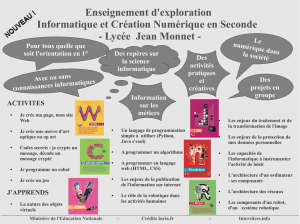
Intelligence Artificielle et Robotique - Cahier de l'ANR
Telechargé par
Moussa Seddik

Les cahiers de l’ANR - n° 4
mars 2012
Intelligence Artificielle
et Robotique
« Confluences de l’Homme et des STIC »

Nous remercions l’ensemble des contributeurs,
Bertrand Braunschweig, ainsi qu’Aline Tournier
et Aladji Kamagate de l’ANR.
Les cahiers de l’ANR traitent de questions thématiques
transverses aux différents appels à projets de l’ANR.
Cette collection met en perspective les recherches, les
innovations et les avancées technologiques en cours
dans un domaine spécifique. Quels sont les enjeux
technologiques, sociétaux, économiques, prospectifs?
Quelles sont les actions de l’ANR ?
Sans prétention d’exhaustivité, l’objectif est d’expliciter les
grandes problématiques. Il est fait référence à différents
projets de recherche financés par l’ANR. Une présentation
synthétique des projets est proposée.
Chaque cahier permet donc d’approfondir la connaissance
scientifique du domaine choisi. Il est utile pour les
chercheurs, les décideurs mais aussi pour un large public.
L’importance et la diversité des projets de recherche et des
équipes scientifiques sont ainsi mises en lumière.
Une version en ligne est également disponible : www.agence-nationale-recherche.fr
Photos couverture : SignCom, 2RT-3D, CONNECT, INTERACTS, ABILIS.

cahier de l’ANR
1
mars 2012
IA et Robotique
L’ANR met en perspective les avancées
scientifiques et les résultats obtenus par
les projets de grande qualité qu’elle soutient.
Ce cahier présente un ensemble de 115
projets sur les thématiques de l’intelligence
artificielle et de la robotique, des sujets au
cœur des sciences et technologies de l’in-
formation, où la recherche fondamentale
sur les algorithmes, les modèles, les mé-
thodes, côtoie les applications dans de nom-
breux secteurs tels que la santé, les trans-
ports, le Web, ou les processus industriels.
Intelligence artificielle et robotique sont éga-
lement des sujets sur lesquels l’imagination
est très riche. Il est important que l’ANR contri-
bue à démystifier la recherche sur le sujet
et mette en avant le riche contenu scienti-
fique qu’elle représente.
Parmi les scénarios, il y avait notamment
celui du remplacement de l’homme par
des systèmes artificiels. Si la théorie de la
Singularité évoque bien une telle éventua-
lité, l’objectif des recherches poursuivies est
de fournir une assistance aux utilisateurs
humains, pour les dégager des tâches pé-
nibles, dangereuses, ou répétitives, afin
de se consacrer aux activités les plus inté-
ressantes et enrichissantes.
La pluridisciplinarité de la recherche en in-
telligence artificielle et en robotique se retrouve
non seulement dans la diversité des appli-
cations présentées, qui rassemblent natu-
rellement des chercheurs en STIC et des spé-
cialistes des secteurs concernés, mais aussi
dans les thématiques abordées, par exemple:
robotique bio-inspirée, pour laquelle automa-
ticiens et informaticiens collaborent avec mé-
caniciens, biologistes, chercheurs en sciences
du comportement ; traitement automatique
de la langue, qui mobilise linguistes, spécia-
listes de l’interaction, et chercheurs en al-
gorithmique probabiliste ; Web sémantique,
pour lequel les chercheurs en représenta-
tion des connaissances travaillent avec des
sociologues pour les aspects réseaux sociaux
et folksonomies, et des philosophes pour la
mise au point des ontologies. Cette pluri-
disciplinarité est une grande richesse, por-
teuse de ruptures scientifiques et technolo-
giques, et donc de valeur ajoutée pour la
société et l’économie.
