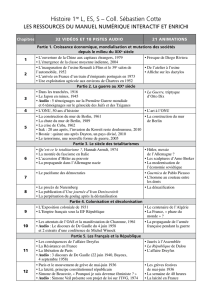
Apprentissage de représentations musicales à l`aide d`architectures

Apprentissage de représentations musicales à
l’aide d’architectures hiérarchiques et profondes
Philippe Hamel
Avril 2010
Document pré-doctoral présenté à :
Douglas Eck
Yoshua Bengio
et
Gena Hahn
1

Table des matières
1 Recherche d’information musicale 8
1.1 Représentations symboliques . . . . . . . . . . . . . . . . . . . . 8
1.2 Représentations de l’audio . . . . . . . . . . . . . . . . . . . . . . 9
1.2.1 Domaine temporel . . . . . . . . . . . . . . . . . . . . . . 9
1.2.2 Domaine fréquentiel . . . . . . . . . . . . . . . . . . . . . 10
1.2.3 Coefficients Cepstraux de Fréquence Mel . . . . . . . . . . 11
1.3 TâchesdeMIR............................ 12
1.3.1 Estimation de la hauteur du son . . . . . . . . . . . . . . 12
1.3.2 Détection de pulsation rythmique . . . . . . . . . . . . . . 13
1.3.3 Reconnaissance de genre . . . . . . . . . . . . . . . . . . . 13
1.3.4 Étiquetage automatique . . . . . . . . . . . . . . . . . . . 14
1.3.5 Reconnaissance d’instrument . . . . . . . . . . . . . . . . 14
1.3.6 Composition automatique . . . . . . . . . . . . . . . . . . 15
1.4 Difficultés généralement rencontrées avec l’analyse de la musique 15
1.4.1 Interférence.......................... 15
1.4.2 Effetperceptuel........................ 16
1.4.3 Sac de caractéristiques . . . . . . . . . . . . . . . . . . . . 16
2 L’apprentissage machine 18
2.1 Cadres d’apprentissage . . . . . . . . . . . . . . . . . . . . . . . . 18
2.1.1 Apprentissage supervisé . . . . . . . . . . . . . . . . . . . 18
2.1.2 Apprentissage non-supervisé . . . . . . . . . . . . . . . . . 18
2.1.3 Apprentissage semi-supervisé . . . . . . . . . . . . . . . . 19
2.2 La généralisation et la minimisation de l’erreur empirique . . . . 19
2.3 Quelques modèles d’apprentissage machine . . . . . . . . . . . . . 20
2.3.1 Classifieurs .......................... 20
2.3.2 Partitionnement non-supervisé . . . . . . . . . . . . . . . 22
2.4 Données à haute dimension et réduction de dimensionalité . . . . 22
2.4.1 Analyse en composantes principales . . . . . . . . . . . . 23
2.4.2 Échelonnage Multi-Dimensionnel . . . . . . . . . . . . . . 23
2.4.3 t-SNE ............................. 24
2.5 Apprentissage profond . . . . . . . . . . . . . . . . . . . . . . . . 24
2.5.1 Réseaux de neurones convolutionnels . . . . . . . . . . . . 25
2.5.2 DBN.............................. 25
2.5.3 DBN convolutionnels . . . . . . . . . . . . . . . . . . . . . 26
3 Recherche effectuée 28
3.1 Reconnaissance d’instruments . . . . . . . . . . . . . . . . . . . . 28
3.2 Apprentissage de représentation de l’audio musical . . . . . . . . 29
3.3 Encodage parcimonieux de la musique . . . . . . . . . . . . . . . 32
3.4 Jeuxvidéos .............................. 34
3.5 Apprentissage de structure répétitives . . . . . . . . . . . . . . . 34
2

4 Recherche Proposée 35
4.1 Apprentissage de caractéristiques de l’audio musical . . . . . . . 35
4.2 Représentation hiérarchique de la musique symbolique . . . . . . 36
4.3 Calendrier............................... 37
Références 38
3

Résumé
De récentes percées dans le domaine de l’apprentissage machine (AM)
nous permettent maintenant d’entraîner des architectures profondes qui
permettent un plus grand pouvoir de représentation et d’abstraction. Ces
architectures profondes montrent un potentiel pour représenter des don-
nées complexes et abstraites telles que la musique. Le domaine de la re-
cherche d’information musicale (Music Information Retrieval ou MIR)
pourrait ainsi profiter des avancées récentes en AM. L’apprentissage de
représentation musicales permettrait d’obtenir de meilleures caractéris-
tiques que celles extraites par traitement de signal, et pourraient être
utilisées dans une multitude de tâches de MIR. Également, un aspect qui
est souvent mal représenté en musique est la structure temporelle à long
terme. L’apprentissage de représentations hiérarchiques à l’aide de mo-
dèles à convolution pourrait potentiellement combler cette lacune.
4

Abréviations
Par souci de clarté et de cohérence vis-à-vis la littérature scientifique, l’acro-
nyme anglais est conservé dans la majorité des cas. Pour les nombreuses tra-
ductions de termes spécifiques au domaines présentes dans le texte, le terme
original en anglais est spécifié en italique.
AM Apprentissage machine Machine Learning
CD Divergence Contrastive Contrastive Divergence
CDBN DBN à Convolution Convolutional Deep Belief Network
DBN Deep Belief Network
DCT Transformée cosinusoïdale discrète Discrete Cosine Transform
DFT Transformation de Fourier Discrète Discrete Fourier Transform
EM Espérance-Maximisation Expectation-Maximization
FFT Transformation de Fourier Rapide Fast Fourier Transform
GMM Modèle de mixture de Gaussiennes Gaussian mixture model
HMM Modèle de Markov Caché Hidden Markov Model
KNN K plus proches voisins K-nearest neighbor
MDS Échelonnage Multi-dimensionnel Multidimensional Scaling
MFCC Coefficients Cepstraux de Fréquence Mel Mel-Frequency Cepstral Coefficients
MIDI Musical Instrument Digital Interface
MIR Recherche d’information musicale Music Information Retrieval
MLP Perceptron Multi-couches Multilayer perceptron
PCA Analyse en Composantes Principales Principal Component Analysis
PCM Modulation d’Impulsion Codée Pulse Code Modulation
RBM Machine de Boltzmann restreinte Restricted Boltzmann Machine
SVM Machine à vecteurs de support Support Vector Machine
5
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
1
/
42
100%