Méthode quadratique pour évaluer des candidats durant un test

1ère Edition du Workshop International sur les Approches Pédagogiques & E-Learning 1
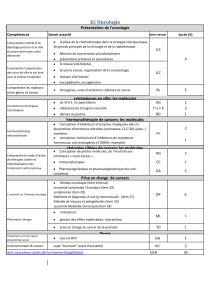
Méthode quadratique pour évaluer des candidats
durant un test adaptatif
- Méthode basée sur un modèle de la théorie des réponse à l’item-
Youssef KAAOUACHI (Auteur)
Laboratoire de Modélisation Stochastique et déterministe
Université Mohamed Premier, Faculté des Sciences
Oujda, Maroc
ykaaouachi@hotmail.com
Abstract— Computer Adaptive Testing (CAT) selects test
items (questions) successively for maximizing the accuracy of the
exam based on previous answers of the examinee. The basic
computer-adaptive testing method is an iterative algorithm with
the following steps: 1- Choose the first question in a questions
database, based on examinee's behavior. This behavior is set as
an "Ability Index". 2- The chosen question is proposed to the
examinee, who then can answer correctly or incorrectly. 3- The
"Ability Index" is updated, according the step 2 result. 4- Steps 1
and 3 are repeated until a termination criterion is met. For the
first step, we created a quadratic algorithm, based on an item
response theory model's, to select the most adequate (next) item
to ask the examinee.
Keywords—Item response theory; Computing adaptive
testing; quadratic method; quadratic method
I. INTRODUCTION
Les tests adaptatifs présentent de nombreux avantages, soit
côté réalisateur du test, car il peut bénéficier en retour des
réponses des candidats pour améliorer sa banque d’items, soit
côté candidat qui bénéficie de conditions de test optimisées et
à la portée de son niveau. Par contre, on a des inconvénients
que ça soit des contraintes méthodologiques [6]
(programmation sous contraintes, approche dynamique, calcul
numérique) ou des contraintes théoriques (par exemple, la
difficulté pour garantir l’absence de fonctionnement
différentiel des items) particulièrement délicates. Les
approches actuelles des tests adaptatifs tendent à privilégier la
maximisation de l’information (information de fisher [10],
likelihood estimation [10]) apportée après chaque réponse, en
fonction des réponses antérieures, une procédure itérative de
sélection des items, en respectant la couverture du domaine à
évaluer, la validité du test et l’équité des scores délivrés aux
candidats. Pour remédier certaines de ces contraintes, nous
avons conçu un algorithme quadratique [1-4], en se basant sur
des modèle de la théorie des réponses à l’item, pour améliorer
les calculs et optimiser les ressources.
En collaboration avec l’Université Privée de Fès
Lotissement Qaraouiyine, Route d’Ain Chkef, 30 000,
Fès, Maroc
II. THERORIE DES REPONSES A L’ITEM ET ALGORITHME
QUADRATIQUE
A. Théorie des réponses à l’item
La théorie des réponses à l’item (TRI) joue, aujourd'hui, un
rôle central dans l'analyse et l'étude des tests adaptatifs. Les
modèles de TRI permettent d’estimer l’habilité d’un candidat,
et les paramètres d’estimation de difficulté des items, en se
basant sur autres paramètres liés à l’item et au candidat [7]. La
TRI peut être utilisée dans plusieurs domaines : l'éducation, la
psychométrie, la médecine, …
Les modèles logistiques de la TRI applicables aux items
dichotomiques (dont les résultats possibles soit faux (X=0) ou
vrai (X=1) [2]) considèrent que la probabilité qu’un candidat
donne une bonne réponse, dépend à la fois de son habileté et
des caractéristiques de l’item. Ainsi, cette probabilité
augmente avec l’habileté :
c >= 0 est l’indice de pseudo-chance de l’item,
θ est le niveau d’habileté du candidat,
b est l’indice de difficulté.
α l’indice de discrimination (item est plus discriminant que
l’autre). Il est proportionnel à la pente de la courbe
caractéristique de l’item lorsque le niveau d’habileté du
candidat est égal au niveau de difficulté de l’item (θ = b).
Il est établi que d = -1,7.
L’un des avantages des modèles de la TRI est de
pouvoir positionner les individus et les items sur un même
continuum. Donc, si l’item est trop difficile, cela signifie que
la différence (θ - b) est grande, et donc une probabilité plus
petite pour avoir une bonne réponse. Si cette différence est
négative cela veut dire que le candidat à une grande
probabilité de répondre correctement [5].
En générale, un test adaptatif est composé de quatre phases :

1ère Edition du Workshop International sur les Approches Pédagogiques & E-Learning 2
La phase initial, au cours de laquelle le ou les premiers
items sont sélectionnés et administrés au répondant ;
La phase de test, qui consiste à sélectionner le prochain
item, à obtenir la réponse et à mettre jour le patron de
réponses ainsi que l'estimateur du niveau d'habilité.
