Classification de courbes par apprentissage

Classification de courbes par apprentissage
J-M.Loubes, O.Roudenko, M.Sebag et O.Wintenberger*
* : SAMOS, Université Paris 1 Panthéon-Sorbonne,
72 rue Régnault
75013 PARIS, FRANCE
RÉSUMÉ
Nous souhaitons dans ce papier résumer l’information apportée par un grand nombre de données, ici les courbes
d’évolution journalière de la vitesse moyenne des voitures observées sur une portion de route pendant deux ans.
Nous utilisons une nouvelle méthode de classification non supervisée afin de regrouper les observations en classes
cohérentes. Une méthode classique consiste à choisir les classes présentes à un même niveau dans une classification
ascendante hiérarchique (CAH), puis de s’entraîner sur un échantillon distinct pour atteindre le niveau optimal. A
partir de la CAH, nous effectuons une optimisation multicritère pour sélectionner de manière plus systématique les
classes recouvrant le plus de courbes ayant le plus de similarités. L'algorithme atteint de meilleurs résultats que la
méthode classique car il prend en considération les asymétries possibles dans la CAH.
MOTS-CLÉS : Classification, optimisation multicritères.
1 Introduction
Nous souhaitons résumer l’information d’un grand nombre d’observations grâce à une nouvelle méthode
de classification non supervisée. Nous procédons classiquement en trois étapes :
- Construire une CAH utilisant une distance spécifique aux données puis sélectionner les
classes recouvrant le plus de courbes ayant le plus de similarités. Cette étape est appelée
l’étape d’initialisation.
- Utiliser un échantillon de courbes distinctes pour sélectionner parmi ces ensembles de classes
le meilleur recouvrement. C’est l’étape d’apprentissage.
- Enfin comparer les résultats obtenus avec la méthode classique sur un troisième échantillon
test. C’est l’étape de validation.
2 Classification
2.1 Présentations des données
Nous observons la vitesse moyenne des véhicules sur une portion de route toutes les 6 minutes aux
instants t, et chaque jour
)( ktX j
j1
kdk ,...,1=J,...,
=
pendant deux ans. Nous scindons les courbes d’évolution
journalière de la vitesse en trois groupes :
d
j
Xℜ∈
- Les n premières observations , jX nj ,...,1
=
, seront utilisées dans la CAH.
- Les N courbes suivantes, notées , jY Nj ,...,1
=
, constituent l’échantillon d’apprentissage et
seront utilisées pour sélectionner le meilleur recouvrement.

- Les courbes restantes, notées , jZ Tj ,...,1
=
seront utilisées pour tester les performances de
notre algorithme.
2.2 Choix de la distance de classification
Nous avons choisi une distance spécifique à la nature de nos données afin de construire la CAH. Pour
, nous utilisons la distance définie par
d
yx ℜ∈,∆)()(),( yxWyxyx t−−=∆ où W est la matrice d par d
définie par d
jid
ji
−−
=
,
Wpour tout i et j
∈
{1,…,d}. Cette distance prend en compte la dimension
temporelle de l’évolution de la vitesse des véhicules. Ainsi, les phénomènes similaires seront ordonnés
selon les délais entre leurs moments d’apparition :
Figure 1
Nous avons et 637),(),( =∆=∆ ZYYX 967),(
=
∆
ZX alors que la distance euclidienne ne fait aucune
distinction entre ces 3 courbes. Les pics de vitesses représentent dans notre cadre d’étude les bouchons.
Notre distance permet de faire une distinction suivant l’heure à laquelle ces phénomènes ont lieu.
2.3 Classification Ascendante Hiérarchique
Nous construisons une CAH en utilisant notre distance
∆
pour notre sous-échantillon ,. Pour
cela, nous suivons l’algorithme de Johnson, la distance entre deux classes étant fixée comme la plus
grande distance des éléments de ces classes. Nous observons une forte asymétrie dans la CAH obtenue :
jX nj ,...,1=

