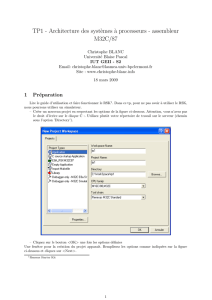
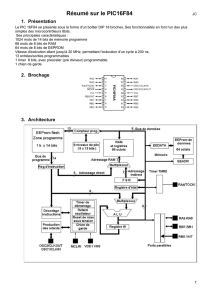
Architecture des Systèmes Embarqués




Domaines d’application
IApplications:
IGrand public:
Ilecteurs MP3, PDA, t´el´ephones portables, cartes `a puce,
consoles de jeu
IAvionique / Automobile / Ferroviaire :
IContrˆole de vitesse, Pilote automatique, Tableau de bord
IT´el´ecommunications
IModems, routeurs, satellites
IM´edical
IPacemaker, imagerie, robots
IMilitaire
IT´el´eguidage, radar, drones

Sp´ecificit´es des syst`emes embarqu´es
IRessources contraintes: ´energie, m´emoire, capacit´es calcul
(eg. pas de FPU)
ISyst`emes critiques: garanties de sˆuret´e, d´eterminisme et
tol´erance aux fautes
ISyst`emes temps r´eel: eg. contrˆole de vitesse d’un train
IInterfa¸cage avec des p´eriph´eriques externes: capteurs de
temp´erature, de vitesse, communications
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
1
/
55
100%