1 - GEPV

Passé, présent et avenir (?)
Une brève histoire des
marqueurs moléculaires
utilisés en génétique des
populations
Jean-François Arnaud
UMR CNRS 8198
Laboratoire de Génétique et Évolution des Populations Végétales
Bât. SN2, Université de Lille 1, 59655 Villeneuve d’Ascq cedex

L’histoire de l’écologie moléculaire
vue par John C. Avise (2006)
Dans les années 60:
Quelques biologistes moléculaires de laboratoire et quelques
naturalistes de terrain se courtisent. Leur progéniture montre
une belle vigueur hybride: les populations naturelles sont
pleines de diversité !
Dans les années 70:
Ce nouveau-né chimérique se développe, avec parfois une belle
dose de naïveté: des conclusions issues d’une poignée de
marqueurs allozymiques peuvent-elles se généraliser à
l’ensemble du génome ?
Les années 80
Cet adolescent turbulent vit des idylles avec des partenaires
différents: RFLP, fingerprinting, RAPD, PCR, séquence
mitochondriales puis nucléaires, microsatellites, SNP,
expression de gènes…: chaque développement technique est
l’occasion d’un flirt parfois durable. Les méthodes d’analyse se
raffinent.

L’histoire de l’écologie moléculaire
vue par John C. Avise (2006)
Sortie de l’adolescence:
1992: naisance du journal Molecular Ecology, et
publication de plusieurs ouvrages dédiés à la discipline.
Le 21ème siècle:
La pleine maturité ? Ere génomique
•Génétique de la
conservation
•Ecologie microbienne
•Suivi des OGM
•Bases écologiques des
modulations de l’expression
•Le code-barre du vivant
•Bases génétiques de
l’adaptation
•Investigation judiciaire
•Analyse de parenté
•Ecologie
comportementale
•Structure génétique des
populations
•Phylogéographie
•Spéciation-hybridation

1992 2001
+ quelques ouvrages de références

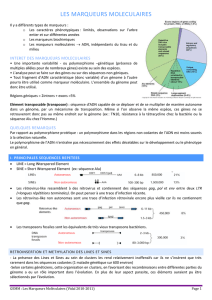
Les marqueurs moléculaires utilisés en Génétique
des Populations : définition et quelques exemples
Définition :
Marqueur moléculaire = fragment d'ADN (information génétique)
ou sa représentation moléculaire (ARN, protéines)
Définition extrêmement large qui retient l'ensemble
de l'information génétique
Exclusion de l'ensemble des marqueurs phénotypiques
(couleur de la coquille chez les escargots, marqueurs
pigmentaires comme l'albinisme)
Universalité des marqueurs moléculaires : le marqueur est partagé
par tous les individus d'une même espèce, ou par toutes les espèces
Transmissibilité : les marqueurs moléculaires sont transmis de génération
en génération, il est préférable que cette transmission des allèles soit
mendélienne (transmission des allèles en proportion équiprobable)
= avantage sur marqueurs phénotypiques
L'échantillon dans lequel on peut choisir des marqueurs est de taille
considérable : ex. le génome humain = 3 milliards de paires de base, si
1000 sites informatifs présentant chacun 2 allèles on a 31000 génotypes
possibles… Contraste avec le nombre généralement faible de traits
phénotypiques utilisables en temps que marqueurs (en particulier chez
des espèces que l'on ne peut manipuler en laboratoire)
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
1
/
69
100%