[5] .Un système dynamique peut être décrit par l'équation (2)
reliant ces entrées aux sorties :
( 1) ( ( ),..., ( 1), ( ),..., ( 1))yk f yk yk n uk uk m+= −+ −+ . (2)
où la sortie du système y(k+1) dépend des n valeurs
précédentes de la sortie et les m valeurs passées de l’entrée. En
général, le modèle inverse de ce système peut être présenté
sous la forme suivante (3):
-1
( ) ( ( 1), ( )..., ( - 1), ( -1),..., ( - ))uk f yk yk yk n uk uk m=+ + . (3)
Les réseaux de perceptrons multicouches peuvent être
utilisées pour élaborer le modèle neuronal inverse du système.
Cependant, d’autre types de réseaux ont été utilisées [25], les
réseaux MLP statiques présentent la solution la plus simple,
toutefois la représentation de l’aspect dynamique du système
reste une problématiques. L'application des retards vers la
couche d’entrée à ce type de réseau peut présenter la solution
pour palier ce manque et remédier à l’aspect statique des MLP.
Cette solution présente l'avantage de permettre l’application
de l’algorithme traditionnel de rétropropagation du gradient
pour l’apprentissage des réseaux multicouche.
Le réseau correspondant à (3) est :
() ((), )ûk
g
xk w=. (4)
La fonction g va être approximée par un réseau de neurone
en modifiant ses poids w. Le réseau a un vecteur d’entrée x(k)
composé de la sortie k+1 et des valeurs des sorties et entrées
passées et ayant pour sortie le signal û qui va servir à
commander le système (Fig. 1)
L’identification du modèle neuronal inverse commence par
la détermination du vecteur d’entrée, à savoir le nombre des
retards en sorties et entrées, ceci est lié à l’ordre du système.
La deuxième étape est l’architecture du réseau (nombre de
couches cachées et nombre de neurones). La détermination des
paramètres du modèle est effectuée par un apprentissage du
réseau selon trois architectures
A. Architecture Générale d’Apprentissage
Dans la première architecture (Fig.2), le signal u est appliqué
à l'entrée de système, produisant une sortie y qui est fournie au
réseau. La différence entre le signal d’entrée u et la sortie du
Fig. 1. Réseau de neurone pour identifier le modèle inverse
réseau de neurone û est en, l’erreur rétropropagée à travers le
réseau et qui va servir pour l'apprentissage hors ligne du réseau
[26]. On tente de minimiser le critère E(w):
2
1
1
() (() (,))
2
N
k
Ew uk ûkw
=
=−
∑. (5)
Où w est un vecteur contenant les poids du réseau inverse.
Fig. 2. Architecture générale d’apprentissage
Cette méthode présente plusieurs inconvénients [7] [8] :
Les sorties y du système utilisées dans l’apprentissage ne
garantissent pas que les sorties du modèle neuronal vont être
dans des régions voulues pour le succès de son utilisation dans
la commande.
Si le système à commander est multi- variable, le modèle
ainsi retenu peut ne pas imiter le système réel.
B. Architecture Indirecte d’Apprentissage
Cette approche est une mise en oeuvre particulière de
l’architecture précédente dans laquelle, le modèle inverse en
cours d’apprentissage sert aussi à commander le système. La
consigne r est fournie au premier réseau qui produit une
commande û au système, la sortie de celui-ci est passée comme
consigne à la seconde copie du modèle inverse, qui produit
alors une commande û. La différence entre u et û sert de
signal d’erreur afin d’effectuer l’apprentissage des paramètres
du modèle par rétropropagation. Cette architecture, proposée
par [17] est présentée sur la (Fig.3).
L’idée derrière cette architecture est que la minimisation de
l’erreur commise sur la commande entraînera une minimisation
de l’erreur en sortie du système. Cependant, une erreur nulle
sur la commande ne provoque pas nécessairement l’annulation
de l’erreur totale en sortie du système
Fig. 3. Architecture indirecte d’apprentissage
û(k)
y(k+1)
y(k)
y(k-n+1)
u(k-m+1)
u(
k
-1)
système û(k
)
y(k) en
u(k)
+
-
S
y
stème y(k)
ec
r
(
k
)
-
+
û(k)

4th International Conference on Computer Integrated Manufacturing CIP’2007 03-04 November 2007
C. Architecture spécialisé d’apprentissage
Contrairement aux deux précédentes architectures,
l’architecture spécialisée, utilisée par [6], procède par
l’utilisation de l’erreur ec Eq(6), la différence entre la sortie
désirée r et la sortie réelle du système, pour apprendre au
modèle neuronal à suivre la dynamique inverse du système
Fig.4.
