Comment la Souris fait de la souris … … avec des graines ?

Comment la Souris fait de la souris …
… avec des graines ?
d’après « 10 clés pour la Biologie » de J. Tavlitzki
« […] La Souris, l’Ecureuil, le Lapin mangent des graines. La Souris fait de la souris, l’Ecureuil fait de l’écureuil, et le Lapin
fait du lapin, tous avec les mêmes graines…
Autrement dit, le principe général est que les êtres vivants sont dotés de la capacité extraordinaire de transformer les éléments
qui leur sont étrangers en leurs propres constituants. Comment peuvent-ils le faire ? Comment la Souris fait de la souris avec
des graines ?.
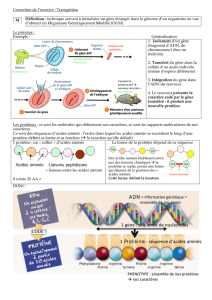
La Souris mange des graines, elle les ronge, les réduit en fines particules. Au cours de la digestion, les grosses molécules
organiques sont simplifiées. Chaque cellule va en assimiler des nutriments, notamment des acides aminés. Ceux ci seront à la
base de la constitution de protéines, mais pas n’importe lesquelles. Chaque cellule refait les protéines qui lui sont spécifiques.
Cela veut dire que chaque cellule dispose du plan de construction, d’un ‘programme souris’ qui lui a été transmis et à partir
duquel les acides aminés pourront être agencés en protéines spécifiques. »
Quand la Souris fait de l’humain !
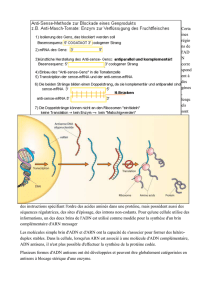
Expérience de transgénèse : La transgénèse est une technique permettant de transférer un gène d’une espèce donneuse à une
espèce receveuse.