La phase d'arrêt, qui interrompt le processus adaptatif
lorsque le critère d'arrêt choisi est satisfait ;
La phase finale, qui fournit l'estimateur final du niveau
d'habilité sur la base des items administrés.
On a deux grandes parties, dans un système CAT :
l’estimation de l'habilité et le choix de l'item suivant. La 1ère
donne une estimation de l'habilité d'un candidat sachant ses
réponses aux items précédents, alors que le 2ème permet de
choisir l'item suivant, depuis la banque des items, en se basant
sur le niveau d'habilité.
Il faut mentionner que la constitution de la banque des
items est un élément central [8]. Une banque d'items est une
grande collection d'items disponibles, qui parmi lesquels sont
sélectionnés ceux poser. En tests adaptatif, ces items sont
préalablement calibrés en estimant leurs paramètres d'items à
l'avance.
Il y a actuellement deux stratégies fondamentales de
sélection des items basées sur la théorie de réponse à l’item,
qui sont généralement utilisées : la stratégie dite d’information
maximale et la stratégie bayésienne. Durant notre algorithme,
après avoir estimé la compétence du candidat, en tenant
compte de ses réponses à tous les items précédents, on évalue
la fonction d’information des différents items à ce niveau de
compétence, et on choisit comme item suivant celui qui
procure l’information maximale parmi les items inclus dans le
prochain pas. Lorsque le sujet a répondu à ce nouvel item, on
ré-estime θ et on répète la procédure. A la fin du test, la
dernière estimation de θ sera le score obtenu par le sujet.
B. Algorithme quadratique pour la sélection de l’item
suivant
Dance cette section, nous allons donner une description [3]
d’une première version d’un algorithme quadratique,
permettant d’estimer l’habilité de chaque candidat. On va
supposer que nous avons qu’un seul paramètre : la difficulté
de l’item b.
1) Banque des items : Contient 17 items de type questions
à Choix de Réponses de 1 à 5, triée par ordre de difficulté
(entre 0 et 1) croissant [11]:
- La 1ère rangée contient des libellés d'item,
- La 2ème rangée, contient l'identifiant de l'item,
- La 3ème rangée, contient le niveau de difficulté de l’item,
- La dernière rangée, contient le numéro de la réponse
correcte.
ItemIDDifficultéRéponse
i17170,05 4
i16160,15 2
i18180,28 1
i15150,383
i7 70,494
i3 30,581
i19 19 0,631
i5 50,645
i13 13 0,674
i1 10,713
i4 40,754
i2 20,843
i12 12 0,865
i6 60,891
i11 11 0,925
i14 14 0,933
i9 90,975
i8 80,995
i10 10 0,992
Ces items sont issus de la base de données ’Evapmib’
[11]. Une base d'évaluation en mathématiques, en ligne,
développée par l'APMEP (association qui représente les
enseignants de mathématiques de la maternelle à l'université)
en collaboration étroite avec l'institut Nationale de recherche
pédagogique (INRP) et l'Instituts de recherche sur
l'enseignement des mathématiques (IREM). Cette base est
composée de questions d'évaluation provenant d’études à
grande ou moyenne échelle, chacune étant munie d'un
ensemble de descripteurs : carte d'identité, résultats enregistrés
lors de diverses passations, analyses pédagogiques et
didactiques.
Les candidats : 50 étudiants, avec un niveau d’habilité
déjà estimé.
IDCandidat 12345..50
Habilité 0,90,55 0,470,330,54…0.08
1) Déroulement du test
L'individu reçoit le 1er item, depuis la base des items. Suite
à sa réponse, la 1ère partie calcule sont niveau (estimé)
d'habilité. La 2ème partie, permet de donner l'item suivant, qui
correspond au niveau d'habilité estimé par la 1ère partie.
L'individu répond au 2ème item, et ainsi de suite. Jusqu’à ce
qu’il n’y aura aucun item à administrer ou bien si une valeur
seuil a été atteinte [6].

1ère Edition du Workshop International sur les Approches Pédagogiques & E-Learning 3
1) Partie de sélection des items
Notre algorithme se base sur une méthode quadratique
pour la recherche de la question suivante selon le dernier
niveau de difficulté atteint :
On voit sur le schéma ci-dessus, que une fois le candidat
donne sa 1ère réponse au premier item, on essaie de donner un
item ayant un poids (difficulté) plus grand que le dernier posé,
si la réponse est correcte, on lui propose un autre item avec un
poids plus grand, sinon, on prose un item ayant un niveau de
difficulté plus petit que celui avec la mauvaise réponse et le
dernier item avec la bonne réponse. Et ainsi de suite, jusqu’il
n’y aura aucune question à poser cela veut dire qu’on a atteint
le niveau max du candidat.
D’après cet algorithme, les candidats ne vont pas recevoir
obligatoirement le même nombre d’items.