() () ()
c
ek rk yk=−. (6)
Une méthode de gradient peut être utilisée :
2
1()
2
() ( 1) c
ek
wk wk w
η
⎛⎞
∂⎜⎟
⎝⎠
=−− ∂. (7)
Ou
η
est le pas d’apprentissage, le gradient s’écrit :
() ()()
2
1() () () ( 1)
2() () (( 1))
c
cc
ek yk yk uk
ek ek
wwukw
⎛⎞
∂⎜⎟ ∂∂∂−
⎝⎠
=− =−
∂∂∂−∂
. (8)
Ce calcul requiert la connaissance du jacobien du système,
à cette fin, plusieurs méthodes ont été envisagées pour
l’approximer [27].
On peut remarquer que la valeur utilisée pour l’apprentissage
des paramètres du modèle inverse est l’erreur en sortie du
procédé. Une utilisation adéquate de la rétropropagation
imposerait pourtant que l’on rétropropage l’erreur en sortie du
modèle, qui est naturellement inconnue. Quoiqu’il en soit,
l’expérience montre qu’en général, cette approche est
inefficace. De plus, le modèle connexionniste étant utilisé dés
l’initialisation pour commander le procédé, il est conseillé de
disposer au départ d’un modèle relativement cohérent pour que
cette architecture puisse fonctionner [9].
Fig. 4. Architecture spécialisée d’apprentissage
III. COMMANDE NEURONALE
Parmi les structures de commande neuronales utilisant le
modèle inverse, deux sont présentées dans les paragraphes qui
suivent
A. Commande neuronale directe par modèle inverse :
Comme son nom l’indique, le modèle neuronal inverse placé
en amant du système, est utilisé comme contrôleur pour
commander le système en boucle ouverte (Fig.5).
Fig. 5. Commande directe par modèle inverse
La valeur de y(k+1) Dans (3) est substituée par la sortie
désirée r(k+1) et on alimente le réseau par les valeurs retardées
de u(k) et y(k). Si le modèle neuronal est exactement l’inverse
du système alors il conduit la sortie à suivre la consigne. Cette
commande a été utilisée par [17] et [23]. [22]. On utilisait cette
commande pour contrôler la direction d’un bateau.
B. Commande neuronal hybride
La deuxième approche de commande est celle qui fait
intervenir le réseau de neurone au sein d’une structure de
commande à lequel participe aussi un contrôleur classique
existant. Elle est présentée dans [11] dans le cadre de la
manipulation d’un bras de robot. Elles consistent globalement
à faire fonctionner simultanément un contrôleur feedback
conventionnel et un modèle connexionniste Cette approche ne
vise plus à apprendre la dynamique inverse du système, mais à
effectuer une régulation consistante de celui-ci. On fournit au
régulateur feedback classique ainsi qu’au réseau de neurone
l’erreur es commise en sortie du système. Le réseau dispose de
plus de la consigne r(k) Le signal de commande total est
constitué de la somme des sorties des deux dispositifs.
L’apprentissage des poids synaptiques est quant à lui réalisé
par rétropropagation de la sortie du régulateur classique. Cette
structure est représentée sur fig.6
L’approche est justifiée par le fait que lorsque la régulation
opérée est consistante, la sortie du régulateur classique est
nulle, confiant ainsi la tache de régulation au réseau de
neurone. Il s’agit d’une optimisation du fonctionnement du
modèle neuronal par d’autres techniques. Citons à ce titre. [12],
où un régulateur PID est utilisé pour réaliser la commande
neuronale d’un procédé non linéaire simple. Jorgensen et al
[13] utilisent cette méthode pour réaliser la commande d’un
modèle d’avion en phase d’atterrissage.
Fig. 6. Structure de commande neuronale hybride
Système y(k)
ec
r(k)
+
-
û(k)
Système y(k
)
r(k+1) u(k)
r Système y
ec
+-
uc
Contrôleur + +
û
u

4th International Conference on Computer Integrated Manufacturing CIP’2007 03-04 November 2007
L’apprentissage de la dynamique d’un bras articulé par une
méthode de ce type est évoqué dans [14]. Pour la commande
d’une colonne à distiller, Steck et al [15] proposent de copier
un régulateur existant.
En ce qui concerne la coopération des modèles feedback
classiques avec des modèles neuronaux, Gomi et al [11]
procèdent à des tests sur le problème classique du pendule
inversé. Enfin, Psaltis et al [16] présentent un autre exemple de
coopération dans laquelle le modèle neuronal utilise des
informations issues d’un PID lors de son initialisation.
IV. EXPERIMENTATION
Pour les simulations, on a choisi un système à minimum de
phase, stable en boucle ouverte et possédant une non-linéarité.
Le système est composé d’une masse, un amortisseur et un
ressort rigide [28]. L’équation du mouvement est donnée
par (9):
'' ' 3
() () () () ()yt yt yt yt ut+++ =. (9)
En premier lieu, On a élaboré le modèle inverse du système
ensuite on l’a utiliser dans les deux structures de commande
pour commander le système sans et avec bruit.
