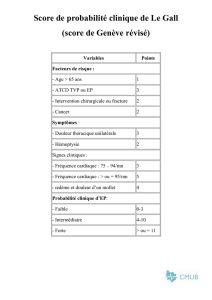
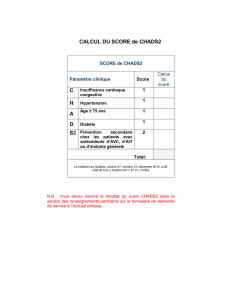
Résumé de ma thèse

« Assistance au praticien pour l’évaluation et la communication du
bénéfice/risque de différentes modifications comportementales ou thérapeutiques
dans un but de prévention de grandes pathologies »
Émilien Gauthier, Laurent Brisson, Stéphane Ragusa, Philippe Lenca
1 Explication du sujet de thèse
1.1 Motivations
La prévention personnalisée des grandes pathologies (principaux cancers, infarctus, déclin
cognitif) nécessite d’une part une évaluation individuelle des risques de l’individu et d’autre
part, la mise en œuvre de stratégies visant à diminuer ces risques : modification nutritionnelle
ou comportementales, traitement, dépistage renforcé, etc.
L’assistance au médecin (et au patient) peut bénéficier de l’apport d’outils informatiques
possédant d’une part une capacité de prédiction efficace des risques et d’autre part une capacité
à communiquer sur ces risques. Cette assistance doit permettre d’améliorer en conciliant d’une
part une prédiction efficace du risque individuel à partir de variables environnementales (nutri-
tion, tabac, etc.), biologiques (cholestérol, etc.) ou cliniques (densité osseuse, mammaire, etc.)
via des scores et, d’autre part, la communication entre patient et médecin en permettant une
visualisation simple et fiable des risques.
1.2 Contexte
Contexte scientifique
Parmi les nombreuses définitions de l’extraction de connaissance à partir des données (ECD)
trois d’entre elles illustrent bien les deux problèmes principaux qui sont abordés dans cette
thèse, à savoir celui de la qualité des modèles (les connaissances) produits et l’importance de
leur lisibilité dans une perspective d’aide à la décision :
– l’ECD est un processus d’aide à la décision où les utilisateurs cherchent des modèles
d’interprétation dans les données ;
– l’ECD est un processus complexe permettant l’identification, au sein des données, de mo-
tifs valides, nouveaux, potentiellement intéressants et les plus compréhensibles possible ;
– l’ECD est un processus interactif et itératif d’analyse d’un ensemble de données afin d’en
extraire des connaissances exploitables par l’utilisateur-analyste qui a un rôle central.
Les applications traditionnelles du data mining telles que la modélisation prédictive, la clas-
sification ou la recherche de cooccurrences ont prouvé leur utilité notamment dans le domaine
médical. Cependant, les algorithmes de fouille de données ont tendance à produire un volume
important de modèles dont l’intérêt est parfois discutable. Une étape de sélection et validation
des modèles est nécessaire et pourra se baser sur la connaissance du domaine.
Contexte industriel
Sous convention CIFRE, la thèse est réalisée en collaboration entre Télécom Bretagne au
Lab-STICC (LUSSI) et Statlife, une société qui développe des produits et services destinés à la
prévention des grandes pathologies. La thèse est effectuée en partenariat avec l’unité U1018/9
de l’INSERM en charge de l’étude E3N menée depuis 20 ans auprès de 100 000 femmes qui
répondent tous les 2 ans à des questionnaires portant d’une part sur leur mode de vie (alimen-
tation, traitements, tabac, etc.) et d’autre part sur l’évolution de leur état de santé.
1

2 Travaux réalisés
Pour affiner la stratégie de la thèse, un travail de bibliographie a été mené tant sur le versant
statistique et épidémiologique de la construction de scores dans le domaine médical, que sur
le versant apprentissage automatique et fouille de données du sujet. Ensuite, des mesures de
performance ont été réalisées, elles concernent les multiples configurations possibles de trois
algorithmes (considérés comme lisibles) du domaine de la fouille de données : algorithme des
plus proches voisins, Bayésien naïf et arbres de décisions.
2.1 Score construit sur des données américaines publiques
La première partie de thèse a été consacrée à l’étude de l’algorithme des proches voisins
(en raison de ses performances et de sa lisibilité) et à son utilisation au sein d’une approche
de fouille de données pour la création d’un score de risque du cancer du sein. Nos travaux ont
été appliqués sur une base de données américaine comportant 2,4 millions d’enregistrements.
Cette base étant librement accessible, nous avons pu confronter nos résultats à ceux obtenus
préalablement par Barlow et al.
Notre approche est un succès, car nous avons montré qu’il est possible de construire un
score de risque simple et lisible, grâce à un algorithme des kplus proches voisins (kppv), pour
la prévention primaire du cancer du sein. Notre modèle permet de prédire le risque de cancer du
sein avec autant de succès qu’un modèle logistique habituellement utilisé. Le nombre restreint
d’attributs utilisé en fait un score simple à utiliser. De plus, l’intervention de l’expert dans le
choix du modèle final, parmi les variations proposées, offre la possibilité de ne pas retenir le
modèle à la performance maximale, mais de faire un compromis avec les a priori des médecins
qui l’utiliseront.
Un article, reprenant et justifiant les différentes étapes du processus de la construction du
score de risque et les résultats obtenus, a été publié dans les actes de la conférence DMIN qui
s’est tenue à Las Vegas, États-Unis, du 18 au 21 juillet 2011.
2.2 Score pour les femmes françaises
La seconde partie de la thèse a été consacrée d’une part à l’amélioration de l’algorithme
de fouille des plus proches voisins en faisant varier la formule de la distance et la manière : de
recruter les voisins, de tester les performances des scores générés ou d’influencer l’algorithme
par des connaissances expertes. D’autre part, en parallèle, le processus de création de score de
risque a été appliqué aux données de la cohorte française E3N, un des objectifs de la thèse étant
d’aboutir à un score de risque utilisable sur la population française.
Le processus permet d’inclure les acteurs du domaine (épidémiologiste, donneur d’ordre
comme proxy pour les besoins utilisateur) d’une part dans l’étape de génération d’un jeu de
données compatible avec notre algorithme et les objectifs des futurs utilisateurs du score et
d’autre part, dans l’étape de sélection des scores générés avec l’algorithme.
Ces travaux ont fait l’objet d’un article publié dans les actes de la conférence RCIS qui s’est
tenue à Valence, Espagne, du 16 au 18 mai 2012.
De plus, avec l’aide d’étudiants de Télécom Bretagne, un prototype d’interface graphique,
permettant l’utilisation du score de risque sélectionné, a été mis au point. Après amélioration,
il sera testé à partir de janvier 2013 à l’Institut Gustave Roussy, premier centre de santé dédié
à l’oncologie en Europe, au cours de consultations de prévention du cancer du sein qui se dé-
rouleront dans le cadre d’une clinique du risque développée à l’échelle régionale.
2
1
/
2
100%