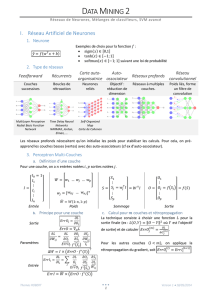
Proposition de sujet de thèse Lieu : Laboratoire d`Informatique de

Proposition de sujet de thèse
Lieu : Laboratoire d'Informatique de Grenoble : http://www.liglab.fr/
Équipe : Modélisation et Recherche d’Information Multimédia : http://mrim.imag.fr/
Financement : CDD de 36 mois, environ 1380 euros net par mois.
Date limite de candidature : 30 juin 2010.
Date de début : 1er septembre ou 1er octobre 2010.
Encadrants : Georges Quénot (Chargé de Recherche CNRS, HDR)
Philippe Mulhem (Chargé de Recherche CNRS, HDR)
Contact : [email protected], [email protected].
Titre : Utilisation du contexte pour l’indexation sémantique des documents image et vidéo.
L’indexation automatisée des documents image fixe et vidéo est un problème difficile en raison de la
« distance » existant entre les tableaux de nombres codant ces documents et les concepts avec lesquels
on souhaite les annoter (personnes, lieux, événements ou objets, par exemple). Des méthodes existent
pour cela mais leurs résultats sont loin d’être satisfaisants en termes de généralité et de précision. Elles
fonctionnent pour la plupart par apprentissage supervisé ou semi-supervisé : le système apprend les
concepts à reconnaître à partir d’exemples positifs et négatifs ; il « généralise » à partir de ces
exemples. Les méthodes existantes utilisent en général un ensemble unique de tels exemples et le
considère d’une manière uniforme. Ceci n’est pas optimal car un même concept peut apparaître dans
des contextes très divers et son apparence peut être très différente en fonction de ces contextes. Le
contexte peut être par exemple : le type d’émission (journal télévisé, fiction, divertissement, publicité,
etc.), la date, le lieu, le pays ou la culture de diffusion ou de production, ou encore les modalités
présentes ou absentes (cas de documents en noir et blanc et/ou sans son par exemple). Le contexte peut
en général être considéré comme un autre concept ou un ensemble d’autres concepts. Les concepts et
les relations entre eux peuvent être représentés dans des ontologies. On peut interpréter les relations
dans une ontologie comme le fait que les éléments ont des chances de se retrouver ensemble ou non
dans une image ou dans un plan vidéo et cette information peut être utilisée pour leur annotation
automatique.
Le sujet proposé concerne l’utilisation du contexte pour améliorer la performance des classifieurs.
L’idée principale est de considérer, pour chaque concept à reconnaître, un certain nombre de contextes
dans lesquels il peut apparaître et d’entraîner un classifieur pour chacun de ces contextes. Lors de la
reconnaissance, on utilise le classifieur approprié en fonction du contexte identifié ou une combinaison
pondérée (fusion) des résultats de classification si l’on dispose seulement de probabilités de se trouver
dans un contexte donné. Une telle approche présente plusieurs difficultés. La première réside dans
l’identification du contexte lors de la reconnaissance : dans certains cas, il peut être connu
explicitement (dans les métadonnées, par exemple) mais, en général, il s’agit en fait d’un autre
concept, lui-même à reconnaître. La seconde difficulté est dans la nécessité de disposer d’un volume
total de données d’apprentissage très important pour que, dans chaque contexte, on dispose de
suffisamment d’exemples pour entraîner valablement un classifieur. Il y a une complexité liée qui est
celle de gérer simultanément le réglage de plusieurs classifieurs pour chaque concept. La troisième
difficulté concerne le problème de la fusion des sorties des différents classifieurs dans le cas, fréquent,
où il y a des incertitudes à propos du contexte effectivement présent lors de la reconnaissance. La mise
en œuvre pourra reposer sur l’utilisation de réseaux d’opérateurs (extracteurs de caractéristiques,
classifieurs et modules de fusion), sur des ontologies pour gérer les relations entre concepts et sur
l’apprentissage actif pour la collecte automatique de données d’entraînement.
Les méthodes développées seront évaluées dans le cadre de campagnes nationales ou internationales
comme TRECVID (http://www-nlpir.nist.gov/projects/trecvid/). Le travail se fera dans le contexte du
programme Quaero (http://www.quaero.org). Celui-ci permettra entre autres choses d’avoir accès à un
grand volume de données vidéo annotées.
1
/
1
100%