Pour générer les données d’apprentissage et de validation ,
on a excité le système (9) par un signal u(k) qui est une
séquence aléatoire dont l’amplitude est une distribution
uniforme dans l’intervalle [-5 5] pour avoir une entrée riche
(Fig.7) et la sortie y(k) correspondante est en Fig.8. La moitié
des données est utilisée pour l’apprentissage et l’autre moitié
est réservée à la validation.
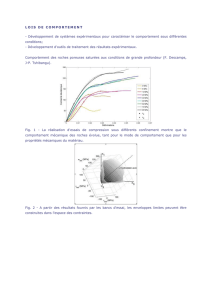
0100 200 300 400 500 600 700 800 900 1000
-5
-4
-3
-2
-1
0
1
2
3
4
5
Temps d'echant k
Signal entrée u(k)
Fig. 7. Signal d’entrée u(k) (0-1000 : l’apprentissage, 1001-2000 : validation
0200 400 600 800 1000 1200 1400 1600 1800 2000
-1.5
-1
-0.5
0
0.5
1
1.5
Temps d'echant k
Signal sort i e y(k)
Fig. 8. Sortie y(k) (0-1000 : l’apprentissage, 1001-2000 : validation
Après plusieurs essais, un réseau de neurone d’une seule
couche cachée avec 7 neurones a été retenu avec des tangentes
hyperbolique (tansig) comme fonction d’activation et une
sortie linéaire, {y(k+1), y(k),y(k-1),y(k-2),u(k-1) et u(k-2)}
sont ses entrées. L’apprentissage a été effectué par
l’algorithme de Levenberg-Marquardt.
L’erreur de prédiction est présentée dans Fig.9
0200 400 600 800 1000 1200 1400 1600 1800 2000
-5
-4
-3
-2
-1
0
1
2
3
4
5x 10
-4
temps d'echant k
Erreur de prédiction e(k )
Fig. 9. Erreur de prédiction du modèle inverse
Pour l’application du modèle inverse pour la commande
directe (§ 3.1) on a testé le modèle pour deux consignes, l’une
est un signal aléatoire yd (Fig.10), l’autre est un signal
sinusoïdal yd1 (Fig.11)
0200 400 600 800 1000 1200 1400 1600 1800 2000
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
temps d'echant k
Consi gne aléatoire yd(k)
Fig. 10. Consigne yd
0200 400 600 800 1000 1200 1400 1600 1800 2000
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
Temps d'echant k
Consi gne si nusoidale yd1(k)
Fig. 11. Consigne yd1
On présente l’erreur entre la consigne yd et la sortie du
système commandé par modèle inverse dans (Fig.12) et celle
entre la consigne yd1 et la sortie du système (Fig.13)
0200 400 600 800 1000 1200 1400 1600 1800 2000
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1x 10
-5
Temps d'echant k
Erreur de commande inverse eyd(k)
Fig. 12. Erreur commise lors de la commande directe (Consigne yd)
0200 400 600 800 1000 1200 1400 1600 1800 2000
-1
0
1x 10
-4
Temps d'echant k
Erreur de c ommande inverse ey d1(k)
Fig. 13. Erreur commise lors de la commande directe (Consigne yd1)
Quant à la commande hybride directe (§ 3.2) on a obtenu des
résultats satisfaisants dont l’erreur entre la consigne yd et la

4th International Conference on Computer Integrated Manufacturing CIP’2007 03-04 November 2007
sortie y est présentée en Fig.14 et celle entre la consigne yd1 et
la sortie réelle est en Fig.15
0200 400 600 800 1000 1200 1400 1600 1800 2000
-3
-2.5
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2x 10
-3
temps d'echant k
Erreur de commande hybride eyd(k)
Fig. 14. Erreur commise lors de la commande hybride (Consigne yd)
0200 400 600 800 1000 1200 1400 1600 1800 2000
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1x 10
-3
Temps d'echant k
Erreur de commande hybride eyd1(k)
Fig. 15. Erreur commise lors de la commande hybride (Consigne yd1)
On remarque des pics au début de la séquence, ceci est dû au
fait que le réseau au début n’a pas assez d’informations passées
pour suivre la consigne. Lorsque le temps passe et le réseau
acquérait les informations nécessaires, l’erreur de poursuite est
très réduite.
