Student_pour le BUP

1
LA LOI DE STUDENT EN PHYSIQUE
Jean François Kentzel – Enseignant de mathématiques au lycée Pardailhan à Auch (32) – JKentzel@ac-toulouse.fr
Résumé
Le modèle suivant lequel l’erreur commise sur la mesure d’une quantité fixée est un
nombre aléatoire qui de plus suit une loi normale d’espérance 0 est couramment accepté
pour la plupart des mesures effectuées en sciences. Sous cette hypothèse, si
n
xxx ...,21
sont les résultats de
n
mesures indépendantes et suivant le même protocole d’une
quantité fixée désignée par
m
, et si on désigne par
nxx i/
et par
's
le nombre
=
1
)(
'2
n
xx
si
, souvent dit écart-type débiaisé des
i
x
, le nombre aléatoire
t
=
ns
mx
/'
suit une loi fixée appelée la loi de Student. Ceci permet d’encadrer
m
(avec une
certaine probabilité !) même si
n
est petit (
n
> 1).
Le texte qui suit est la réponse à une question de ma collègue de physique Marie-Claude PETIT que je remercie
ici. La bibliographie figure sur une annexe plus détaillée sur certains points et disponible sur Internet
( http://pardailhan.entmip.fr/. Cliquer sur Rubriques des disciplines/ Mathématiques/ Documents- enseignants).
On s’applique notamment à y montrer que l’idée reçue : « il faut disposer d’un assez grand nombre
d’observations pour pouvoir utiliser la statistique », qui est assez répandue, est fausse.
Supposons qu’un scientifique ait trouvé, en suivant le même protocole, trois
mesures différentes,
21,xx
et
3
x
pour une même grandeur
m
dont il sait qu’elle est
constante. Il estime intuitivement
m
par la moyenne empirique
nxx i/
. On
s’intéresse dans ce qui suit à la qualité de cette estimation.
Si ce scientifique s’est bien appliqué pour prendre ces mesures, il est forcé de constater
que le résultat d’une mesure qu’il effectue est fluctuant à cause d’événements dont les détails
lui échappent.
Certains de ces événements sont examinés dans un commentaire du programme de physique de terminale S (voir
[7]). La loi de Student qui va être présentée est citée dans les commentaires des
programmes mais elle ne figure pas explicitement au programme.
On va d’abord expliciter deux phrases du texte [7] (page 87 et note 25 de la page 92) :
« Il faut comprendre que la variabilité associée à la mesure est un phénomène objectif. ».
« L’expérience que constitue une mesure est modélisée par une loi de probabilité P sur l’ensemble des valeurs
qu’elle peut prendre (le plus souvent une loi gaussienne
1
). »
1 ) LE MODELE DE LA LOI NORMALE (OU GAUSSIENNE) POUR LES MESURES EN PHYSIQUE
Ces deux phrases signifient seulement que si on prend un grand nombre de
mesures on obtient un histogramme du type ci-contre. Les mesures obtenues sont
regroupées autour de la « vraie »2 valeur
m
de la grandeur mesurée.
1
Cette hypothèse, brièvement justifiée dans ce qui suit, est faite dans toute la suite de ce texte.
2
On trouve dans la bibliographie une justification de ces guillemets par l’exemple simple de la mesure d’un
objet en bois : le fait que le bois a une odeur prouve qu’il y a constamment des molécules qui s’échappent de
l’objet en question; il serait donc chimérique de vouloir parler de ses « vraies » dimensions.
0
5
10
15
20
25
30
-6_-5,49
-4,97_-4,46
-3,95_-3,43
-2,92_-2,4
-1,89_-1,37
-0,86_-0,34
0,17_0,69
1,2_1,72
2,23_2,75
3,26_3,78
4,29_4,81
5,32_5,84
6,35_6,86562757598063

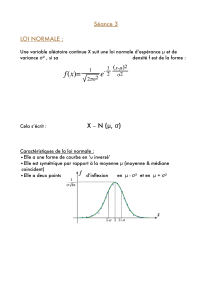
2
La loi gaussienne de moyenne m et d’écart type
est définie par sa densité
f
:
x
2
1
2
2
2
)(
mx
e
(il s’agit de la célèbre « courbe en cloche »). On la rencontre si souvent
dans toutes les disciplines scientifiques qu’elle est aussi appelée loi normale et notée N (
m
,
2
). Actuellement
3
la loi normale n’est pas enseignée en mathématiques au lycée probablement car,
contrairement à la loi exponentielle, on ne connaît pas de primitive de sa densité et elle ne peut pas donner lieu à
des calculs; elle est tabulée à l’aide de valeurs approchées d’intégrales, voir ci-dessous deux valeurs de sa table.
