l`analyse prédictive

par Daniel D. Guerrez
Guide InsideBIGDATA de
l’analyse prédicve
PRÉSENTÉ PAR

www.insidebigdata.com | 508-259-8570 | [email protected]om
Guide de l’analyse prédicve
2
L’analyse prédicve moderne est née dans les an-
nées 1940, lorsque les gouvernements ont commencé
à employer les premiers modèles informaques (simu-
laons de Monte-Carlo, modèles informaques pour
réseaux de neurones, programmaon linéaire) pour
décoder les messages allemands pendant la Deuxième
guerre mondiale, à automaser le ciblage des armes
anaériennes ulisées contre les avions ennemis et à
recourir aux simulaons informaques pour prédire le
comportement des réacons nucléaires en chaîne du
projet Manhaan. Dans les années 1960, les entreprises
et les établissements de recherche sont entrés dans l’ère
de la commercialisaon de l’analyse avec la programma-
on non linéaire, et de la résoluon heurisque de pro-
blèmes via l’informaque : premiers modèles capables
de prévoir les condions météorologiques, résoudre le
« problème du plus court chemin » pour améliorer les
quesons de transport aérien et de logisque et appli-
quer la modélisaon prédicve aux demandes de cré-
dit en foncon des risques. Puis dans les années 1970–
1990, l’analyse a été ulisée de façon plus répandue dans
les entreprises et l’analyse prescripve en temps réel est
devenue réalité dans les startups technologiques. Toute-
fois, l’analyse prédicve est largement restée l’apanage
des stasciens et n’a été introduite dans le monde des
aaires que via des rapports staques par lots.
Aujourd’hui, l’analyse prédicve a nalement inves la
majorité des entreprises, qui y ont recours au quodien
dans des cas d’ulisaon toujours plus nombreux. Ce
phénomène de plus en plus répandu a été engendré par
les réalités d’une économie mondiale, les entreprises
n’ayant de cesse de se constuer un avantage concur-
renel, et il a pu se développer grâce à d’importantes
innovaons technologiques.
Ces innovaons regroupent notamment des perfor-
mances informaques plus évoluves, les bases de don-
nées relaonnelles, les nouvelles technologies Big Data
comme Hadoop et les logiciels d’analyse en libre service
qui placent les données et les modèles prédicfs entre
les mains des décideurs de premier plan. Tout cela a per-
mis aux entreprises de rester en concurrence sur fond
d’innovaon analyque.
Tout d’abord, les entreprises ont adopté l’analyse simple
et la découverte des données pour comprendre l’état de
leurs acvités et examiner en profondeur les données
an de comprendre les « pourquoi » cachés derrière ces
dernières. En se familiarisant pet à pet avec leurs don-
nées, elles comprennent qu’il est possible de dépasser
encore leurs concurrents grâce à l’analyse avancée.
Histoire de l’analyse prédicve
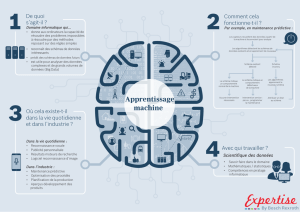
Dénion de l’analyse prédicve
L’analyse prédicve, parfois appelée analyse
avancée, est un terme ulisé pour décrire une
série de techniques analyques et stasques
permeant de prédire des acons ou des com-
portements futurs. Dans les entreprises, l’ana-
lyse prédicve est ulisée pour prendre des déci-
sions proacves et déterminer des acons, au
moyen de modèles stasques permeant de
découvrir des schémas dans des données histo-
riques et transaconnelles, dans le but d’iden-
er des risques potenels et des opportunités.
L’analyse prédicve intègre plusieurs acvités
que nous allons explorer dans le présent docu-
ment : l’accès aux données, l’analyse explora-
toire des données et la visualisaon, l’élabora-
on d’hypothèses et de modèles de données,
l’applicaon de modèles prédicfs, ainsi que l’es-
maon et/ou la prédicon de résultats futurs.
Sommaire
Dénion de l’analyse prédicve ...... 2
Histoire de l’analyse prédicve ........ 2
Ulisaons méer de l’analyse
prédicve ......................... 3
Les classes dans l’analyse prédicve ... 4
Les logiciels d’analyse prédicve ...... 6
R : le logiciel de choix pour l’analyse
prédicve .......................... 7
L’accès aux données pour l’analyse
prédicve .......................... 8
L’analyse exploratoire des données .... 8
La modélisaon prédicve ..........10
Le déploiement en producon ....... 11
Conclusion ........................ 11