Laboratoire de Sciences de la Vie et de la Terre Première S
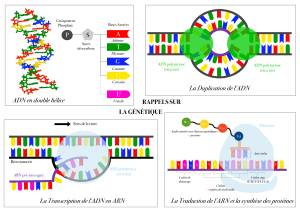
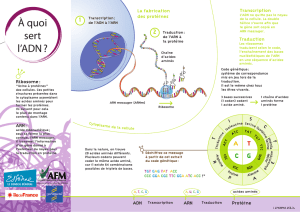
Un gène, une protéine
Durant les phases G1 et G2 de l’interphase, la cellule est en phase de croissance. Les cellules, sous le contrôle de leur
patrimoine génétique, produisent une multitude de protéines, véritables acteurs du métabolisme.
Ce laboratoire vise à mettre en évidence les relations entre protéines et ADN. Il devient alors possible de comprendre
comment la production des protéines spécifiques de l’individu est dirigée par l’ADN.
Votre mission : Comprendre l’hypothèse, devenue célèbre, exposée dès 1940 par Beadle et Tatum : ‘Un gène, une
protéine’.
Partie 1 : Analyse de la structure d’une protéine enzymatique simple
Chez les vertébrés, par exemple, les globules rouges possèdent dans leur cytoplasme de l’hémoglobine, une protéine
complexe qui permet de fixer et de transporter le dioxygène dans l’organisme (Visionner le film sur clé USB :
datas/genetique/ hemoglobine).
Ouvrir le logiciel ‘MolUSc’ (qui permet de visualiser et traiter des données moléculaires) et sélectionner dans le
dossier ‘app/molecules’ le fichier relatif à l’hémoglobine : ‘1GZX_hemoglobine.pdb’. Appelez le professeur..
En vous aidant de la fiche technique de MollUSc, sélectionner une des chaines de l’hémoglobine (chaîne B ou D),
afficher cette chaine, identifier le dernier acide aminé et en déduire le nombre d’acides aminés de cette chaine et la
séquence de la chaine pour les 10 premiers acides aminés (la succession des acides aminés d’une chaine constitue sa
séquence). Appelez le professeur.
sur votre compte rendu :
Imprimer la chaine étudiée (édition > exporter > images). Légendez l’image de la molécule traitée en mettant en
évidence les premiers et dernier acides aminés.
Partie 2 : La relation entre séquence des acides aminés et séquence de nucléotides
La synthèse de l’hémoglobine, comme pour toutes les protéines, est sous le contrôle du programme génétique de la
cellule. Une portion d’ADN (séquence de nucléotides) appelée ‘gène’ dirige la synthèse de chaque chaine de
l’hémoglobine (séquence d’acides aminés).
Ouvrir le logiciel ‘Anagène’ (qui permet d’afficher et de traiter les séquences) et sélectionner dans la banque de
séquences (chaîne de l’hémoglobine) les molécules qui nous intéressent : beta.pro (acides aminés de la chaine
globine) et betacod.adn (nucléotides de la chaine globine). Le logiciel superpose les séquences des deux molécules
(nucléotides d’un brin d’ADN identifiés par une lettre, et acides aminés de la protéine identifiés par un nom en trois
lettres). Appeler le professeur.
sur votre compte rendu :
Retrouver sur le logiciel la longueur des deux molécules (nombre de nucléotides et nombre d’acides aminés)..
Retranscrire la séquence des onze premiers acides aminés et la séquence correspondante de l’ADN (attention retouver
les deux brins constitutifs de l’ADN). Quelle relation pouvez-vous établir entre gène et protéine à ce stade de l’étude ?
Quelle peut être la fonction du dernier triplet de nucléotides ?
Partie 3 : Les molécules mises sous surveillance… radioactive
L’information nécessaire à l’assemblage des acides aminés d’une protéine est donc portée par l’ADN, localisé dans le
noyau des cellules. On s’interroge sur les lieux où vont se dérouler l’assemblage des acides aminés dans la cellule.
Prendre connaissance des résultats de biologie moléculaire en annexe. Revenir sur Anagene et sur MolUSc pour
comparer les molécules d’ADN et d’ARN (betacod.adn, betacod.arn pour Anagene – adn_c.pdb et arn .pdb pour
molUSc).
sur votre compte rendu :
Analyser les documents et montrer en quoi les études sur l’ARN, un acide nucléique proche de l’ADN, permet
d’imaginer un transfert de l’information génétique du noyau vers le cytoplasme. Aidez vous du film sur la clé USB :
datas/genetique/synthese_proteique
Comparer un fragment d’ADN et d’ARN (composition, structure, séquence) avec les logiciels disponibles
Réaliser des schémas pour rendre compte des points communs et des différences entre les deux molécules
Employer
des techniques
d’observation
Utiliser
des techniques
bio ou géologiques
Utiliser
des modes de
représentation
Adopter
une démarche
explicative
Compétences
personnelles

