chiffre

Analyse lexicale
Généralités
Expressions rationnelles
Automates finis
Analyseurs lexicaux

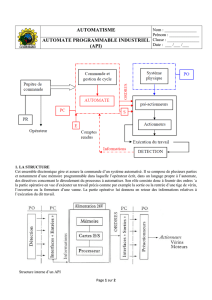
Rôle d'un analyseur lexical
code source
lexèmes
...
analyseur
lexical analyseur
syntaxique
table des
symboles
Séparer l'analyse lexicale de l'analyse syntaxique
Réduire la complexité du compilateur et la complexité de
conception de ces deux modules
Augmenter la flexibilité du compilateur : portabilité,
maintenabilité
Augmenter l'efficacité du compilateur

Méthodes de construction
Utiliser un générateur d'analyseurs lexicaux
(Flex)
Ecrire l'analyseur lexical dans un langage
évolué

Lecture du code source (1/2)
On utilise un tampon de lecture cyclique en deux moitiés
Anticiper = lire quelques caractères d'avance pour décider la valeur du
lexème en cours
... a = 4 * i + 1 ...
debut
fin
Une anticipation de quelques caractères suffit
Un langage où il n'y avait pas de limite à la taille de l'anticipation : PL/1
DECLARE ( ARG1, ARG2, ... , ARGn)
Il faut attendre la fin de l'expression pour savoir si DECLARE est un mot-
clé ou un nom de tableau

Lecture du code source (2/2)
... a = 4 * i + 1 ...
debut
fin
si fin atteint la fin de la première moitié
alors { charger la deuxième moitié
fin := fin + 1 }
sinon si fin atteint la fin de la deuxième moitié
alors { charger la première moitié
fin := 0 }
sinon fin := fin + 1
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
1
/
30
100%