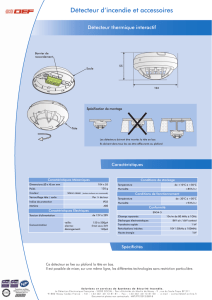
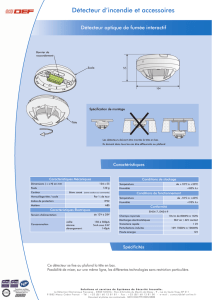
Détection sur données fortement inhomogènes et

Université Paul Cézanne Aix-Marseille III
École doctorale Physique et
Sciences de la Matière
Institut Fresnel,équipe Phy-TI
École Centrale Marseille
Détection sur données
fortement inhomogènes et
application aux RADAR
aéroportés
Thèse
présentée pour obtenir le grade de
Docteur de l’Université Paul Cézanne Aix-Marseille III,
spécialité « Traitement des Images »
par
Éric Magraner
Thèse soutenue le 5/12 /2008 devant le jury composé de :
Rapporteurs : Larzabal Pascal (Pr., IUT de Cachan)
Tourneret Jean-Yves (Pr., INP/ENSEEIHT)
Examinateurs : Becker Alain (Correspondant Thalès)
Bertaux Nicolas (Co-encadrant, ECM)
Blanc-Talon Jacques (Correspondant DGA)
Jauffret Claude (Pr., Université du Sud Toulon-Var)
Réfrégier Philippe (Pr., Directeur de thèse, ECM)
N˚ d’identification de la thèse : 2008AIX30063 RBCCN : 130552102


« La resignación es un suicidio permanente. »
Manu Chao


Remerciements
Lasoutenance de thèse est maintenant passée, elle clôture trois années de
doctorat, au cours desquelles il y a eu des bons moments et des moments
plus difficiles . . . De nombreuses personnes ont contribué à cette aventure, je
souhaite à travers cette modeste page les remercier.
Tout d’abord je voudrais dire merci à Philippe Réfrégier pour m’avoir
accueilli dans son équipe de recherche et m’avoir inculqué son sens de la
rigueur et de l’honnêteté. Un grand merci à Nicolas Bertaux auprès duquel
j’ai beaucoup appris, je souhaite le remercier pour sa disponibilité et lui
témoigner ma reconnaissance. Je souhaite également dire merci aux membres
de mon jury d’avoir accepté de participer à cette thèse. Merci à la DGA et au
CNRS qui ont financé ces travaux de thèse. Merci à l’équipe RIM de l’ONERA
pour la fourniture d’images RADAR ainsi qu’à Thalès Systèmes Aéroportés
pour les informations fournies.
Cependant cette thèse n’aurait pas été la même sans tous les membres de
l’équipe PhyTI, les permanents (Antoine, Arnaud, Frédéric, Marc, Muriel),
les anciens doctorants (Cyrille, Gemma, Guillaume, Jerôme, Nicolas, Pascal)
et les doctorants actuels (Arnaud, Émilie, Jean-François, Julien). Merci à tous,
je souhaite beaucoup de réussite aux futurs docteurs. Merci aux membres de
l’Institut Fresnel pour leur accueil.
Je n’oublie pas les personnes que j’ai rencontré lors de mon monitorat,
merci à ceux qui m’ont donné ma chance pour réaliser mes premiers ensei-
gnements (Jean-Jacques, Marc).
Pour se détendre rien de tel qu’un peu de sport, alors merci à tous
mes collègues d’entraînement (Anne, Anaïs, Julie, Sébastien), aux triathlètes
(Jean-Jacques, Julien, Ludovic, Pierre) et à coach (Didier) . . . à très bientôt
pour de nouvelles compétitions.
J’adresse un merci particulier à ma mère qui m’a donné la force de faire
des études et je souhaite avoir ici une pensée pour mon pépé et faire une bise
à ma mémé. Merci à mon frère et à toute ma famille pour leur soutien. Pour
conclure, je souhaite à la nouvelle génération (Nathan, Mathilde, Evan, . . .)
tout le bonheur du monde.
v
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
1
/
208
100%