ing Elmouataz billah Smatti

République Algérienne Démocratique et Populaire
Ministère de l’Enseignement Supérieur et de la Recherche Scientifique
Université Hadj Lakhdar Batna
Faculté de Technologie
Département d’Électronique
Mémoire
Présenté pour l’obtention du diplôme de
MAGISTER en Électronique
OPTION
Traitement du signal
Par
SMATTI El mouataz billah
Thème
Etude et mise en œuvre des techniques pour
la séparation aveugle des signaux
Soutenu devant le jury composé de :
Pr. BENOUDJIT Nabil Prof. Université de Batna Président
Pr. ARRAR Djemai Prof. Université de Batna Rapporteur
Pr.
BENZID Redha
Prof. Université de Batna
Co-Rapporteur
Pr. BENYOUCEF Moussa Prof Université de Batna Examinateur
Pr. SOLTANI Fouzi Prof. Université de Constantine Examinateur

Remerciements
Je tiens à exprimer mes vifs remerciements à mon encadreur Monsieur: ARRAR
Djemai professeur à l’université de Batna, pour avoir dirigé mon travail, son aide m’a
toujours été précieuse.
Je voudrais exprimer, ma gratitude et ma considération à Monsieur BENZID Redha,
Professeur à l’université de Batna, pour avoir suivi mon travail avec une attention
soutenue.
Je remercie très sincèrement Monsieur le Professeur BENOUDJIT Nabil, de
l’université de Batna, pour l’intérêt qu’il a manifesté pour ce travail et d’avoir accepté
de présider le jury de ce travail.
J’adresse mes vifs remerciements à BENYOUCEF Moussa, Professeur au
département d’électronique de l’université de Batna, pour avoir accepté d’examiner ce
travail
Je voudrais également exprimer mes vifs remerciements à monsieur SOLTANI Fouzi
Professeur à l’université de Constantine pour l’honneur d’assister à ce jury et d’enrichir
le manuscrit.
Enfin, j’exprime mes remerciements à tous ceux qui ont contribué de prés ou de loin à
l’élaboration de ce travail.

Sommaire
i -1
Sommaire
Remerciements
Sommaire...................................................................................................................................i-1
Liste des figures……................................................................................................................ii-1
Liste des tableaux.....................................................................................................................iii-1
Liste des symboles…................................................................................................................iv-1
Introduction générale....................................................................................................................1
Chapitre I:Concepts généraux sur les probabilités et aux statistiques d'ordre supérieur........4
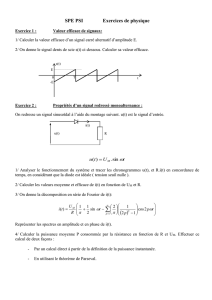
1.1:Introduction....................................................................................................... .....................5
I.2:Probabilités...............................................................................................................................5
I.2.1:Ensemble fondamental et événements...............................................................................5
I.2.2: Diagramme de Venn.........................................................................................................6
I.2.3: La notion de la probabilité et ses axiomes ......................................................................7
I.2.4: Probabilité conditionnelle et la règle de Bayes................................................................7
I.2.5: Evénements indépendants................................................................................................8
I.3:Variables aléatoires..................................................................................................................8
I.3.1: Evénements définis par les variables aléatoires................................................................9
I.3.2: Fonction de distribution (répartition) .............................................................................10
I.3.3: Fonction de densité de probabilité (PDF).......................................................................11
I.3.4: Espérance et variance d'une variable aléatoire................................................................11
I.4:Variables aléatoires multiples................................................................................................13
I.4.1 Fonctions de distribution (répartition) conjointe ............................................................14
I.4.2 Fonctions de densité de probabilité conjointe la PDF conjointe.....................................15

Sommaire
i -2
I.4.3:Distribution conditionnelle .............................................................................................15
I.4.4:Variables aléatoires indépendantes.................................................................................16
I.4.5: Covariance et le coefficient de corrélation ....................................................................16
I.5: Fonctions caractéristiques et Cumulants...............................................................................17
I.5.1:Fonction d'une variable aléatoire.....................................................................................17
I.5.2:Fonction de deux variables aléatoires.............................................................................18
I.5.3:Fonction caractéristique d'une seule variable aléatoire....................................................19
I.5.4: Fonctions caractéristique conjointe.................................................................................21
I.5.5 Moments et cumulants.....................................................................................................22
I.5.5.1: Moment et cumulants d'une seule variable aléatoire................................................22
I.5.5.2: Relation entre moments et cumulants d'une seule variable aléatoire........................23
I.5.5.3: Moment et cumulants de plusieurs variables aléatoires..........................................23
I.5.5.4: Relation entre moments et cumulants d'un vecteur aléatoire ...................................23
I.6:Processus stochastique (aléatoire)..........................................................................................24
I.6.1:Caractérisation d'un processus stochastique (aléatoire)..................................................25
I.6.1.1:Description probabiliste.............................................................................................25
I.6.1.2:Espérance, corrélation et fonction de covariance......................................................25
I.6.2: Processus stochastique stationnaire................................................................................26
I.6.3:Processus stochastiques independants............................................................................26
I.6.4:Histogramme...................................................................................................................26
I.7:Théorème de la limite centrale et le Kurtosis.......................................................................28
I.7.1:Kurtosis............................................................................................................................28
I.7.2: Théorème de la limite centrale........................................................................................29
I.8:Conclusion ............................................................................................................................30

Sommaire
i -3
Chapitre II Concepts généraux sur la SAS.............................................................................31
II. 1:Introduction..........................................................................................................................32
II.2:Vue historique.......................................................................................................................33
II.3: Le problème de la séparation de sources ............................................................................34
II.4.Caractéristiques du système de mélange..............................................................................35
II.4.1:Linéaire ou non linéaire..................................................................................................35
II.4.2: Instantané ou convolutif...............................................................................................35
II.4.3 : Selon le nombre de sources et le nombre d'observations.............................................35
II.5:Principe de la solution du problème de la SAS....................................................................36
II.6:L'analyse en composantes indépendantes (ICA)..................................................................37
II.6.1:Théorème de (Darmois-Skitovich)..................................................................................37
II.6.2:Définition de la (ICA).....................................................................................................38
II.6.3: Théorème de séparabilité...............................................................................................38
II.7:Le prétraitement (WHITENING-le blanchiment) ...............................................................38
II.8: Critères pour l'analyse en composantes indépendantes.......................................................40
II.8.1:Critère basé sur l'information mutuelle...........................................................................40
II.8.1.1:Entropie.....................................................................................................................40
II.8.1.2:Entropie conditionnelle ............................................................................................41
II.8.1.3:Information mutuelle................................................................................................41
II.8.2:Critères basé sur les statistiques d'ordre supérieur ........................................................41
II.8.3:Critère basé sur la maximisation de la non gaussienne .................................................42
II.9: Systèmes de séparation........................................................................................................43
II.10:Applications de la séparation de sources............................................................................44
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
1
/
124
100%