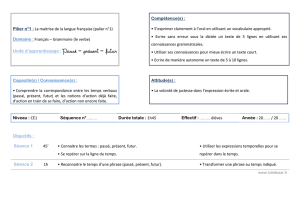
Utilisation des modèles de mélange pour la classification de

1/67
Utilisation des modèles de mélange pour la
classification de données temporelles
Séminaire Laboratoire LSIS-DYNI, USTV
Allou Samé
Laboratoire GRETTIA - IFSTTAR
allou.same@ifsttar.fr
29/11/2012, Toulon

2/67
Classification Automatique
Données
nindividus décrits par pvariables : (x1,...,xn)
Matrice des dissimilarités/distances croisées entre les individus
Objectifs
Organisation des données en classes homogènes (clustering)
Représentation simplifiée, réduction, compression des
données
Apprentissage non supervisé

3/67
Structures associées
Partition en Kclasses (P1,...,PK)
z1
.
.
.
zn
=
z11 ··· z1K
.
.
.....
.
.
zn1··· znK
avec zik =1si xi∈Pk
0sinon.
Hiérarchie (ensemble de partitions emboitées)
x1
x2
x4
x3
x5
x6
x7
x8
0 20 40 60 80 100 120
Height

4/67
Approches hiérarchiques
Algorithme de classification hiérarchique ascendante
Calcul d’un tableau de distances croisées si celui-ci n’est pas
fourni en entrée
Regrouper itérativement les classes en partant de la partition
la plus élémentaire (1 singleton par classe)
Fusionner successivement les classes jusqu’à obtenir 1 classe
Les regroupements successifs sont représentés sur un arbre
binaire (dendrogramme)
x1
x2
x4
x3
x5
x6
x7
x8
0 20 40 60 80 100 120
Height

5/67
Approches par partitionnement
Objectifs
Partitionner un ensemble de données en Kclasses
Algorithme K-means
Initialisation : tirage au hasard de Kobservations qui forment
les centres de gravité initiaux des classes
Tant que les classes ne sont pas stabilisées
1 affecter chaque observation à la classe dont le centre de
gravité est le plus proche au sens de la distance euclidienne
2 calculer des centres de gravité de la partition qui vient d’être
calculée
Critère optimisé
IW=
K
X
k=1 X
xi∈Pk
kxi−gkk2
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
1
/
67
100%