La synthèse des protéines

La synthèse des
protéines
L’ADN, support de l’information génétique, contient des gènes
qui déterminent les différents caractères héréditaires. Les
protéines sont les acteurs majeurs de la réalisation du
phénotype.
Problématique : Comment à partir d’une information génétique
sous forme de nucléotides la cellule aboutit-elle à la synthèse
de protéines constituées d’acides aminés ?
I. La relation entre l’ADN et les protéines
ADN et protéines sont deux molécules résultant de
l’enchaînement de monomères. La séquence linéaire
nucléotidique d’un gène détermine la séquence linéaire des
acides aminés constituant la protéine qui correspond à ce gène.
Un seul des deux brins d’ADN porte l’information génétique,
c’est le brin transcrit. Un gène est donc une séquence de
nucléotides d’un brin d’ADN, déterminant la séquence d’un
polypeptide donné.
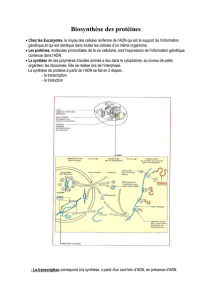
II. L’expression de l’information génétique
!"
De l’ADN à l’ARNm
Le passage de l’ADN à la chaîne polypeptidique débute dans le
noyau par le transfert de l’information génétique sur une chaîne
nucléotidique simple brin, l’Acide RiboNucléique messager
ou ARNm : c’est la transcription.
L’ARNm est constitué des bases azotées Adénine, Guanine,
Cytosine et Uracile.
Ce mécanisme se réalise par la présence d’enzymes, les ARN
polymérases.
Les ARN polymérases lisent le brin transcrit de l’ADN et par
complémentarité fabriquent l’ARNm. La base azotée Uracile de
l’ARNm est complémentaire de la base azotée Adénine de
l’ADN.
De nombreuses molécules d’ARNm sont transcrites
simultanément sur chaque gène.
!"
De l’ARNm à la protéine
• Le code génétique :
Un système de conversion permet de passer du « langage
nucléotides » au « langage acides aminés », c’est le code
génétique.
L’information génétique y est codée sous forme d’une
séquence de triplets de nucléotides. Chaque triplet forme un
codon qui est l’unité de conversion en séquence d’acides
aminés. Cette correspondance se fait chez tous les êtres
vivants, on dit que le code génétique est universel.
Certains acides aminés correspondent à plusieurs codons, on
dit alors que le code génétique est redondant.
• L’assemblage d’une chaîne polypeptidique :
La synthèse d’une chaîne polypeptidique, ou traduction, se fait
dans le cytoplasme. L’ARNm passe donc au travers de pores
nucléaires pour quitter le noyau.
La traduction démarre au niveau d’un codon précis, le codon
initiateur AUG codant pour l’acide aminé méthionine.
Certains codons ne correspondent à aucun acide aminé, ce
sont les codons stop UAA, UAG et UGA. Ils se trouvent en fin
d’ARNm et marquent l’arrêt de la traduction.
Les éléments nécessaires pour ce mécanisme sont le brin
d’ARNm, des ribosomes, des acides aminés et diverses
enzymes.
Les ribosomes sont constituées de deux sous unités qui se lient
un peu avant le codon initiateur sur l’ARNm et se séparent au
niveau d’un codon stop. Plusieurs ribosomes traduisent l’ARNm
en même temps.
La traduction se fait donc en trois étapes :
− l’initialisation avec la reconnaissance de AUG,
− l’élongation avec le déplacement des ribosomes sur
l’ARNm,
− la terminaison avec la rencontre d’un codon stop.
Les acides aminés sont reliés entre eux par une liaison
peptidique.
Un gène, séquence de nucléotides, porte les messages
permettant la formation des protéines, séquences d’acides
aminés. La synthèse protéique se fait en deux étapes :
• dans le noyau avec la transcription,
• puis dans le cytoplasme par la traduction.
La correspondance entre les deux types de séquences se fait
selon le code génétique.
R
1
: radical de l’acide aminé 1
R
2
: radical de l’acide aminé 2
Liaison entre deux acides aminés
MemoPage.com SA © / 2006 / Auteur : Géraldine Bridon
1
/
1
100%