Un aperçu de l’algorithme :
Tableau des questions [i [Question, Difficulté,
Réponse]]
n = 17
Etape 1 : Trier le tableau selon la difficulté (indexé de
1 à n)
Etape 2 : Initialiser les variables de l’algorithme
- Le pas = 0
- Un conteur temporaire positif k=1 ;
- Un conteur tem
p
oraire né
g
atif
g
=1 ;
-Un test d'arrêt de l’algorithme tes
t
= vrai ;
- Niveau d’habilité Theta
Etape 3 : Rechercher l’item avec information max
(difficulté)
Faire {
Si réponse (Tableau des questions (pas)) == vrai)
Alors {
// le k est calculé en prenant en compte l’indice de l’item
// ayant une information max à ce point
…
pas = pas + 2(++k) ;
test = vrai ;
g = 0 ;
}
Sinon {
// idem que k
…
Pas = pas – 2(++g) ;
k=0 ;
test = vrai ;
}
} Tant Que (k !=0 && g !=0)
Retourne Tableau des questions (pas).poids
Résultats
Après que tous les candidats ont terminé leur test, on récupère
les résultats sous la forme suivante :
- La 1ère ligne contient les réponses correctes de chaque item
sur la ligne 3.
- La 2ème ligne contient les niveaux de difficulté de chaque
item.
- 1ère colonne identifiant du candidat
- 2ème contient le niveau de difficulté estimé avant le test
- Les 17 colonnes qui suivent, représente la réponse donnée
par le candidat pour chaque item passé
- La dernière colonne représente le niveau max de difficulté
atteint par le candidat.
En faisant une comparaison entre les niveaux d’habilité
estimé (base des candidats) et ceux retournés par l’algorithme,
on a une légère différence entre les deux résultats (voir le
schéma suivant : en bleu l’habilité estimée et en orange la
valeur après le test).

1ère Edition du Workshop International sur les Approches Pédagogiques & E-Learning 4
III. CONCLUSION
Dans cet article, nous avons décrit un algorithme
concernant la sélection des items à poser au candidat lors d’un
test adaptatif, basé sur une nouvelle approche quadratique, en
prenant en compte qu’un seul paramètre (la difficulté de
chaque item). Afin d’avoir un meilleur résultat, nous allons
développer un nouveau module permettant d’administrer 3
bases d’items avec le même algorithme et calculer l’écart-type
pour chaque candidat. Plus cette valeur est petite, et plus notre
algorithme est plus fiable. Théoriquement, l’algorithme est
capable de traiter un grand nombre d’items.
IV. PERSPECTIVES
Afin de rendre l’algorithme plus rapide et plus optimisé
possible, nous nous baserons dans une deuxième version sur
les points suivants :
Modéliser la base des items : Augmenter le nombre
des items dans les bases utilisées, Au lieu de travailler
avec un seul paramètre, nous allons ajouter d’autres
critères liés à l’item, en plus de la difficulté (la
discrimination, l’indice de pseudo-chance, …)
Améliorer l’algorithme pour administrer tout type de
question,
Utiliser les réseaux de neurones au niveau de la
sélection de l’item suivant à administrer, la
maximisation de l’information après avoir une réponse
à l’item en cours et l’estimation de l’habilité.
Ajouter un module permettant d’éviter d’administrer des items
faciles, plusieurs fois
References
[1] M.G.D Jong, J.E. M. Steenkamp, J.P. Fox, H. Baumgartner. Using Item
Response Theory to Measure Extreme Response Style in Marketing
Research. Journal of marketing Research, 2006
[2] D. Rizopoulos. Item Response Theory in R using Package ltm.
Department of Statistics and Mathematics, WU WirtschaftsuniversitÄat
Wien, 2010
[3] D. I. Popov, D. G. Demidov, D. A. Denisov. Adaptive method of
knowledge evaluation during employee's validation, 2014
[4] Popov D.I. Adaptive Testing Algorithm Based On Fuzzy Logic.
International Journal of Advanced Studies, 2013
[5] KOUSHOLT, Kristine et HAMRE, Bjørn. The students should be as
clever as they can – the Danish case – similarities in the Danish School
Reform and computer adaptive testing (CAT). Oxford Studies in
Comparative Education, 2015.
[6] http://echo.edres.org:8080/scripts/cat/catdemo.htm. Lawrence M.
Rudner. Online computer adaptive testing (CAT) tutorial
[7] M. Young, The Technical Writer’s Handbook. Mill Valley, CA:
University Science, 1989.
[8] Baker, F.B. and Kim, S.-H. Item Response Theory : Parameter
Estimation Techniques (2nd Ed.). 2004
[9] Devouche, E. Les banques d’items. Construction d’une banque pour le
Test de Connaissance du Français. 2003
[10] Johnson, M.S. Marginal Maximum Likelihood estimation of item
response models in R. Journal of Statistical Software, 2007
[11] http://nobelis.eu/photis/Estimat/Proprietes/information_fisher.html
http://evapmib.apmep.fr/siteEvapmib/
1
/
4
100%