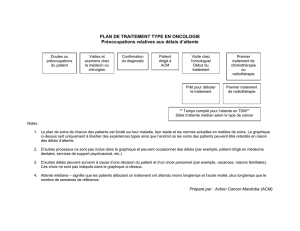
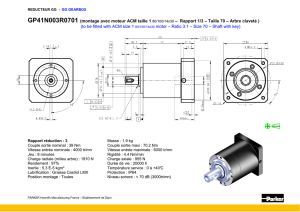
Stage Recherche (M2) : Nommage des clusters

Stage Recherche (M2) :
Nommage des clusters évoluant au cours du temps
Mathieu Roche1,Julien Velcin2,Pascal Poncelet1
(1) LIRMM & TETIS, Montpellier
(2) ERIC, Lyon
julien.velcin@univ-lyon2.fr
1 Contexte
Profitant des travaux précédents sur le clustering temporel (Rizoiu et al., 2014), sur l’extraction de terminologie pour
le data mining (Lossio-Ventura et al., 2015) et sur le résumé de flux de données (Pitarch et al., 2010), l’objectif des
travaux que nous proposons consiste à structurer dans le temps des données complexes (comportant en particulier une
dimension textuelle) tout en construisant la description (en particulier le vocabulaire) qui supporte cette structuration.
Contrairement à des approches tournées vers le suivi de termes ou de motifs, comme dans les travaux de (Leskovec et al.,
2009; Yang & Leskovec, 2011), l’idée est que la structure émerge d’un processus de clustering capable de prendre la
dimension temporelle en compte et qui favorise, par définition, les contrastes entre les catégories. Un type de catégories
qui sera privilégié est la catégorie thématique, dans la lignée de travaux précédents (Dermouche, 2014), mais d’autres
dimensions peuvent être intégrées comme les opinions ou la dimension géographique.
La dimension temporelle étant traitée de manière rétrospective, on se place résolument dans un cadre de clustering évo-
lutionnaire (evolutionary clustering) comme dans les travaux de (Mei & Zhai, 2005; Chakrabarti et al., 2006). C’est une
approche différente de celles des données en ligne (online) ou incrémentales, comme dans (Ienco et al., 2014). De plus,
l’approche rétrospective peut ouvrir la porte à des techniques pour éviter de découper arbitrairement la chronologie de
manière uniforme ou en fonction d’événements connus à l’avance (par exemple avec les change points).
Ce travail s’effectue dans le cadre du projet Songes (Science des Données Hétérogènes – Chercheurs d’avenir 2015 –
Région Languedoc Roussillon).
2 Travail à réaliser
Dans nos récents travaux menés conjointement entre l’équipe ADVANSE (LIRMM & TETIS) et le laboratoire ERIC (Lyon),
nous nous sommes intéressés à l’identification conjointe des descripteurs (et en particulier le vocabulaire) et des catégories.
Ceci permet de prendre en compte l’évolution des descripteurs au fil du temps mais également d’apporter une solution à
la sélection des meilleurs descripteurs parmi un très grand nombre possible (par exemple, apparition de nouveaux termes,
prise en compte des entités nommées, etc.). L’identification des descripteurs pertinents peut s’appuyer sur l’utilisation de
ressources sémantiques (Navigli & Ponzetto, 2012), de systèmes d’extraction de la terminologie (Lossio-Ventura et al.,
2015) ou de méthodes probabilistes (Blei et al., 2003).
Dans le contexte de ces travaux, le nommage (automatique) des classes construites au cours du temps est un problème
eminament difficile. Il repose à la fois sur des méthodes de fouille de données et de Traitement Automatique du Langage
Naturel (TALN). Par exemple, dans un contexte différent, des travaux sur le nommage ont été proposés en appliquant des
méthodes d’extraction de la terminologie et de génération de textes à partir d’articles de presse (Lopez et al., 2014).
Le stage proposé permettra de combiner les différentes approches précédemment citées qui sont fondées sur des méthodes
symboliques et statistiques afin de proposer une approche originale de nommage des clusters au cours du temps.
Le stage de recherche proposé s’articulera autour des tâches suivantes. Il s’agira, dans un premier temps, de compléter
l’état de l’art des approches les plus récentes ayant adopté une démarche similaire, puis d’identifier et d’adapter celles
permettant le nommage des clusters évoluant au cours du temps. Des expérimentations rigoureuses devront être réalisées

sur des données réelles.
Références
BLEI D. M., NGA. Y. & JORDAN M. I. (2003). Latent dirichlet allocation. J. Mach. Learn. Res.,3, 993–1022.
CHAKRABARTI D., KUMAR R. & TOMKINS A. (2006). Evolutionary clustering. In International conference on
Knowledge discovery and data mining, KDD ’06, p. 554–560 : ACM.
DERMOUCHE M. (2014). Modélisation des thématiques et des opinions dans les médias sociaux. PhD thesis, Université
de Lyon 2. Travaux en cours.
IENCO D., BIFET A., PFAHRINGER B. & PONCELET P. (2014). Change detection in categorical evolving data streams.
In Proceedings of SAC.
LESKOVEC J., BACKSTROM L. & KLEINBERG J. (2009). Meme-tracking and the dynamics of the news cycle. In
Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, p. 497–506 :
ACM.
LOPEZ C., PRINCE V. & ROCHE M. (2014). How can catchy titles be generated without loss of informativeness ?
Expert Systems with Applications,41(4, Part 1), 1051 – 1062.
LOSSIO-VENTURA J., JONQUET C., ROCHE M. & TEISSEIRE M. (2015). Biomedical term extraction : overview and
a new methodology. Information Retrieval Journal, to appear, p.˜
42.
MEI Q. & ZHAI C. (2005). Discovering evolutionary theme patterns from text : an exploration of temporal text mining.
In Proceedings of the eleventh ACM SIGKDD international conference on Knowledge discovery in data mining, p.
198–207 : ACM.
NAVIGLI R. & PONZETTO S. P. (2012). Babelnet : The automatic construction, evaluation and application of a wide-
coverage multilingual semantic network. Artificial Intelligence,193, 217 – 250.
PITARCH Y., LAURENT A. & PONCELET P. (2010). Summarizing multidimensional data streams : A hierarchy-graph-
based approach. In Advances in Knowledge Discovery and Data Mining, p. 335–342. Springer.
RIZOIU M.-A., VELCIN J. & LALLICH S. (2014). How to use temporal-driven constrained clustering to detect typical
evolutions. International Journal on Artificial Intelligence Tools (IJAIT),23(4).
YANG J. & LESKOVEC J. (2011). Patterns of temporal variation in online media. In Proceedings of the fourth ACM
international conference on Web search and data mining, p. 177–186 : ACM.
1
/
2
100%