En dernier, on introduit un bruit blanc (Fig.16) dans le
système et on applique la commande hybride utilisée dans la
simulation précédente. Les erreurs pour les consignes yd et yd1
sont en Fig.17 et Fig.18
0100 200 300 400 500 600 700 800 900 1000
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
Temps d'echant k
Bruit blanc b(k)
Fig. 16. Bruit blanc introduit dans le système (9)
0200 400 600 800 1000 1200 1400 1600 1800 2000
-8
-6
-4
-2
0
2
4
6
8x 10
-3
Temps d'echant k
Erreur de c ommande hy bride bruité eyd(k)
Fig. 17. Erreur commise lors de la commande hybride avec bruit (Consigne yd)
0200 400 600 800 1000 1200 1400 1600 1800 2000
-6
-4
-2
0
2
4
6
8
x 10
-3
Temps d'echant k
Erreur de c ommande hy bride bruité eyd1(k)
Fig. 18. Erreur commise lors de la commande hybride avec bruit (Consigne
yd1)
V. CONCLUSION
Nous avons présenté, dans ce papier, deux structures de
commande par réseaux de neurones basées sur le modèle
neuronal inverse, l’apprentissage de ce modèle a été fait après
plusieurs tentatives pour arriver à une architecture optimale et
minimiser le nombre de paramètres du modèle. L’architecture
retenue était avec une couche cachée de 7 neurones. En
utilisant l’algorithme de Levenberg-Marquardt, L’erreur de
prédiction obtenue est très réduite. Le modèle retenu a été
utilisé ensuite dans une structure de commande directe en
boucle ouverte mais ceci suppose que le modèle inverse est
presque parfait et le système est non bruité, ce qui est loin de la
réalité. Pour essayer d’y remédier, nous avons utilisé le modèle
inverse dans une structure hybride avec un PID classique, et
nous sommes arrivés à des résultats très concluants. Pour
valider la structure hybride, nous avons injecté un bruit dans le
modèle. Ceci n’a pas trop affecté le système commandé.
Les résultats obtenus montrent qu’un modèle neuronal avec
un bon apprentissage, s’adapte parfaitement à la dynamique
d’un système avec rejet des perturbations.
REFERENCES
[1]. J.Panos, K.Antsaklis and M.Passino, Introduction to Intelligent and
Autonomous Control, Kluwer Academic Publishers, ISBN: 0-7923-9267-
1, 1993.
[2]. M.T.Hagan and H.B.Demuth, Neural network design,Thomson Asia Pte
Ltd,2nd ed 1996.
[3]. G. Dreyfus, Réseaux de neurones : méthodologies et applications, éditions
Eyrolles, 2002.
[4]. I. Rivals, L. Personnaz and G. Dreyfus, ‘’Modélisation, classification et
commande, Par réseaux de neurones : principes fondamentaux,
Méthodologie de conception et illustrations industrielles’’, 1995.
[5]. L. Ljung, System Identification; Theory for the User, Prentice Hall, 1987.
[6]. T. Yabuta and T. Yamada, ‘’Possibility of neural networks controller for
robot manipulators, Robotics and Automation’’, Proceedings, IEEE
International Conference, vol.3, 1990, pp. 1686-1691
[7]. G. Karsai, ‘’learning to control, some practical experiments with neural
networks’’, In International Joint Conference on Neural Networks, vol.
II, Seattle, 1991, pp. 701-707
[8]. B. Widrow, ‘’Adaptive inverse control’’, In Proceedings of the IFAC
Adaptive Systems in Control and Signal Processing Conference, Lund,
1988, pp.1-5
[9]. C. Goutte and C. Ledoux, ‘’Synthèse des techniques de commande
connexionniste’’, IBP-Laforia 1995/02: Rapport de Recherche Laforia,
1995.
[10]. G. Cybenko, ‘’Approximation by superposition of a sigmoidal function’’,
Math. In: Control Signals System 2nd ed, 1989, pp.303-314.
[11]. H. Gomi and M. Kawato, ‘’Neural network control for a closed loop
system using feedback error learning’’, Neural Networks, vol.5, 1993,
pp.933-946.
[12]. H. Bleuler, D. Diez, G. Lauber, U. Meyer and D. Zlatnik, ‘’Nonlinear
neural network control with application example’’, In International
Neural Networks Conference, vol.1, Paris, 1990, pp.201-204
[13]. C.C. Jorgensen and C.Schley, ‘’A neural network baseline problem for
control of aircraft flare and touchdown’’, Neural networks for Control,
1990, pp.423-425
[14]. A. Guez and I. Bar-Kana, ‘’Two degree of freedom robot adaptative
controller’’, In American Conference on Control, San Diego, 1990, pp.
3001-3006.
[15]. J. Steck, B. Krishnamurthy, B. McMillin and G. Leininger, ‘’Neural
modeling and control of a distillation column’’, In International Joint
Conference on Neural Networks, vol.II, Seattle, 1991, pp. 771-773.
 6
6
1
/
6
100%



![III - 1 - Structure de [2-NH2-5-Cl-C5H3NH]H2PO4](http://s1.studylibfr.com/store/data/001350928_1-6336ead36171de9b56ffcacd7d3acd1d-300x300.png)