polygone et huffman

Université Claude Bernard – Lyon1 Licence Sciences et Technologies – L3
Algorithmique, Programmation et Complexité – LIF9 Printemps 2016
Examen final
Durée : 2 heures.
Avant de commencer
Le sujet est sur quatre pages, n’oubliez pas de les tourner. Ce sujet contient deux parties indépendantes. Au
sein de chaque partie, certaines questions sont indépendantes. Lisez donc toutes les questions et n’hésitez pas à
passer à la suite pour ne pas rester bloqué. Le barème final sera établi à partir de vos copies pour ne pas vous
pénaliser en cas de question trop difficile.
1 Codage de Huffman
Le codage de Huffman est un procédé très utilisé en compression de données. Il sert à encoder un texte en
binaire, en utilisant pour chaque lettre un nombre de bits dépendant du nombre de fois où la lettre est présente :
plus la lettre apparaît, plus le nombre de bits est petit. Ainsi, le nombre total de bits utilisés pour encoder le
texte est réduit par rapport à un codage ASCII standard qui utilise huit bits pour chaque lettre.
1.1 Arbres binaires
Le code binaire associé à chaque lettre est défini par un arbre binaire. Les feuilles de l’arbre correspondent aux
lettres de l’alphabet. Les nœuds interne ne contiennent pas d’information. Le chemin emprunté pour atteindre
une feuille depuis la racine définit le code de la lettre sur cette feuille : à gauche 0, à droite 1. Par exemple :
a
0
b
0
p
0
r
1
1
1a→0
b→10
p→110
r→111
barbapapa →10011110011001100
Question 1 – Écrivez pour l’arbre suivant le code correspondant à chaque lettre :
e
b d in
a
Question 2 – Codez le mot « badiane » avec le codage défini par l’arbre de la question précédente.
Question 3 – Décodez le mot décrit par le code binaire 01010000101.
1.2 Optimisation du code
Lorsque le texte à encoder est connu, il est possible d’optimiser l’arbre binaire utilisé pour raccourcir les codes
des lettres les pus fréquentes. C’est ce que fait l’algorithme de Huffman : il commence par compter dans le texte
le nombre d’apparitions de chaque caractère. Par exemple, dans la phrase :
je veux et j’exige d’exquises excuses
nous avons :
e : 9
␣ : 5
s : 4
x : 4
u : 3
i : 2
j : 2
’ : 2
c : 1
d : 1
g : 1
q : 1
t : 1
v : 1
où « ␣ » est le caractère espace, et « ’ » est l’apostrophe.

À partir de ces fréquences, l’algorithme initialise un arbre par caractère, avec comme poids le nombre d’ap-
paritions du caractère :
9
e
5
␣
4
s
4
x
3
u
2
i
2
j
2
’
1
c
1
d
1
g
1
q
1
t
1
v
dans la suite, nous indiquerons le poids d’un sous-arbre au niveau du nœud interne où il est enraciné.
À chaque itération, l’algorithme sélectionne les deux arbres ayant les poids les plus faibles, et les assemble
pour former les deux enfants d’un arbre binaire dont le poids est la somme des deux arbres. Lorsque plusieurs
arbres sont à égalité pour le poids le plus faible, l’arbre sélectionné parmi eux peut être n’importe lequel. Ainsi,
à la première itération, nous pourrions obtenir :
9
e
5
␣
4
s
4
x
3
u
2
i
2
j
2
’
1
c
1
d
1
g
1
q
2
1
t
1
v
et après quatre itérations de plus :
9
e
5
␣
4
s
4
x
3
u
4
2
1
c
1
d
2
’
4
2
i
2
j
2
1
g
1
q
2
1
t
1
v
Lorsqu’il ne reste plus qu’un seul arbre, l’algorithme est terminé. Plus formellement, l’algorithme de Huffman
est le suivant :
Fonction Huffman →arbre
données : l’alphabet et les fréquences de chaque lettre
résultat : l’arbre binaire du codage de Huffman
Algorithme
créer Structure
pour chaque caractère cde l’alphabet faire
créer un arbre a
a.caractère ←c
a.poids ←fréquence de c
ajouter aàStructure
tant que Structure contient plus d’un arbre faire
créer un arbre a
a.gauche ←l’arbre de poids le plus faible de Structure (que l’on retire de Structure)
a.droite ←l’arbre de poids le plus faible de Structure (que l’on retire de Structure)
a.poids ←a.gauche.poids +a.droite.poids
ajouter aàStructure
retourner le seul arbre contenu dans Structure
Question 4 – Terminez l’algorithme sur l’exemple fourni au dessus, en indiquant les étapes.
Question 5 – Si nest le nombre de caractères de l’alphabet, combien d’itérations réalisera l’algorithme ?
Question 6 – Quelle structure de données utiliseriez vous pour la variable Structure de l’algorithme ?
Question 7 – Quelles sont alors les complexités des opérations d’insertion et de suppression ?
Question 8 – Quelle est ainsi la complexité de l’algorithme de Huffman en fonction de la taille nde l’alphabet ?

