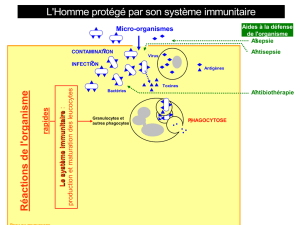
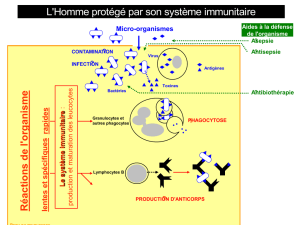
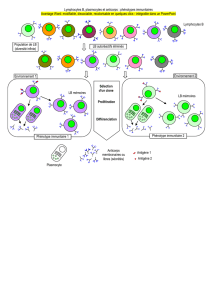
Traitement de données médicales par un Système Immunitaire

MINISTÈRE DE L’ENSEIGNEMENT SUPÉRIEUR
ET DE LA RECHERCHE SCIENTIFIQUE
UNIVERSITE ABOUBAKR BELKAID–TLEMCEN
FACULTE DES SCIENCES
DÉPARTEMENT D'INFORMATIQUE
Laboratoire Génie Biomédical
Equipe CREDOM
Mémoire de Magister en Informatique
Option: Intelligence Artificielle et Aide à la Décision (IAAD)
Présenté par
Mlle. SAIDI Meryem
Thème:
Traitement de données médicales par un Système Immunitaire
Artificiel
Reconnaissance Automatique du Diabète
Soutenu le 28 juin 2011 devant le jury :
Président:
Pr F.BEREKSI REGUIG Professeur à l'université Aboubekr Belkaid-Tlemcen
Examinateurs :
Dr Z.E. HADJ SLIMANE MC-A à l'université Aboubekr Belkaid-Tlemcen
Dr A. BENAMMAR MC-B à l'université Aboubekr Belkaid-Tlemcen
Directeur de mémoire :
Dr M.A. CHIKH MC-A à l'université Aboubekr Belkaid-Tlemcen
Invités :
Pr. A. AUSSEM Professeur à l'université Claude Bernard Lyon 1
Dr. H. ELGHAZEL MC à l'université Claude Bernard Lyon 1
2010-2011

ii
Résumé
L’utilisation des systèmes experts et les techniques dites intelligentes en diagnostic
médical ne cesse d'augmenter graduellement. Les Systèmes Immunitaires Artificiels (SIAs)
sont des méthodes parmi d'autres utilisées dans le diagnostic médical. Ce mémoire présente
une approche hybride MAIRS2 (Modified Artificial Immune Recognition System 2) basé sur
l’apprentissage du AIRS2 et l’algorithme K-plus proche voisin flou (k-ppv flou) pour
reconnaitre les personnes diabétiques présentes dans la base de données Pima Indians diabetes
(PID). Les performances des deux classifieurs, AIRS2 et MAIRS2, ont été comparées en
fonction du taux de classification, sensibilité et spécificité. Les plus hauts taux de classification
obtenus par l’application de l’AIRS2 et MAIRS2 sont respectivement 82.69 % et 89.10 %, en
appliquant l'approche 10-folds cross-validation.
Mots-clés : Base de données Pima Indians diabetes, diagnositic, AIRS2, MAIRS2, K-plus
proche voisin flou.

iii
Abstract
The use of expert systems and artificial intelligence techniques in disease diagnosis has
been increasing gradually. Artificial Immune Recognition System (AIRS) is one of the methods
used in medical classification problems. AIRS2 is a more efficient version of the AIRS
algorithm. In this paper, we used a modified AIRS2 called MAIRS2 where we replace the K-
nearest neighbors algorithm with the fuzzy K-nearest neighbors to improve the diagnostic
accuracy of diabetes diseases. The diabetes disease dataset used in our work is retrieved from
UCI machine learning repository. The performances of the AIRS2 and MAIRS2 are evaluated
regarding classification accuracy, sensitivity and specificity values. The highest classification
accuracy obtained when applying the AIRS2 and MAIRS2 using 10-fold cross-validation was,
respectively 82.69 % and 89.10 %.
Keywords: Pima Indians diabetes data set, diagnosis, AIRS2, MAIRS2, fuzzy k- nearest
neighbors.

iv
A ma Famille
Qu'elle trouve ici l'expression de toute ma
reconnaissance.

v
Remerciements
Avant toute chose, nous tenons à remercier Dieu pour l’accomplissement de ce projet.
Je tiens à exprimer ma très profonde gratitude à mon encadrant Mr. CHIKH Mohammed Amine qui
n’a ménagé aucun effort pour me prendre en charge pour la réalisation de ce travail. Je le remercie pour
le temps et les connaissances et la confiance qu'il m'a dispensé.
J'adresse mes sincères remerciements, au professeur F. BEREKSI REGUIG qui me fait l'honneur de
présider ce jury.
Je remercie tous particulièrement, Mr A. BENAMMAR, Maître de conférences à l'université Abou
Bekr Belkaid-Tlemcen, ainsi que Mr Z. HADJ SLIMANE, Maître de conférences à l'université Abou
Bekr Belkaid-Tlemcen, qui ont accepté de juger ce travail.
Je remercie également le professeur A. AUSSEM et H. ELGHAZEL pour leurs intérêt à ce travail et
de nous honorer de leurs présences.
Je remercie tous mes amis et toute l’équipe du Laboratoire de Recherche de Génie Biomédical pour leur
aide et leurs conseils, tout particulièrement Mlle N. SETTOUTI.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
1
/
88
100%