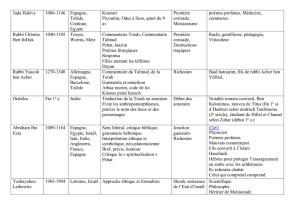
Historique des systèmes d`exploitation

Systèmes d’exploitation 1
Par : Ben Mahmoud & Shimi - 1 -
Guide du cours
Ce cours s'adresse aux étudiants de la 1ème année licence technologies de
l’informatique, tronc commun. Il sera enseigné en tant que élément constitutif de l’unité
d’enseignement fondamentale « Systèmes 2 ». Il sera assuré pendant 15 semaines à raison
d’une heure et demie de cours et travaux dirigés par semaine. Il comporte quatre leçons.
I. OBJECTIFS DU COURS
Se familiariser avec les concepts et les techniques fondamentales des systèmes
d'exploitation.
Expliquer et analyser le fonctionnement des différents modules du système
d'exploitation.
Utiliser et/ou adapter les techniques et les services du système d'exploitation
pour concevoir des codes plus fiables et plus performants.
II. PRE-REQUIS
ECUE : Systèmes logiques;
ECUE : Algorithmique & Structures de données 1 ;
ECUE : Atelier Systèmes 1
III. BIBLIOGRAPHIE CONSEILLEE
1. Andrew Tanenbaum, « Systèmes d’exploitation », Edition Pearson 3ème édition,
2008
2. Leila Baccouche, « Au Coeur des Systèmes d’Exploitation des Ordinateurs :
Concepts de base et Exercices Résolus », Centre de Publications universitaire
2003.
3. Mohamed Said Ouerghi, « Principes des Systèmes d’Exploitation », Centre de
Publications universitaire 2003.
4. Samia Bouzefrane, « Les systèmes d’exploitation, Unix, Linux et Windows XP
avec C et Java », Edition DUNOD, 2007
IV. SOMMAIRE DU COURS
Leçon 1 : Principes et histoire des systèmes d’exploitation

Systèmes d’exploitation 1
Par : Ben Mahmoud & Shimi - 2 -
I. Introduction
II. Rappels
III. Qu’est ce qu’un système d’exploitation ?
IV. Historique des systèmes d’exploitation
V. Structuration d’un système d’exploitation
VI. Fonctionnalités d’un système d’exploitation
VII. Conclusion
Leçon 2 : Gestion des processus
I. Introduction
II. Généralités sur les processus
III. Activités des processus
IV. Stratégie d’ordonnancement
V. Les processus sous unix
VI. Conclusion
Leçon 3 : Gestion de la mémoire centrale
I. Introduction
II. Généralités sur la mémoire centrale
III. Méthodes de partitionnement
IV. Les stratégies d’allocation
V. Conclusion
Leçon 4 : Systèmes de gestion des fichiers
I. Introduction
II. Fichiers et répertoires
III. Gestion des disques
IV. Organisation logique des fichiers
V. Organisation physique des fichiers
VI. Conclusion

Systèmes d’exploitation 1
Par : Ben Mahmoud & Shimi - 3 -
Leçon 1 : Principes et histoire des systèmes
d’exploitation
Objectif général
Connaître l’histoire et les principes de base des systèmes
d’exploitation.
Objectifs
spécifiques
Parcourir l’histoire des ordinateurs.
Parcourir l’histoire des systèmes d’exploitation.
Savoir définir un système d’exploitation par ses différents
rôles.
S’initier aux principes de base d’un système d’exploitation.
Volume horaire
Cours : 3h
Mots clés
Système, services, processus, mémoire, fichiers, matériels,
programmes,…

Systèmes d’exploitation 1
Par : Ben Mahmoud & Shimi - 4 -
I. Introduction
Dès l’apparition des systèmes d’exploitation, aux années 60, le monde
informatique a connu un large changement dans les méthodes d’utilisation et de
développement des ordinateurs.
Ce premier chapitre introductif mettra l’accent sur l’histoire des systèmes
d’exploitation tout rappelant certaines notions. Ensuite, les principes de base des
systèmes d’exploitation seront décrits afin de mieux comprendre l’utilité des
systèmes.
II. Rappels
1. Définitions
Un ordinateur est une machine de traitement de l’information. Il est capable
d’acquérir de l’information, de la stocker, de la transformer en effectuant des
traitements quelconques, puis de la restituer sous une autre forme. Le mot
informatique vient de la contraction des mots information et automatique.
On appelle information tout ensemble de données. On distingue
généralement différents types d’informations : textes, nombres, sons, images, etc...
Toute information est manipulée sous forme binaire (ou numérique) par l’ordinateur.
Un programme est une suite d’instructions élémentaires, qui vont être
exécutées dans l’ordre par le processeur. Ces instructions correspondent à des
actions très simples, comme additionner deux nombres, lire ou écrire une case
mémoire, etc...
2. Architecture de base d’un ordinateur

Systèmes d’exploitation 1
Par : Ben Mahmoud & Shimi - 5 -
Un ordinateur est constitué principalement de 2 éléments essentiels : la
mémoire centrale et le processeur. La mémoire centrale (MC en abrégé) permet de
stocker de l’information (programmes et données), tandis que le processeur exécute
pas à pas les instructions composant les programmes.
2.1. Le processeur
Le processeur est un circuit électronique complexe qui exécute chaque
instruction très rapidement. Toute l’activité de l’ordinateur est cadencée par une
horloge unique, de façon à ce que tous les circuits électroniques travaillent
ensembles. La fréquence de cette horloge s’exprime en MHz (millions de battements
par seconde). Par exemple, un ordinateur “PC Pentium 133” possède un processeur
de type Pentium et une horloge à 133 MHz.
Le processeur est capable d’exécuter des programmes en langage machine,
c’est à dire composés d’instructions très élémentaires suivant un codage précis.
Chaque type de processeur est capable d’exécuter un certain ensemble
d’instructions.
2.2. La mémoire centrale (MC)
La mémoire centrale est divisée en cases de taille fixe (par exemple 8 bits)
utilisées pour stocker instructions et données d’un programme. En principe, la taille
d’une case mémoire pourrait être quelconque ; en fait, la plupart des ordinateurs en
service aujourd’hui utilisent des emplacements mémoire d’un octet (byte en anglais,
soit 8 bits, unité pratique pour coder un caractère par exemple).
III. Qu’est ce qu’un système d’exploitation ?
Selon plusieurs auteurs, un système d’exploitation (SE en abrégé) est défini
comme étant un ensemble de programmes ayant pour tâche de faire fonctionner un
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
1
/
48
100%