Régression logistique et modèle de Cox

Régression logistique et
modèle de Cox
Jean-François TIMSIT
Réanimation médicale
INSERM/UJF U823
CHU Albert Michallon
Grenoble
Paris, SRLF Janvier 2009

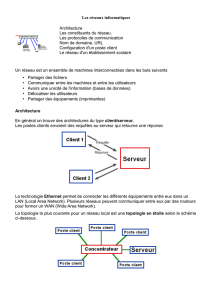
•747 patients ventilés plus de 48 heures
•153 au moins une PNVM
•Question:
–Parmi les variables age, sexe, utilisation de
cephalosporines dans les 48 premières heures
de VM lesquels sont des facteurs de risque de
PNVM??
Outcomes of VAP • CID 2004:38 (15 May) • 1401

Les variables
•DSREA: durée de séjour en réanimation
•SEXMASC: sexe masculin
•Age (année)
•PN (0/1)
•EOP/LOP (<7 j, >=7jours)
•CEPHALO48: utilisation de céphalosporines dans
les 48 premières heures de séjour

010 20 30 40 50 60 70 80 90 100
250
200
150
100
50
0
AGE
Frequency
Variable : AGE
Sample size = 747
Lowest value = 16,5257
Highest value = 100,0000
Arithmetic mean = 65,3941
95% CI for the mean = 64,3005 to 66,4878
Median = 68,7817
95% CI for the median = 67,1589 to 69,7324
Variance = 231,5221
Standard deviation = 15,2158
Relative standard deviation = 0,2327 (23,27%)
Standard error of the mean = 0,5571
Coefficient of Skewness = -0,7248 (P<0,0001)
Coefficient of Kurtosis = 0,0229 (P=0,8308)
Kolmogorov-Smirnov test
for Normal distribution : reject Normality (P<0,001)
Percentiles 95% Confidence Interval
2,5 = 30,3368 27,5104 to 32,9601
5 = 34,7625 32,1306 to 38,4000
10 = 42,3387 40,3694 to 44,8183
25 = 56,4435 53,6353 to 58,6242
75 = 76,5914 75,5473 to 77,2365
90 = 82,3691 80,5334 to 84,2325
95 = 86,1684 84,7553 to 87,5371
97,5 = 88,6290 87,1381 to 90,4577

Variable DS rea
Variable : DSREA
Sample size = 747
Lowest value = 2,0000
Highest value = 111,0000
Arithmetic mean = 16,4712
95% CI for the mean = 15,2883 to 17,6541
Median = 11,0000
95% CI for the median = 10,0000 to 12,0000
Variance = 271,2147
Standard deviation = 16,4686
Relative standard deviation = 0,9998 (99,98%)
Standard error of the mean = 0,6026
Coefficient of Skewness = 2,2130 (P<0,0001)
Coefficient of Kurtosis = 6,0827 (P<0,0001)
Kolmogorov-Smirnov test
for Normal distribution : reject Normality
(P<0,001)
Percentiles 95% Confidence Interval
2,5 = 2,0000 2,0000 to 2,0000
5 = 3,0000 2,0000 to 3,0000
10 = 3,0000 3,0000 to 4,0000
25 = 6,0000 5,0000 to 6,0000
75 = 21,0000 19,0000 to 23,0000
90 = 37,8000 33,0000 to 44,0000
95 = 51,1500 45,0000 to 58,0000
97,5 = 62,8250 57,0000 to 71,0353
010 20 30 40 50 60 70 80 90 100 110 120
350
300
250
200
150
100
50
0
dsrea
Frequency
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
1
/
53
100%