2 Boîte englobante
Le but de ce problème est de concevoir un algorithme pour calculer la boîte englobante de certains polygones.
2.1 Tableaux montagne
Un tableau montagne est un tableau constitué de deux parties. Dans la première partie du tableau, les valeurs
sont rangées par ordre croissant. Dans la seconde partie, les valeurs sont rangées par ordre décroissant. À la
jonction des deux parties du tableau se trouve le maximum. Nous supposerons que le tableau ne peut pas
contenir plusieurs fois de suite la même valeur. Le tabeau suivant est un tableau montagne :
023561096431
Notez par contre que la partie croissante ou décroissante peut être vide, et qu’un tableau trié par ordre croissant
ou décroissant est donc également un tableau montagne :
0235
Votre but dans un premier temps sera de concevoir un algorithme pour déterminer le maximum d’un tableau
montagne. Considérons une case quelconque du tableau, mais pas une extrémité. La case précédente peut avoir
une valeur inférieure ou supérieure. De même pour la case suivante.
Question 9 – Quels sont les différents cas possibles ?
Question 10 – Comment se répartissent ces différents cas dans le tableau ?
Question 11 – En déduire un algorithme pour déterminer le maximum d’un tableau montagne.
Question 12 – Quelle est la complexité de cet algorithme dans le meilleur et le pire cas ?
Question 13 – Pouvez vous modifier votre algorithme pour les tableaux vallée (décroissant puis croissant) ?
Question 14 – Comment traiter le cas des tableaux contenant plusieurs fois de suite la même valeur ?
2.2 Polygone convexe
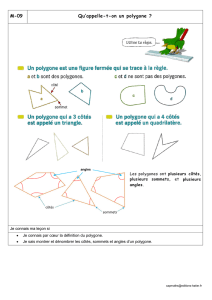
Un polygone est convexe si lorsque vous tracez un segment d’un point à un autre du polygone, le segment est
entièrement dans le polygone. Par exemple :
convexe convexe non convexe
Dans le cas non convexe, la ligne pointillée, correspond à un segment joignant deux points du polygone qui n’est
pas dans le polygone. Si cette notion de convexité vous gêne, considérez que tous les sommets du polygone sont
sur un cercle. Ce n’est pas équivalent à convexe, mais les résultats qui suivent seront les mêmes.
Pour le stockage en mémoire, nous considérerons que le polygone est enregistré dans deux tableaux contenant
respectivement les coordonnées x et y de ses sommets. L’ordre des sommets est déterminé en partant d’un
sommet quelconque et en faisant le tour du polygone. Deux sommets voisins dans le tableau sont donc voisins
sur le bord du polygone, et le premier et le dernier sommets du tableau sont également voisins sur le polygone.
Par exemple :
(0, 0) (0.5, 0)
(0.8, 0.5)
(0.6, 0.8)
(0.2, 0.9)
(-0.2, 0.4)
0.5 0.8 0.6 0.2 -0.2 0
x :
0 0.5 0.8 0.9 0.4 0
y :

Question 15 – En vous inspirant de la partie précédente, décrivez la structure des tableaux x et y.
Question 16 – Selon le sommet initial choisi et le sens de parcours, quelle sont les différents cas possibles ?
Dessinez des polygones illustrant chaque cas.
Question 17 – Écrivez un test permettant de déterminer à partir du tableau le cas correspondant.
Question 18 – En comparant les valeurs de la première et la dernière partie, pouvez vous les différencier ?
2.3 Boîte englobante
Calculer la boîte englobante d’un polygone consiste à déterminer sur chaque coordonnée le maximum et le
minimum. Dans le polygone dont les coordonnées sont fournies dans la partie précédente, la boîte englobante
du polygone est [−0.2,0.8] pour x et [0,0.9] pour y. Ces boîtes englobantes sont très utiles pour faire des tests
sur les polygones sans avoir à tester tous leurs sommets.
Question 19 – Écrivez un algorithme permettant de calculer le maximum et le minimum de chaque tableau.
Question 20 – Que se passe-t-il lorsque le polygone n’est plus convexe ?
1
/
4
100%