Bases de données, une introduction au modèle relationnel

BASES DE DONNÉES, UNE INTRODUCTION
AU MODÈLE RELATIONNEL
VERSION 3.4
JUILLET 1999
D. HERMAN, P. BURGEVIN, P. FRESNAIS

79

BASES DE DONNÉES, UNE INTRODUCTION AU MODÈLE RELATIONNEL 1
Bases de données, une
introduction au
modèle relationnel
Daniel HERMAN, Patrice BURGEVIN, Placide FRESNAIS
Université de Rennes 1 - Ifsic
Propos liminaires
Ce polycopié a une longue histoire: la première édition (1986) accompa-
gnait un cours de bases de données, dispensé conjointement aux étudiants
de Maîtrise d'Informatique (Université de Rennes 1) et aux élèves de la qua-
trième année de l'option informatique (Institut National des Sciences Appli-
quées de Rennes). Il comportait deux parties respectivement consacrées aux
aspects externes (langages, conception de schémas relationnels) et aux as-
pects internes (mise en œuvre) des bases de données. La multiplication, au
sein de l’Ifsic, de formations demandant une courte initiation au domaine
(Dess Double Compétence, Diplôme d’ingénieur de l’Ifsic, licence d’infor-
matique) nous a conduit à ne retenir, pour la seconde édition (1989) que les
aspects externes.
L’évolution technique (multiplication des SGBD relationnels, le caractère dé-
sormais incontournable de SQL, l’émergence des SGBD orientés objets…)
nous ont conduit à une révision majeure.
Le contenu de cette nouvelle édition est fortement influencé par la durée du
cours (une quinzaine d’heures) et par le public visé (il s'agit souvent d'étu-
diants formés sur un profil d'ingénieur système). Nous avons donc souhaité
ne retenir d'un domaine vaste que la culture minimum que doit posséder
« l'honnête informaticien ». Nous nous sommes donc focalisés sur les fon-
dements du modèle relationnel en privilégiant les aspects linguistiques et
les problèmes posés par la conception de bons schémas relationnels. Ces as-
pects conceptuels forment le cœur de l’ouvrage (chapitre 2 et 4); nous avons
cependant, pour la présente édition, jugé utile d’adjoindre à ces aspects con-
ceptuels un certain nombre d’éléments sur l’état actuel de la technologie.

2 D. HERMAN, P. BURGEVIN, P. FRESNAIS, UNIVERSITÉ DE RENNES 1 - IFSIC
Bibliographie
Un ouvrage de référence
Un ouvrage de référence nous semble s’imposer:
•U
LLMAN J.D., Principles of Database and Knowledge-Base systems, Computer
Science Press, 1988 (volume 1) et 1989 (volume 2).
Le volume 1 traite des bases de données classiques et relationnelles; le
volume 2 est orienté vers l’optimisation et la logique.
Bibiliographie sur les SGBD relationnels
Nous donnons une bibliographie générale sur les SGBD relationnels, classée
selon l’ordre chronologique :
•DELOBEL C., ADIBA M., Bases de données et systèmes relationnels, Dunod In-
formatique 1982.
Les fondements théoriques des bases de données relationnelles.
•B
OUZEGHOUB M., JOUVE M., PUCHERAL P., Systèmes de bases de données : des
techniques d'implantation à la conception de schémas, Eyrolles 1990.
Les chapitres de l’ouvrage sont les suivants: organisation physique,
SGBD réseau, SGBD relationnel, exécution des requêtes relationnelles, dif-
férentes approches possibles en conception de bases de données.
•D
ATE C.J with DARWEN H., A guide to the SQL Standard, 3rd Edition, Addi-
son-Wesley Publishing Company, MA USA Octobre 1992.
Un livre sur la norme SQL 92; DATE est l'un des pionniers du domaine.
•MELTON J., SIMON A.R., Understanding the new SQL: a complete guide, Mor-
gan Kaufmann Publishers, CA USA 1993.
La norme SQL 92 est présentée et commentée.
•GARDARIN G., Maîtriser les Bases de Données - Modèles et langages, Eyrolles
1993.
Il s’agit d’une synthèse sur les bases de données, très axée sur SQL et l’al-
gèbre relationnelle.
•M
IRANDA S., RUOLS A., Client-serveur, concepts, moteurs SQL et architectures
parallèles, Eyrolles 1994.
Ce livre fait le point sur les normes, les standards et les SGBD relation-
nels.
•G
ARDARIN G., Bases de données objet et relationnel, Eyrolles 1999.
Ce livre couvre un champ assez large des bases de données — objectifs,
architectures, implémenation, accès, conception, exploitation — et pré-
sente une détaillée des modèles relationnels et relationnels-objets.
Perspectives: les SGBD objet
Vu le développement actuel des SGBD objet, nous avons souhaité donner
quelques titres dans ce domaine :

BASES DE DONNÉES, UNE INTRODUCTION AU MODÈLE RELATIONNEL 3
•DELOBEL C., LECLUSE C., RICHARD P., Bases de données : des systèmes rela-
tionnels aux systèmes à objets, InterÉditions 1991.
Une étude approfondie de l'approche objet.
•A
DIBA M., COLLET C., Objets et bases de données - Le SGBD O2, Hermès 1993.
Les principales notions qui définissent les SGBD objet sont examinées à
travers O2. Ce livre détaille tout le cycle d'utilisation d'O2, depuis la con-
ception d'une application jusqu'à l'administration des bases.
•B
OUZEGHOUB M., GARDARIN G., VALDURIEZ P., Les objets, Eyrolles 1997.
Un livre récapitulatif sur l'approche objet donnant une large part aux
méthodes de conception objet; le point sur la normalisation et sur l'ex-
tension objet de la méthode Merise.
•C
ATTELL R.G.G. BARRY D., The Object Databases Standard : ODMG-97 release
2.0, Morgan Kaufmann Publishers, CA USA 1997,
La norme en matière de SGBD objet: modèle de données ODL, langages
de requêtes OQL, connexions C++, SmallTalk et Java.
Remerciements
Nous tenons à remercier Jean LE PALMEC dont les notes de cours ont guidé
nos premiers pas dans le domaine.
Les nombreux enseignants de l’Ifsic qui ont été associés à ces enseigne-
ments ont évidemment apporté leurs contributions à cet ouvrage. Faute de
pouvoir les citer tous, nous les remercions chaleureusement.
Daniel HERMAN, Patrice BURGEVIN, Placide FRESNAIS
Rennes
Mars 1996
Novembre 1998
Juillet 1999
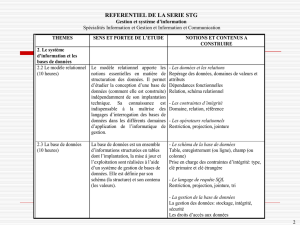
Architecture générale du cours
Le cours comporte 6 chapitres; la table des matières est à la fin de l’ouvrage.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
1
/
107
100%