télécharger la page - Université Paris Descartes

Ordre des mots, Carline BERNARD, Judit GERVAIN (chez des enfants de 8 mois)
Les premiers pas vers l’acquisition de l’ordre des mots chez les nourrissons francophones de 8 mois
Carline Bernard & Judit Gervain
– Juillet 2011 –
INTRODUCTION
L’acquisition de l’ordre des mots chez le nourrisson est une question centrale en psychologie du développement. A ce
jour, deux théories s’opposent. La première, constructiviste, défend l’hypothèse lexicale selon laquelle l’ordre des mots
serait appris progressivement grâce à la fréquence des exemples rencontrés dans l’environnement verbal
(apprentissage statistique). La seconde, innéiste, défend l’hypothèse grammaticale selon laquelle l’acquisition de
l’ordre des mots nécessiterait au futur locuteur qu’est le bébé, de fixer les paramètres propres à sa langue maternelle,
en les repérant dans le flux de paroles qui l’entoure.
On distingue deux types de langues : les langues V(erbe)-O(bjet) comme le français, et les langues OV comme le
japonais. La distinction entre ces deux structures est basée sur trois éléments :
1) L’ordre relatif des constituants à l’intérieur les syntagmes grammaticaux (mot ou groupe de mots constituant une
unité dans la phrase) :
En français :
Les verbes précèdent leurs objets : manger une pomme
Les noms précèdent leurs compléments : les clefs de Pierre
On trouve des prépositions : de Paris
Alors qu’en japonais :

Les verbes suivent leurs objets : (« ringowo taberu »)une pomme manger
Les noms suivent leurs compléments : (« Pierreno kagi »)de Pierre les clefs
On trouve des post-positions : (« Tokyo kara »)Tokyo de
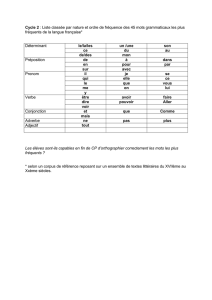
2) La position des mots les plus fréquents (appelés « mots de fonction » : articles, déterminants, pronoms) par rapport
aux mots les moins fréquents (appelés «mots de contenus»: noms, adjectifs, verbes, adverbes) :
En français :
Les mots les plus fréquents sont situés en de syntagme ;début
Alors qu’en japonais :
Les mots les plus fréquents sont situés en de syntagme.fin
3) La prosodie :
En français :
Les mots les plus saillants sont situés en fin de syntagme et sont marqués par une (lesdurée plus allongée
mots les plus étant les mots les plus ;fréquents courts)
Alors qu’en japonais :
Les mots les plus saillants sont situés en début de syntagme et sont marqués par une etintensité plus forte
une hauteur plus aiguë.
OBJECTIF & METHODE
Dans cette étude, nous nous sommes intéressés à l’acquisition de l’ordre des mots chez les nourrissons francophones
: quels sont les indices utilisés par les bébés francophones âgés de 8 mois pour apprendre l’ordre des mots de la
langue française ?
Nous pensons que les bébés seraient capables d’utiliser à la fois les indices fréquentiels (la fréquence des mots et leur
position dans la phrase) ainsi que les indices prosodiques (la durée des mots) pour structurer la parole.

Pour vérifier nos hypothèses, nous avons créé une grammaire artificielle comprenant des mots fréquents (ge, et desfi)
mots neuf fois moins fréquents (ru, Afin de masquer toutepe, du, ba, fo, de, pa, ra, to, mu, ri, ku, bo, bi, do, ka, na, ro).
information quant à la structure de ce discours artificiel, les quinze premières secondes ont été travaillées en fondue
d’amplitude croissante, et les quinze dernières secondes en fondue d’amplitude décroissante. Ainsi, la structure du
discours artificiel était ambiguë car aucun indice n’était donné quant à la fréquence des mots situés en début et en fin
de syntagmes.
Nous avons comparé deux groupes de bébés en leur présentant un discours artificiel présentant deux structures
différentes :
1) Pour le premier groupe de bébés, les deux types d’indices étaient cohérents : les mots les plus fréquents étaient
les mots les plus courts.
2) Pour le second groupe, nous avons créé un conflit entre les deux types d’indices : les mots les plus fréquents
étaient également les mots les plus longs (ne coïncidant pas avec la structure de la langue française).
Après une phase de familiarisation avec le discours artificiel, tous les bébés entendaient deux types d’items tests :
1) Quatre syntagmes structurés dans un ordre VO ;
2) Quatre syntagmes structurés dans un ordre OV.
Puis, par la méthode HPP (procédure de préférence par le regard), nous avons enregistré l’attention que les bébés
portaient sur chacun des syntagmes.

RESULTATS
Nous avons constaté que, dans le premier groupe, les bébés regardaient plus longtemps les items tests représentant
l’ordre reflétant la structure VO, que les items tests représentant l’ordre mot fréquent – mot non fréquent non fréquent
reflétant la structure OV. Ces résultats montrent que lorsqu’il y a une cohérence entre la durée des mots et– fréquent
leur fréquence, les bébés sont capables de déterminer l’ordre des mots dans la phrase, et montrent une préférence
pour l’un des deux types de stimuli.
Au contraire, dans le deuxième groupe, les bébés regardaient aussi longtemps les items tests représentant l’ordre mot
reflétant la structure VO, que les items tests représentant l’ordre fréquent – mot non fréquent non fréquent – fréquent
reflétant la structure OV. Ces résultats montrent que lorsqu’il y a un conflit entre la durée des mots et leur fréquence,
les bébés ne sont pas capables de déterminer l’ordre des mots dans la phrase, et ne montrent pas de préférence pour
l’un des deux types de stimuli.
CONCLUSION
Par cette étude, nous avons montré une tendance chez les bébés francophones de huit mois à préférer les syntagmes
ayant une structure VO, seulement s’ils avaient été familiarisés avec une grammaire artificielle ne présentant pas de
conflit entre la prosodie (la durée des mots) et la fréquence des mots. De ce fait, pour acquérir l’ordre des mots de leur
langue maternelle, les nourrissons se baseraient à la fois sur deux types d’indices: les indices fréquentiels et les
indices prosodiques. Il semblerait ainsi que les bébés francophones de huit mois aient déjà une représentation
abstraite pré-lexicale (avant la formation d’un lexique mental) de l’ordre des mots de la langue à laquelle ils sont
confrontés, conformément à l’hypothèse grammaticale, innéiste.
1
/
4
100%