Je me réjouis de la publication de ce cahier,
qui poursuit la collection entamée début 2009
par l’agence. Il constituera très certainement
une référence essentielle pour les chercheurs
et les décideurs intéressés au développe-
ment et aux applications de l’intelligence
artificielle et de la robotique.
Jean-Yves Berthou
Responsable du département
STIC de l’ANR
avant-propos
Int ANR n°4 mars2012.qxd 13/06/12 20:45 Page 1

2
octobre 2011
cahier de l’ANR
mars 2012
IA et Robotique
2
L’idée d’Intelligence Artificielle suscite en-
thousiasme, espoirs, intérêt, aussi bien que
méfiance, incrédulité ou oppositions fa-
rouches dans les milieux scientifiques et pro-
fessionnels et dans le grand public. Elle a
été popularisée par des quantités d’ouvrages
et films de science-fiction, de robots, et de
jeux vidéo. Tout jeu de simulation a un per-
sonnage « IA » qui pilote les opposants arti-
ficiels aux joueurs humains. Des films tels que
A.I. (Spielberg) ou I, Robot (Proyas, inspiré
des écrits d’Isaac Asimov), ont présenté
des robots humanoïdes dotés d’intelligence
et de sensibilité égales à celles des hu-
mains, et capables de les affronter.
Tout ceci relève du mythe. Le test établi en
1950 par le mathématicien Alan Turing, qui
met un humain en confrontation verbale avec
un autre opérateur dont on doit déterminer
s’il est humain ou ordinateur, n’a jamais été
passé avec succès par une machine. On
serait actuellement bien incapable d’implé-
menter dans un robot les fameuses trois
lois de la robotique d’Asimov, qui demandent
des capacités d’analyse, de compréhension,
de raisonnement très supérieures aux pos-
sibilités actuelles des ordinateurs les plus
puissants, qui se situent numériquement à
l’ordre de grandeur du cerveau d’une mouche.
Les recherches sur l’intelligence artificielle
et la robotique ont cependant permis des
avancées dans de nombreux domaines : dia-
gnostic de défauts, configuration automa-
tique, vision artificielle et reconnaissance
de formes, compréhension de la parole et
de la langue, supervision de systèmes indus-
triels de production, planification automa-
tique de missions spatiales, jeux (échecs,
dames…). Elles ont aussi été à l’origine de
l’idée du Web sémantique, attendu comme
la prochaine génération du Web permet-
tant des traitements de l’information bien plus
riches que ce qu’il est possible de faire avec
les technologies actuelles.
Les défis de recherche en IA sont nombreux :
fournir les technologies du Web sémantique ;
extraire des connaissances des grandes
masses de données ; réaliser des systèmes
artificiels qui s’adaptent à un environne-
ment changeant ; réaliser des systèmes où
l’intelligence est distribuée entre de nom-
breux agents artificiels qui interagissent ; être
capable de raisonner sur le temps et l’es-
pace ; développer des robots autonomes
ou capables d’assister l’humain dans ses
tâches, seuls ou opérant en collectivité ; et
surtout, passer à l’échelle, se confronter
aux problèmes réels, aux données arrivant
en continu et en quantité. Pour ce faire,
spécialistes d’intelligence artificielle et de
robotique auront besoin non seulement de
pousser plus loin leurs recherches spéci-
fiques, mais aussi de collaborer avec des pra-
ticiens d’autres disciplines scientifiques voi-
sines, qui pourront enrichir les approches.
