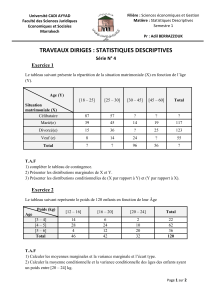
Statistique élémentaire avec R Partie 2 : Test d`hypothèses et

Statistique élémentaire avec R
Partie 2 : Test d’hypothèses et régression linéaire
Julien JACQUES
Université Lumière Lyon 2
1/48


Plan
Tests d’hypothèses
Principe d’un test statistique
Typologie des tests statistiques
Tests de liaison entre variables
Tests de comparaison de populations indépendantes
Régression linéaire
La régression linéaire simple
La régression linéaire multiple
Tests sur le modèle de régres sion linéair e
Prédiction
Détection d’observations atypiques
3/48

Principe d’un test statistique
Un exemple
1. Test H0:µ=µ0contre H1:µ̸=µ0
2. Stat. de test T=¯
X−µ0
S
√n∼H0tn−1Student à n-1 degrés de liberté
3. α=5%
4. Zone de rejet W={¯
x:|t|=|¯
x−µ0|
s
√n
>−tn−1,α
2}
-4 -3 -2 -1 0 1 2 3 4
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
α 2
2
α
α 1−α
t t
2 2
5. calcul de t puis acceptation de H0si t est entre les bornes, rejet sinon
4/48

Principe d’un test statistique
Les étapes
1. Identifier des hypothèses H0(hyp. nulle, simple)etH1(hyp. alternative, composite)
2. Définir un statistique de test T,dontlaloiestdifférentesousH0et H1
3. Choisir un risque de première espèce α(5%,10%...)
4. Définir la zone de rejet Wde H0,enfonctiondeH1(test uni- ou
bilatéral) et de α
5. Calculer la valeur tde la statistique de test T
6. Conclure au rejet de H0si t∈Woù à son acceptation dans le cas
contraire
5/48
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
1
/
49
100%