Les dessins ci-contre montrent les deux
valeurs concernant la loi normale N (
m
,
2
)
qui sont les plus connues.
Pour simplifier l’exposé, on va, suivant
l’usage, surtout utiliser le dessin de droite.
On dira alors qu’on s’accorde une marge
d’erreur de 5 % .
Le dessin de droite signifie que lorsque notre scientifique effectue une mesure, il a
environ 95 % de chances pour que son résultat soit entre
2m
et
2m
.
Ceci s’écrit aussi, en termes de probabilités, en désignant par
x
le résultat (aléatoire)
d’une mesure, sous la forme
4
: P (
22 mxm
) =
95,0)(
2
2
m
mduuf
.
La dispersion des mesures autour de leur moyenne
m
est mesurée par l’écart type
(théorique pour l’instant)
. Ce nombre
dépend du protocole utilisé pour effectuer les
mesures (plus le protocole est bon, plus
est petit). Son carré
2
est appelé variance de la
loi. Il est facile de prouver que
''f
s’annule en changeant de signe pour les valeurs
m
et
m
qui correspondent donc aux points d’inflexion de la courbe en cloche.
Brève justification du modèle de la loi normale pour une mesure
Ce modèle ne heurte pas l’intuition : il suppose qu’on ne commet pas d’erreur systématique (symétrie autour de
la « vraie valeur
m
», les physiciens les plus pointilleux évitant d’utiliser cette expression et préférant parler de
valeur standard ou de valeur de référence) et que les petites erreurs sont plus fréquentes que les grandes
(concentration autour de
m
). Il est surtout confirmé, approximativement , bien sûr, par un grand nombre
d’expériences. Un autre argument repose sur le théorème dit de limite centrale5.
En cas de doute sur la validité de ce modèle, on peut utiliser un test dit de normalité sur la série des mesures
n
xxx ...
2,1
. Un tel test, indiquant si l’hypothèse que les mesures
i
x
sont bien distribuées suivant une loi
normale est raisonnable, est systématiquement effectué par le logiciel évoqué à la fin de ce texte.
Soient
n
xxx ...
2,1
les résultats de
n
mesures indépendantes et suivant le même
protocole d’une quantité, désignée par
m
, dont on sait qu’elle est fixée. Comme on l’a dit, on
estime
m
par la moyenne empirique (on dit aussi : moyenne observée)
nxx i/
. La LOI
DES GRANDS NOMBRES permet d’affirmer que cette estimation est d’autant meilleure que n est
3
Il est permis d’espérer qu’il en ira autrement dans les programmes enseignés à partir de 2010.
4
On verra plus loin dans un tableau que la valeur 2 intervenant ici est en fait une valeur approchée de la valeur
approchée elle aussi) 1,96 mais pour l’instant ça n’a aucune importance.
5
Ce théorème dit en substance que toute somme ou moyenne de
n
nombres aléatoires indépendants suivant la
même loi (loi normale ou autre loi, d’écart-type fini) suit approximativement une loi normale lorsque
n
est
assez grand et il est une explication de l’omniprésence des lois normales « dans la nature ». Il justifie l’utilisation
de la loi normale pour les mesures en physique dans la mesure où on considère que l’erreur commise sur une
mesure est la somme de petites erreurs indépendantes et incompréhensibles pour l’observateur.
On verra plus loin que ce théorème prouve aussi qu’on peut s’affranchir de cette hypothèse de normalité dès
qu’on prend un assez grand nombre
n
de mesures, une borne courante étant
n
> 30.
Une autre justification de l’utilisation de la loi normale est le théorème de Lindeberg qui est plus général.

3
grand. On s’intéresse dans ce qui suit à la qualité de cette estimation lorsque l’entier
n
est fixé et éventuellement assez petit (
n
valant au moins 2).
Remarque sur l’intérêt du cadre probabiliste pour les calculs d’incertitudes :
Chacune des mesures
n
xxx ...