Au travers des plus de cent fiches de pro-
jets financés par l’ANR, accompagnées d’in-
troductions présentant les enjeux scienti-
fiques des grands domaines scientifiques
et technologiques abordés, ce cahier se veut
une contribution à l’information des cher-
cheurs, des décideurs et du public sur ce do-
maine fascinant mais ardu, loin des fantasmes
médiatiques et des promesses dithyram-
biques qui ont pu être faites dans un passé
pas si éloigné que cela.
résumé
Int ANR n°4 mars2012.qxd 13/06/12 20:45 Page 2
cahier de l’ANR
mars 2012
IA et Robotique
2
L’idée d’Intelligence Artificielle suscite en-
thousiasme, espoirs, intérêt, aussi bien que
méfiance, incrédulité ou oppositions fa-
rouches dans les milieux scientifiques et pro-
fessionnels et dans le grand public. Elle a
été popularisée par des quantités d’ouvrages
et films de science-fiction, de robots, et de
jeux vidéo. Tout jeu de simulation a un per-
sonnage « IA » qui pilote les opposants arti-
ficiels aux joueurs humains. Des films tels que
A.I. (Spielberg) ou I, Robot (Proyas, inspiré
des écrits d’Isaac Asimov), ont présenté
des robots humanoïdes dotés d’intelligence
et de sensibilité égales à celles des hu-
mains, et capables de les affronter.
Tout ceci relève du mythe. Le test établi en
1950 par le mathématicien Alan Turing, qui
met un humain en confrontation verbale avec
un autre opérateur dont on doit déterminer
s’il est humain ou ordinateur, n’a jamais été
passé avec succès par une machine. On
serait actuellement bien incapable d’implé-
menter dans un robot les fameuses trois
lois de la robotique d’Asimov, qui demandent
des capacités d’analyse, de compréhension,
de raisonnement très supérieures aux pos-
sibilités actuelles des ordinateurs les plus
puissants, qui se situent numériquement à
l’ordre de grandeur du cerveau d’une mouche.
Les recherches sur l’intelligence artificielle
et la robotique ont cependant permis des
avancées dans de nombreux domaines : dia-
gnostic de défauts, configuration automa-
tique, vision artificielle et reconnaissance
de formes, compréhension de la parole et
de la langue, supervision de systèmes indus-
triels de production, planification automa-
tique de missions spatiales, jeux (échecs,
dames…). Elles ont aussi été à l’origine de
l’idée du Web sémantique, attendu comme
la prochaine génération du Web permet-
tant des traitements de l’information bien plus
riches que ce qu’il est possible de faire avec
les technologies actuelles.
Les défis de recherche en IA sont nombreux :
fournir les technologies du Web sémantique ;
extraire des connaissances des grandes
masses de données ; réaliser des systèmes
artificiels qui s’adaptent à un environne-
ment changeant ; réaliser des systèmes où
l’intelligence est distribuée entre de nom-
breux agents artificiels qui interagissent ; être
capable de raisonner sur le temps et l’es-
pace ; développer des robots autonomes
ou capables d’assister l’humain dans ses
tâches, seuls ou opérant en collectivité ; et
surtout, passer à l’échelle, se confronter
aux problèmes réels, aux données arrivant
en continu et en quantité. Pour ce faire,
spécialistes d’intelligence artificielle et de
robotique auront besoin non seulement de
pousser plus loin leurs recherches spéci-
fiques, mais aussi de collaborer avec des pra-
ticiens d’autres disciplines scientifiques voi-
sines, qui pourront enrichir les approches.
Au travers des plus de cent fiches de pro-
jets financés par l’ANR, accompagnées d’in-
troductions présentant les enjeux scienti-
fiques des grands domaines scientifiques
et technologiques abordés, ce cahier se veut
une contribution à l’information des cher-
cheurs, des décideurs et du public sur ce do-
maine fascinant mais ardu, loin des fantasmes
médiatiques et des promesses dithyram-
biques qui ont pu être faites dans un passé
pas si éloigné que cela.
résumé
Int ANR n°4 mars2012.qxd 13/06/12 20:45 Page 2

3
cahier de l’ANR
mars 2012
IA et Robotique
2
L’idée d’Intelligence Artificielle suscite en-
thousiasme, espoirs, intérêt, aussi bien que
méfiance, incrédulité ou oppositions fa-
rouches dans les milieux scientifiques et pro-
fessionnels et dans le grand public. Elle a
été popularisée par des quantités d’ouvrages
et films de science-fiction, de robots, et de
jeux vidéo. Tout jeu de simulation a un per-
sonnage « IA » qui pilote les opposants arti-
ficiels aux joueurs humains. Des films tels que
A.I. (Spielberg) ou I, Robot (Proyas, inspiré
des écrits d’Isaac Asimov), ont présenté
des robots humanoïdes dotés d’intelligence
et de sensibilité égales à celles des hu-
mains, et capables de les affronter.
