ADD .L

TMS320C6711
Un DSP VLIW

Charles André - Université de Nice
2
Caractéristiques
• Processeur 32 bits
• Adresses: 32 bits (Byte-addressable)
• Unité de calcul flottante: 600 MFLOPS
• VelociTI architecture (VLIW modifiée):
parallélisme au niveau instruction.
• Comportement déterministe
• 2 multiplieurs, 6 ALUs
• Support matériel pour IEEE simple et
double précision.

Charles André - Université de Nice
3
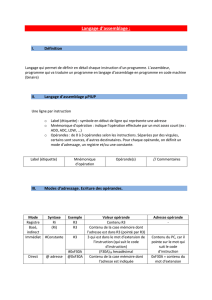
DSP core (TMS320C6711)

Charles André - Université de Nice
4
Unités fonctionnelles
•.Munité pour les multiplications
•.L unité pour les opérations logiques et
arithmétiques
•.S unité pour les opérations de
branchement, arithmétique et
opérations sur bits
•.D unité pour chargement/rangement et
arithmétique.

Charles André - Université de Nice
5
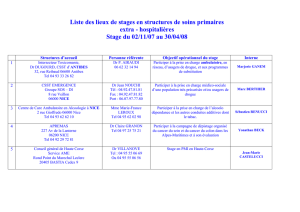
Produit scalaire
200
1
n
nn
n
Yax
=
=
=∑i
MPY .M a1,x1,prod
ADD .L Y,prod,Y
Attention:
src1, src2, dest
Nom de l’unité
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
1
/
38
100%