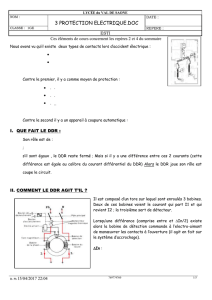
Architecture synchronisée par les données pour syst`eme

Facult´
e des Sciences Appliqu´
ees
Laboratoire de Micro´
electronique
Architecture synchronis´ee par les
donn´ees pour syst`eme
reconfigurable
Jean Pierre DAVID
Th`ese soutenue en vue de l’obtention du grade de
Docteur en Sciences Appliqu´ees
Composition du jury :
Prof. Jean-Didier Legat (UCL/DICE) - Promoteur
Prof. Jean-Luc Danger (ENST, Paris, France)
Prof. Christian Piguet (CSEM, Neuchˆatel, Suisse)
Prof. Jean-Jacques Quisquater (UCL/DICE)
Prof. Piotr Sobieski (UCL/TELE) - Pr´esident
Prof. Anne-Marie Trullemans (UCL/DICE)
Prof. Luc Vandendorpe (UCL/TELE)
Louvain-la-Neuve, Belgique
Juin 2002


Table des mati`eres
Table des figures 7
Remerciements 11
Chapitre 1. Introduction 13
Chapitre 2. Etat de l’art 23
1. Les processeurs orient´es flux de donn´ees 23
1.1. Introduction 23
1.2. La machine `a jetons uniques (flux de donn´ees statique) 28
1.3. La machine `a jetons color´es (flux de donn´ees dynamique) 30
1.4. La machine `a stock de jetons explicite 32
2. Les architectures reconfigurables `a grain large 32
2.1. Introduction 32
2.2. Les architectures sans processeur 35
2.2.1. ALFA 35
2.2.2. MATRIX 36
2.2.3. PipeRench 40
2.2.4. RaPiD 41
2.2.5. Xputer 44
2.3. Les architectures avec processeur 45
2.3.1. Chameleon 45
2.3.2. FPPA et E-FPPA 47
2.3.3. MorphoSys 50
2.3.4. Raw Machines 51
2.4. Une architecture particuli`ere 53
2.5. Conclusion 56
3. Les architectures reconfigurables `a grain fin 61
3.1. Introduction 61
3.2. Les FPGA fabriqu´es par Altera 64
3.3. Les FPGA fabriqu´es par Xilinx 67
3.4. Les syst`emes multi-FPGA 70
3.5. Conclusion 74
Chapitre 3. Une architecture nouvelle, utilisant des ”DDR” 77
3

4 TABLE DES MATI `
ERES
1. Introduction 77
2. Les cartes r´ealis´ees 79
2.1. La carte 400.000 portes 79
2.2. La carte Virtex 80
3. Une architecture synchronis´ee par les donn´ees 82
3.1. Du concept de r´eseau de P´etri aux DDR 82
3.2. Le protocole de synchronisation 86
3.3. Une biblioth`eque de DDR 91
3.3.1. Introduction 91
3.3.2. Les DDR de traitement de donn´ees 92
3.3.3. Les DDR de transfert de donn´ees 92
3.3.4. Les DDR de g´en´eration de donn´ees 96
3.3.5. Les DDR de stockage de donn´ees 99
3.3.6. Les DDR de test 105
3.3.7. Les DDR d’entr´ees/sorties 105
3.3.8. Les DDR sp´ecialis´ees 105
3.3.9. Conclusion 106
4. Conception d’une architecture DDR 106
4.1. Introduction 106
4.2. La m´ethode heuristique 108
4.3. Exemple d’application 110
5. L’environnement de d´eveloppement 113
5.1. Introduction 113
5.2. La saisie de l’architecture DDR 115
5.2.1. Les trois niveaux de hi´erarchie 115
5.2.2. Le format VHDL des DDR 116
5.2.3. Le logiciel de g´en´eration du VHDL 117
5.3. La simulation 118
5.4. Le test 120
5.5. Conclusion 121
Chapitre 4. Applications - R´esultats 123
1. Introduction 123
2. Un exemple simple avec les DDR : La convolution 125
2.1. Approche empirique 126
2.2. Approche bas´ee sur les DDR 128
3. Prototypage rapide 130
3.1. Un algorithme de watermarking 131
3.2. Un algorithme de cryptanalyse 133
4. Les DDR utilisateur : La transform´ee multi-r´esolution 135
5. Calcul parall`ele : application en robotique 137
5.1. Introduction 137

TABLE DES MATI `
ERES 5
5.2. Le module BDC 138
5.3. R´esultats 142
5.3.1. Caract´eristiques des sch´emas de calcul 142
5.3.2. Le robot APRA 143
5.3.3. Le robot PUMA 145
5.3.4. Un dernier sch´ema de calcul 147
5.4. Conclusion 147
6. Conclusion 149
Chapitre 5. Conclusion 153
1. Originalit´e 155
2. Avantages 156
3. Inconv´enients 157
4. Perspectives 158
5. L’avenir des syst`emes digitaux 159
Publications de l’auteur 161
R´ef´erences bibliographiques 163
Annexe 1 : Exemple de code VHDL 171
La synchronisation des DDR de traitement de donn´ees 171
La DDR additionneur 173
Annexe 2 : Exemple de C pour DDR 177
D´eclaration de la carte 177
D´eclaration des ressources 178
G´en´eration de l’architecture DDR 178
Annexe 3 : D´etail des cartes 181
La carte multi-FPGA 181
La carte PCI-VIRTEX 183
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
1
/
184
100%