Tout ceci relève du mythe. Le test établi en
1950 par le mathématicien Alan Turing, qui
met un humain en confrontation verbale avec
un autre opérateur dont on doit déterminer
s’il est humain ou ordinateur, n’a jamais été
passé avec succès par une machine. On
serait actuellement bien incapable d’implé-
menter dans un robot les fameuses trois
lois de la robotique d’Asimov, qui demandent
des capacités d’analyse, de compréhension,
de raisonnement très supérieures aux pos-
sibilités actuelles des ordinateurs les plus
puissants, qui se situent numériquement à
l’ordre de grandeur du cerveau d’une mouche.
Les recherches sur l’intelligence artificielle
et la robotique ont cependant permis des
avancées dans de nombreux domaines : dia-
gnostic de défauts, configuration automa-
tique, vision artificielle et reconnaissance
de formes, compréhension de la parole et
de la langue, supervision de systèmes indus-
triels de production, planification automa-
tique de missions spatiales, jeux (échecs,
dames…). Elles ont aussi été à l’origine de
l’idée du Web sémantique, attendu comme
la prochaine génération du Web permet-
tant des traitements de l’information bien plus
riches que ce qu’il est possible de faire avec
les technologies actuelles.
Les défis de recherche en IA sont nombreux :
fournir les technologies du Web sémantique ;
extraire des connaissances des grandes
masses de données ; réaliser des systèmes
artificiels qui s’adaptent à un environne-
ment changeant ; réaliser des systèmes où
l’intelligence est distribuée entre de nom-
breux agents artificiels qui interagissent ; être
capable de raisonner sur le temps et l’es-
pace ; développer des robots autonomes
ou capables d’assister l’humain dans ses
tâches, seuls ou opérant en collectivité ; et
surtout, passer à l’échelle, se confronter
aux problèmes réels, aux données arrivant
en continu et en quantité. Pour ce faire,
spécialistes d’intelligence artificielle et de
robotique auront besoin non seulement de
pousser plus loin leurs recherches spéci-
fiques, mais aussi de collaborer avec des pra-
ticiens d’autres disciplines scientifiques voi-
sines, qui pourront enrichir les approches.
Au travers des plus de cent fiches de pro-
jets financés par l’ANR, accompagnées d’in-
troductions présentant les enjeux scienti-
fiques des grands domaines scientifiques
et technologiques abordés, ce cahier se veut
une contribution à l’information des cher-
cheurs, des décideurs et du public sur ce do-
maine fascinant mais ardu, loin des fantasmes
médiatiques et des promesses dithyram-
biques qui ont pu être faites dans un passé
pas si éloigné que cela.
résumé
Int ANR n°4 mars2012.qxd 13/06/12 20:45 Page 2
cahier de l’ANR
3
mars 2012
IA et Robotique
Partie 1 : L’intelligence artificielle et ses enjeux
Partie 2 : 115 projets financés par l’ANR
Est présentée ici une liste non exhaustive de 115 projets financés par l’ANR
sur la période 2006-2010
Ces projets sont issus de 19 appels à projets thématiques ou non-thématiques
Int ANR n°4 mars2012.qxd 13/06/12 20:45 Page 3
cahier de l’ANR
3
mars 2012
IA et Robotique
Partie 1 : L’intelligence artificielle et ses enjeux
Partie 2 : 115 projets financés par l’ANR
Est présentée ici une liste non exhaustive de 115 projets financés par l’ANR
sur la période 2006-2010
Ces projets sont issus de 19 appels à projets thématiques ou non-thématiques
Int ANR n°4 mars2012.qxd 13/06/12 20:45 Page 3
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
1
/
168
100%