www.insidebigdata.com | 508-259-8570 | [email protected]om
Guide de l’analyse prédicve
3
Il est évidemment nécessaire d’uliser l’analyse prédicve
dans l’entreprise, car elle ore une analyse plus intelligente,
qui permet d’opmiser les prises de décision, d’accroître la
compévité sur le marché, d’envisager plus directement
les opportunités du marché et les menaces, de réduire l’in-
certude et de gérer les risques, d’amener une approche
de planicaon et d’acon proacves, de découvrir des
schémas judicieux et des moyens d’anciper et de réagir
aux tendances émergentes.
L’analyse quantave avancée a prouvé sa pernence dans
de très nombreux secteurs et domaines représentafs. De
nombreux problèmes de l’entreprise peuvent être résolus,
dans diverses catégories, grâce à l’analyse prédicve. En
voici quelques exemples :
• Prévisions des ventes : elles prédisent ce que vous pou-
vez aendre tel mois ou tel trimestre, en foncon de
l’historique de vos taux de conversion, autrement dit ce
qu’a été le pourcentage de gains de votre équipe com-
merciale par le passé pour des opportunités similaires,
en combinaison avec le pipeline des ventes actuelles,
c’est-à-dire le nombre d’opportunités sur lesquelles tra-
vaille votre équipe sur la période considérée.
• Détecon des fraudes : permet de repérer les de-
mandes de crédit inappropriées, les transacons frau-
duleuses réalisées hors ligne et en ligne, les usurpaons
d’identé, les fausses demandes d’indemnisaons, etc.
• Opmisaon des campagnes de vente : permet aux
vendeurs de modéliser les résultats des campagnes sur
la base d’une analyse approfondie des comportements,
des préférences et des données de prol des clients.
• Analyse markeng et clientèle : recueille des données
issues du markeng numérique, des médias sociaux,
des centres d’appels, des applicaons mobiles, etc.
et ulise les informaons relaves à ce qu’ont fait les
clients dans le passé pour évaluer ce qu’ils vont faire
dans le futur.
• Analyse RH : permet aux entreprises d’analyser le
passé et de regarder vers le futur an de repérer des
tendances dans les facteurs clés liés aux départs volon-
taires, aux absences et autres sources de risque, ainsi
que d’idener des tendances dans les compétences
requises par rapport aux ressources ulisées.
• Geson des risques : permet de prédire le meilleur
portefeuille an de maximiser le retour sur le modèle
d’évaluaon des acfs nanciers et l’évaluaon des
risques de probabilité pour générer des prévisions
exactes.
Le cœur de l’analyse prédicve se fonde sur la capture
des relaons entre des points de données issues du
passé et sur l’ulisaon de ces relaons pour prédire les
En maère de prévision des ventes, l’analyse prédicve fournit des réponses ciblées pernentes à un
vaste éventail d’ulisateurs méer an de les aider à améliorer les prises de décision. Image reproduite
avec l’aimable autorisaon de TIBCO Spoire.
Ulisaons méer de l’analyse prédicve