2,1
est un nombre aléatoire qui suit une loi normale N (
m
,
2
).
nxx i/
est donc aussi un nombre aléatoire. Si le modèle considérant une mesure comme un nombre
aléatoire semble fantaisiste, on peut adopter le point de vue, strictement équivalent, suivant lequel c’est l’erreur
effectuée sur une mesure qui est aléatoire :
soient X le résultat d’une mesure et E le nombre aléatoire :
« erreur commise sur une mesure ».
On a : X =
m
+ E donc E = X –
m
suit la loi N(0,
2
).
On peut assez facilement prouver que
x
suit alors la loi normale N (
m
,
n/
2
), c’est à dire que si on a un
écart-type (une dispersion)
pour une mesure, on a alors un écart-type
n/
pour la moyenne de
n
mesures.
On a donc une justification théorique du résultat facilement vérifiable expérimentalement : la dispersion des
résultats est moindre quand on calcule des moyennes, autrement dit : on a une plus grande précision lorsqu’on
calcule une moyenne de mesures
6
.
Les calculs d’erreurs classiques apparaissent ici comme inopérants. Ils donnent en effet, si on désigne par
e
l’incertitude sur une mesure :
pour tout
i
,
emxem i
d’où
)()( emnxemn i
et
emxem
.
Avec ces calculs, calculer une moyenne de mesures n’apporte aucune précision supplémentaire.
2 ) L’UTILISATION DE LA LOI DE STUDENT
Tout ce qui précède est très théorique et semble être dénué d’intérêt puisqu’on ne
connaît pas m (qu’on voudrait encadrer) ni
mais on dispose d’un résultat étonnant
7
pour qui croit que la statistique ne peut être utilisée que lorsqu’on dispose d’un grand
nombre d’observations : si les nombres aléatoires
n
xxx ...,21
suivent la loi N (
m
,
2
), alors,
en désignant par
's
le nombre
1
)(
'2
n
xx
si
(c’est l’écart-type empirique, ou observé,
débiaisé
8
de la série des mesures), quelles que soient les valeurs de
m
et
, le nombre
aléatoire
t
=
ns
mx
/'
suit une loi fixée et connue. Cette loi est appelée la loi de Student à
(
1 n
) degrés de liberté
9
.
6
Ce phénomène, qui a une justification statistique , ne doit évidemment pas être confondu avec le fait, évident,
qu’on a une meilleure évaluation de
m
lorsqu’on mesure, par exemple, 10.
m
et divise le résultat de la mesure
par 10 (par exemple pour mesurer la période d’un pendule oscillant).
7
résultat démontré au début du vingtième siècle, donc beaucoup plus récent que les autres qui sont évoqués dans
ce texte.
8
Noter que ce nombre n’est pas noté
s
car
s
est , en mathématiques, l’écart-type
n
xx
si
2
)(
de la
série de nombres
n
xxx ...,21
. On a bien sûr s’ =
1nn
s. s est utilisé dans certaines formules mathématiques,
et en mathématiques au lycée les élèves utilisent toujours s (que ce soit en calcul des probabilités ou en
statistique) mais
's
est la meilleure approximation de
. Sur les calculatrices,
s
et
's
sont notées
n
et
1n
pour Casio,
x
et
xs
pour TI. Voir l’annexe pour plus de détails et pour les notations des tableurs.
9
1n
car il y a une relation de dépendance entre les
n
variables dont les carrés figurent dans
's
:
)( xxi
= 0.

4
Désignant par
T
la loi
de Student à
degrés de
liberté, on donne ci-
contre la représentation
graphique des densités
de
1
T
,
2
T
et
4
T
sur [
4
;
4]. On y a ajouté la
densité de N (0 ;1) car
quand n grandit,
T
se
rapproche10 de N (0 ; 1).
Au voisinage de 0, c’est la courbe normale qui est au dessus des autres
(sa dispersion autour de 0 est moindre).
Noter que ces lois
1
T
,
2
T
et
4
T
sont celles qui sont utilisées pour 2, 3 et 5 mesures.
Les expressions des densités des lois de Student sont assez compliquées et il n’est pas
question de prouver ici ce qui précède. L’important pour nos questions de mesures est que,
comme la loi normale, les lois de Student sont tabulées. Le tableau suivant, relatif au « taux
de confiance » 95 %, peut être obtenu avec =LOI.STUDENT.INVERSE(0,05;A1-1) tapé sur
un tableur.