Documentation : Les molécules mises sous surveillance… radioactive
L’information nécessaire à l’assemblage des acides aminés d’une protéine est portée par l’ADN, localisé dans le noyau des cellules.
On s’interroge sur les lieux où se déroulent l’assemblage des acides aminés dans la cellule.
Les documents ci-dessous (s’intéressent à la localisation de l’ADN dans la cellule.
Document 1 : Coloration d’une cellule au vert de méthyle-pyronine
Les cellules contiennent des molécules chimiquement très
proches de l’ADN, appelées ARN (acide ribonucléique). Le
vert de méthyle-pyronine, mélange de deux colorants,
permet de mettre en évidence d’une part l’ADN, d’autre part
l’ARN ; le vert de méthyle colore l’ADN en bleu-vert et la
pyronine colore l’ARN en rose.
La photographie ci contre présente des cellules du pancréas.
Ce sont des cellules qui produisent des protéines en grande
quantité.
Seuls les noyaux présentent une coloration bleu-vert. La
coloration rose se constate par contre dans toute la cellule
(cytoplasme + noyau).
Document 2 : L’ARN, un acide nucléique proche de l’ADN
Les molécules ARN sont chimiquement proches de l’ADN. Comme ce dernier, ils résultent de l’assemblage de nucléotides. Leur
structure diffère sur plusieurs points :
- le sucre n’est pas du désoxyribose mais du ribose.
- la thymine (T) de l’ADN est remplacée par l’uracile (U).
- la molécule n’est formée que d’une chaine de nucléotides (molécule monobrin)
- les molécules d’ARN sont de longueur nettement inférieure à celle de l’ADN.
Document 3 : Traçage radioactif de l’ARN dans la cellule
Les deux radiographies ci contre présentent des autoradiographies de cellules qui
sont cultivée en présence d’un précurseur radioactif spécifique de l’ARN. Chaque
tache noire repère un endroit où se trouve de l’ARN ayant incorporé le présurseur
radioactif.
Le cliché a présente l’autoradiographie d’une cellule après 15 minutes de culture
sur un milieu contenant le précurseur radioactif de l’ARN.
Le cliché b correspond à l’autoraradiographie d’une cellule qui a été d’abord
cultivée pendant 15 minutes sur un milieu contenant un précurseur radioactif de
l’ARN puis pendant une heure et demie sur un milieu contenant des précurseurs
non radioactifs de l’ARN.
d’après travaux de Brachet - 1951
Document 4 : Localisation du lieu d’assemblage des acides aminés
Pour déterminer le lieu où s’effectue la synthèse protéique, on utilise des Acétabulaires, algues unicellulaires de très grande taille (5
à 10 cm de haut à l’âge adulte). Ces algues sont mises en présence d’un acide aminé radioactif : la méthionine (MET).
Après 30 mn, l’autoradiographie montre le résultat schématisé ci dessous.
Le résultat serait identique si les algues étaient ensuite replacées pendant 3 h dans un milieu « froid » (càd non radioactif)

Laboratoire de Sciences de la Vie et de la Terre Première S
Un gène, une protéine
Votre mission : Comprendre l’hypothèse, devenue célèbre, exposée dès 1940 par Beadle et Tatum : ‘Un gène, une
protéine’.
Partie 1 : Analyse de la structure d’une protéine enzymatique simple
Ouvrir le logiciel ‘MolUSc’
La molécule choisie (l’hémoglobine humaine apparait en représentation : ‘boules et bâtons’
Cette protéine est faite de quatre chaines d’acides aminés distinctes. Le logiciel permet de les visualiser, de changer leur
représentation, leur couleur … Plusieurs options du logiciel permettent d’arriver au résultat suivant :
Les quatre chaines de l’hémoglobine identifiées par une couleur
La chaine D de la béta globine isolée (par effacement progressif des trois autres chaines)
On demande de travailler sur une des chaines (béta globine soit chaine B ou D). Le logiciel permet de n’afficher qu’une
des chaines. Voir ci-dessus.
On traite alors la séquence des acides aminés qui la composent (par le mode séquence) et/ou l’affichage des acides
aminés. (soit HIS : histidine)

Un travail similaire peut être fait pour identifier les dix premiers acides aminés de la chaine
On en déduit la séquence des dix premiers acides aminés :
VAL-HIS-LEU-THR-PRO-GLU-GLU-LYS-SER-ALA…
Le dernier acide amine de la chaine est : HIS
La longueur de la chaine est de 146 a.aminés.
Chaine béta de l’hémoglobine (146 a.a)
Partie 2 : La relation entre séquence des acides aminés et séquence de nucléotides
Ouvrir le logiciel ‘Anagène’ et les séquences demandées
On retrouve pour le brin d’ADN : 444 nucléotides, et pour la chaine d’acides aminés : 147 acides aminés.
On constate que la chaine peptidique finit bien par l’histidine : HIS mais commence différemment (méthionine MET).
On constate enfin que chaque triplet de nucléotide correspond à un acide aminé sauf le dernier triplet de nucléotide.
Début de la chaine : 10 premiers acides
aminés
fin de la chaine : dernier acide aminé
 6
7
8
9
10
11
6
7
8
9
10
11
1
/
11
100%