Client Serveur

CLIENT/SERVEUR

Partie 1 : Présentation du modèle client-serveur
CLIENT/SERVEUR

Un peu d'histoire…….
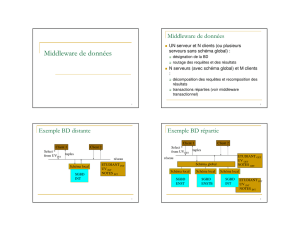
Le client serveur est l'état actuel de l'évolution
des architectures informatiques :
•Avant les Années 80 : Système Centralisé
(ordinateur central avec des terminaux passifs
de type texte).
•Les Années 80 : Développement du
transactionnel et apparition des SGBD non-
propriétaires (indépendants des
constructeurs) - SGBD relationnel + SQL

Un peu d'histoire…….
•Les Années 80 : Parallèlement développement
des micros-ordinateurs avec leur puissance de
calcul décentralisée et leurs interfaces
graphiques conviviales.
Le maintien des gros et moyens systèmes avec
les micros-ordinateurs ont rendu les
communications difficiles et ont créé des
désordres dans les systèmes d'informations
(redondance,etc.)

Un peu d'histoire…….
•Les Années 90 : Développement des réseaux.
L'efficacité et le partage des systèmes
d'informations doivent être optimum
(concurrence économique, etc.).
Le client-serveur se situe dans ce besoin de
centralisation (information cohérente, non
redondante et accessible) et de
décentralisation (conserver la puissance et
l'interface des micros-ordinateurs)
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
1
/
81
100%