Le nombre
n
y désigne le nombre de mesures effectuées.
n
2
3
4
5
6
7
8
9
10
15
20
30
100
500
n
t;95,0
12,71
4,3
3,18
2,78
2,57
2,45
2,36
2,31
2,26
2,14
2,09
2,05
1,98
1,96
La signification du coefficient
n
t;95.0
est donnée par P (
n
tt ;95,0
)
95,0
pour
t
correspondant à
n
mesures : P (
n
t
ns
mx ;95,0
/'
)
95,0
, soit :
P (
n
t
n
s
x;95.0
'
< m <
n
t
n
s
x;95,0
'
)
95,0
.
Puisqu’on dispose des nombres
x
et s’ (grâce à des calculs simples) et
n
t;95.0
(lu sur
une table de la loi de Student; voir à ce sujet l’important encadré ci-dessous), on a un
encadrement de
m
avec une probabilité de 0, 95.
Notons que le scientifique fictif évoqué au début de ce texte devrait
utiliser le coefficient
n
t;95.0
3;95.0
t
4,30. C’est illustré ci-contre par
une simulation portant sur 200 valeurs de
t
: une dizaine de valeurs,
soit 5 % de ces valeurs, sont à l’extérieur de l’intervalle
[
30,4;30,4
].
On obtient donc pour trois mesures :
P (
3
'
3,4 s
x
<
m
<
3
'
3,4 s
x
)
0,95.
3 ) REMARQUES
1 ) On peut trouver en ligne sur plusieurs sites académiques (voir [9]) un petit
programme d’Excel très bien expliqué et pratique donnant directement cet intervalle quand on
10
par exemple la valeur 1,96 intervenant dans le tableau ci-dessous est celle qui a été évoquée pour la loi
normale (voir la note 4). Dès que
n
est assez grand la loi de Student à
n
degrés de liberté est très bien
approximée par la loi normale N (0 ;1).

5
lui fournit la liste des valeurs mesurées. Ce programme contient malheureusement une
erreur car il utilise pour
n
mesures les valeurs de
)(nT
au lieu de celles de
)1( nT
.
Pour que ce programme fonctionne bien, il faut remplacer le premier F11 de la
formule =LOI.STUDENT.INVERSE(1-pp1/100;F11)*F12/RACINE(F11) par (F11
1
).
Attention ! Dans ce texte et dans certains textes de physique figurant dans les références, n
désigne le nombre de mesures dans le coefficient
n
t;95.0
. Dans un manuel de statistique ce
nombre serait noté
1;95.0 n
t
car en statistique on utilise la notation
;95,0
t
pour une loi de
Student à
degrés de liberté (cependant que pour
n
mesures, le nombre
t
=
ns
mx
/'
suit une
loi de Student à (
1 n
) degrés de liberté). Cette différence de notation est très
probablement la cause de l’erreur évoquée ci-dessus.
Par exemple, dans un livre de statistique c’est le tableau suivant (obtenu avec la formule
=LOI.STUDENT.INVERSE(0,05;A1) tapée sur un tableur ) qu’on trouverait. Il est à comparer au tableau
précédent (qui est plus pratique pour un physicien car il prend pour point de départ :
n
= le nombre de mesures
effectuées).
1
2
3
4
5
6
7
8
9
10
16
20
30
50
100
500
;95,0
t
12,71
4,30
3,18
2,78
2,57
2,45
2,36
2,31
2,26
2,23
2,12
2,09
2,04
2,01
1,98
1,96
2 ) On a vu (voir la note 10) que lorsque
n
est grand (
n
>20 ou
n
>30) la loi de
Student est inutile car elle est très proche de N (0 ;1). On a alors s
s’
et l’égalité
précédente s’écrit approximativement P (
x
n
xm
n
22
)
95.0
. Dans ce cas, on
n’a d’ailleurs même plus besoin de l’hypothèse de normalité de la note 1 en vertu du théorème
évoqué dans la note 5 (dès que
n
est assez grand n’importe quelle moyenne de
n
nombres
aléatoires indépendants suivant la même loi suit approximativement une loi normale).
L’automatisation croissante des mesures en physique entraîne donc dans certains
domaines une moindre utilisation des lois de Student.
3 ) Un logiciel distribué par le CNDP (et peu coûteux) simplifie énormément l’usage
de la loi de Student. Voir la date du 28/11/2000 sur la page « Nous avons testé » de l’UdPPC.
1
/
5
100%