www.insidebigdata.com | 508-259-8570 | [email protected]om
Guide de l’analyse prédicve
4
résultats futurs. An de pouvoir faire des prédicons
sur la base d’un ensemble de données spécique,
on ulise une ou plusieurs variables prédicves pour
prédire une variable réponse. Sous sa forme la plus
simple, l’analyse prédicve est un support permet-
tant d’établir des prévisions pour la prise de décision
en entreprise. Pour des exigences plus complexes,
on ulise des techniques d’analyse prédicve avan-
cées an d’orienter les processus stratégiques de
l’entreprise. Cee secon vous présente une vue
d’ensemble des principales catégories de l’analyse
prédicve : l’apprenssage supervisé et l’apprens-
sage non supervisé.
L’apprenssage supervisé est divisé en deux grandes
catégories : la régression pour les réponses quan-
taves (une valeur numérique), par exemple le
nombre de kilomètres par litre d’essence pour une
voiture donnée, et la classicaon pour les réponses
qui peuvent uniquement prendre quelques valeurs
connues, telles que « vrai » ou « faux ».
• Régression : la régression est la forme la plus
courante de l’analyse prédicve. Elle fait inter-
venir une variable réponse quantave (ce que
vous tentez de prédire), par exemple le prix de
vente d’une maison, selon une série de variables
prédicves (nombre de mètres carrés, nombre
de chambres, revenus moyens dans le voisinage
selon les données de recensement...). La rela-
on entre le prix de vente et les prédicteurs de
l’ensemble d’apprenssage fournirait un modèle
prédicf.
Les méthodes de régression, y compris celles
menonnées ci-dessus, sont nombreuses : ré-
gression linéaire mulvariée, régression polyno-
miale, arbres de régression, pour n’en citer que
quelques-unes.
• Classicaon : la classicaon est un autre
type d’analyse prédicve communément u-
lisé. Elle fait intervenir une variable réponse
qualitave, par exemple l’échelle salariale, qui
peut être partagée en trois classes ou catégo-
ries : salaire élevé, salaire moyen et bas salaire.
Cee méthode examine un ensemble de don-
nées dans lequel chaque observaon conent
des informaons sur la variable réponse ainsi
que sur les variables prédicves. Supposons
qu’un analyste souhaite pouvoir classier
l’échelle salariale de personnes n’appartenant
pas à l’ensemble de données, en foncon des
caractérisques associées à ces personnes, par
exemple l’âge, le sexe et la profession. Cee
tâche de classicaon se déroulerait de la ma-
nière suivante : examiner l’ensemble de don-
nées contenant les variables prédicves et la
variable réponse déjà classiée, l’échelle sala-
riale. L’algorithme apprend ainsi les combinai-
sons de variables associées à tel ou tel niveau
de l’échelle salariale. Cet ensemble de don-
nées est appelé l’ensemble d’apprenssage.
L’algorithme examinerait ensuite les nouvelles
observaons pour lesquelles aucune infor-
maon sur l’échelle salariale n’est disponible.
Sur la base des classicaons dans l’ensemble
d’apprenssage, l’algorithme aribuerait des
classicaons aux nouvelles observaons. Par
exemple, une directrice markeng de 51 ans
pourrait être classée dans l’échelon des reve-
nus élevés.
Les types de méthodes de classicaon sont
nombreux : régression logisque, arbres de
décision, machines à vecteurs de support,
forêts aléatoires, k plus proches voisins, naïve
bayésienne, etc.
L’apprenssage non supervisé permet de rer des
conclusions à parr d’ensembles de données compo-
sés de données en entrée sans réponses équetées.
La méthode d’apprenssage non supervisé la plus
Les classes dans l’analyse prédicve
La régression est la forme la plus
courante de l’analyse prédicve. Elle
fait intervenir une variable réponse
quantave (ce que vous tentez de
prédire).
La classicaon est un autre type
d’analyse prédicve communé-
ment ulisé. Elle fait intervenir une
variable réponse qualitave. Cee
méthode examine un ensemble de
données dans lequel chaque obser-
vaon conent des informaons sur
la variable réponse ainsi que sur les
variables prédicves.

www.insidebigdata.com | 508-259-8570 | [email protected]om
Guide de l’analyse prédicve
5
courante est l’analyse de clusters, qui est ulisée pour
l’analyse exploratoire des données an de trouver des
schémas cachés ou des groupes de données.
• Clustering : les techniques non supervisées
comme le clustering nous aident à comprendre
les relaons entre les variables ou entre les ob-
servaons en déterminant si elles tombent dans
des groupes relavement disncts. Par exemple,
dans une analyse de segmentaon de la clien-
tèle, nous pouvons observer plusieurs variables :
sexe, âge, code postal, revenus, etc. Nous pen-
sons que les clients tombent dans diérents
groupes, comme les acheteurs fréquents et les
acheteurs occasionnels. Une analyse par clas-
sicaon serait possible si l’historique d’achat
des clients était disponible, mais cela n’est pas
le cas avec l’apprenssage non supervisé ; nous
ne disposons pas de variables réponse indiquant
si un client est ou non un acheteur fréquent. En
revanche, nous pouvons tenter de regrouper les
clients en foncon des variables an d’idener
des groupes de clients disncts.
Il existe d’autres types d’apprenssage stas-
que non supervisé, notamment le clustering
par les k-moyennes, le groupement hiérar-
chique, l’analyse en composantes principales,
etc.
Le clustering montre les relaons entre les variables ou entre les observaons en déterminant si elles tombent
dans des groupes relavement disncts. Image reproduite avec l’aimable autorisaon de TIBCO Spoire.
 6
7
8
9
10
11
6
7
8
9
10
11
1
/
11
100%