Figure 2
Nous formons classiquement les classes ,jC Jj
∈
de courbes en regroupant les feuilles descendantes d’un
même noeud. Nous résumons l’information de chaque classe grâce à un représentant (appelé
archétype) :
j
C
∑
∈
∈
∆=
j
jCX
CX
jXX
'
(
minarg X, )' , qui est la courbe la plus proche du barycentre du groupe.
D’autres choix sont possibles (médiane…).
3 Optimisation et apprentissage
3.1 Optimisation multicritères
Nous supposons que l’ensemble des archétypes résume convenablement l’information apportée par les
observations. Mais cet ensemble est grand, le nombre de classes J de l’arbre étant élevé. Nous allons
rechercher à conserver le maximum d’information dans le plus petit sous-ensemble d’archétypes possible.
Pour cela, nous nous entraînons sur l’échantillon d’apprentissage en nous ramenant à un programme
d’optimisation multicritères. Nous devons trouver l’ensemble d’indices J⊂
Λ
qui minimise
- La précision : ),(
1
1min j
i
N
ij
XY
N∆− ∑
=Λ∈
- La généralité :
Λ

3.2 Présentation succincte de l’algorithme
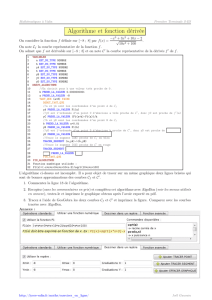
Nous ne pouvons pas nous permettre de tester la totalité des sous-ensembles
Λ
possibles. Un algorithme
nous permet d’en faire une sélection. Il consiste à itérer deux étapes jusqu’à obtenir un recouvrement
convenable des courbes ( { ,
j
jC
Λ∈
U≈j
X nj ,...,1
=
}):
- Choix d’une feuille : nous choisissons une courbe notée F parmi , qui maximise
les critères d’une pondération.
jX nj ,...,1=
- Choix d’une classe : nous choisissons dans l’arborescence de la feuille F le nœud (et donc la
classe C) qui minimise le critère : CFX
µµ
−∆− ),()1( , où
X
est l’archétype de C.
X
est alors
rajouté à notre sous-ensemble
Λ
. Puis nous mettons à jour la pondération de l’ensemble des
feuilles.
La pondération est primordiale, elle permet en particulier de sélectionner à la première étape des feuilles
qui sont éloignées de tous les archétypes déjà sélectionnés, tout en évitant de ne sélectionner que les
outliers.
3.3 Apprentissage
L’algorithme dépend essentiellement du paramètre
µ
: à
µ
fixé, nous sélectionnons toujours les mêmes
archétypes. Nous faisons alors varier notre paramètre jusqu’à obtenir un opt
Λ
tel qu’il n’existe pas
d’autres candidats qui décrivent plus précisément l’échantillon d’apprentissage :
),(
1
minarg
1min j
i
N
ij
opt XY
N∆=Λ ∑
=Λ∈
µ
.
3.4 Comparaison avec la méthode classique
Habituellement, le choix du meilleur ensemble de classes dans la CAH se fait en coupant l’arbre au niveau
optimal et en gardant les classes correspondantes. Ainsi, seuls les sous ensembles constitués de nœuds (et
donc de classes) d’un même niveau dans la CAH sont considérés. Le problème de cette méthode est que
toutes les branches de l’arbre sont traitées de la même manière.
Nous comparons cette méthode classique avec la notre grâce à l’échantillon test. Le tableau ci-dessous
présente la moyenne, l’écart type, le minimum et le maximum des quantités ),(min j
i
jXZ∆
∆∈ :
Méthodes Moyenne Ecart type Min. Max.
Niveau de coupe fixe 0.43 5.0 18 28
Multiobjectif 0.34 4.2 18 19
Tableau 1
Nous obtenons de meilleurs résultats que la méthode classique. Nous appliquons notre méthode au trafic
routier. A une date T et une heure H, nous disposons de l’historique du trafic aux dates 1,…,T-1. Nous
obtenons un résumé optimal de cet ensemble de courbes grâce à notre algorithme. Puis nous estimons la
vitesse en H+1 en choisissant l’archétype le plus proche aux heures 0,…,H de la courbe en T et en prenant
la vitesse de cet archétype en H+1.
4 Bibliographie
[GLM 04] GAMBOA F., LOUBES J.M., MAZA E., Structural estimation for high dimensional data,
submitted to Annals of Statistics, 2004.
[LLM 04] LAVIELLE M., LOUBES J.M., and MAZA E , Classification and forecasting in travel time,
submitted to Canadian Journal of Statistics, 2004.
1
/
4
100%