Télécharger l`article en PDF

© Alcyonix SQLI Group, 2014
1
LE NOSQL EST-IL L’AVENIR DES BASES DE DONNEES ?
Par Pirmin Lemberger
BASES RELATIONNELLES, LES RAISONS D’UNE DOMINATION
Voici bientôt un demi-siècle que les bases de données relationnelles règnent sans partage sur
l’informatique de gestion, en contraste flagrant avec l’instabilité technologique qui caractérise en général
ce secteur. Paraphrasant L. Kronecker, un mathématicien du 19ème siècle qui forgea l’aphorisme célèbre
« God made the integers, all else is the work of man », R. Ramakrishnan, l’auteur d’un manuel sur la base
de données relationnelles, proposa le jeu de mot (intraduisible) « Codd made relations, all else is the work
of man ». Par cette pirouette, l’auteur entend attirer l’attention sur ce qui fait la spécificité du modèle
relationnel inventé en 1970 par E.F.Codd. Celui-ci se base en effet sur une structure mathématique intemporelle (l’algèbre
relationnelle) à l’abri des modes éphémères. Des données structurées en tables, des enregistrements reliés implicitement par
des clés étrangères et des schémas de données stricts, voilà en gros pour le modèle. Le langage SQL, un quasi-standard de
fait, permet alors de formuler des requêtes en spécifiant ce que l’on cherche, on parle à ce titre de langage déclaratif, et non pas
comment on va le chercher : « Trouves tous les clients qui se nomment Dupond, qui habitent Paris et qui ont déjà passé une
commande de plus de 100€ ! ». La base de données relationnelles (SGBDR) se charge de masquer toute la complexité
inhérente à l’algorithme de recherche en convertissant une requête SQL en une séquence d’opérations élémentaires sur les
tables (sélection, jointure, projection etc…). L’existence d’une algèbre est ici déterminante car c’est elle qui permet au SGBDR
de convertir cette séquence d’opérations en une autre, équivalente, dont on cherche à optimiser le temps d’exécution, un peu de
la même manière que les règles de l’algèbre usuelle permettent de simplifier une expression arithmétique avant d’entreprendre
son calcul. Ces travaux de pionniers et ceux qui ont suivi ont permis aux SGBDR de résoudre simultanément plusieurs
problèmes fondamentaux de l’informatique de gestion. Rappelons brièvement ici ces atouts :
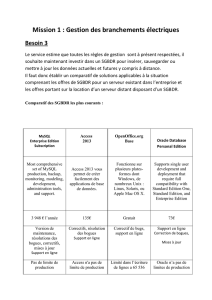
Un SGBDR prend entièrement en charge l’élaboration d’un plan de recherche des données, le code d’une application
cliente est donc allégé de cette tâche.
Un SGBDR isole les applications clientes de la structure physique des données sur le disque. Un changement de cette
structure n’aura aucun impact sur le code applicatif. C’est le découplage physique.
Un SGBDR permet d’utiliser les données de manière non-anticipée en ce sens que les requêtes peuvent être modifiées, là
encore, sans avoir à modifier le code applicatif. C’est le découplage logique incarné p.ex. par la notion de vue SQL.
Un SGBDR peut garantir la cohérence des données en appliquant des contraintes d’intégrité correspondant à un schéma
de données prédéfini par l’utilisateur.
Enfin, et c’est là le plus important, un SGBDR gère les accès concurrents aux données au moyen de transactions.
Pendant leur mise à jour par un processus, les enregistrements sont isolés1 (à des degrés divers) pour les protéger de
modifications intempestives par d’autres processus qui les laisseraient alors dans un état incohérent et imprévisible.
Les zones d’ombres cependant ne manquent pas et viennent nuancer quelque peu le tableau précédent. La première est liée à
la difficulté de répartir les traitements d’un SGBDR sur un grand nombre de nœuds serveurs, le nombre d’échanges entre eux
pour assurer l’intégrité des données devenant rapidement prohibitif en termes de performance et de prix des licences !
Un autre inconvénient notoire des SGBDR est leur inadéquation avec la programmation orientée objet qui manipule, elle, de
petits agrégats de données en mémoire organisés en grappes et en hiérarchies. Construire ces grappes ou les sauvegarder
dans un ensemble de tables s’est avéré être une opération particulièrement délicate. Ainsi a-t-on vu la naissance des framework
de « mapping objet-relationnel » chargés d’établir un pont entre les deux mondes, sources de complexité non-négligeable des
architectures logicielles. Bien que des solutions techniques soient apparues dès les années 1990 pour palier ces inconvénients,
nous pensons ici aux bases de données objets, l’hégémonie des SGBDR, promues dans l’intervalle au rang d’outil d’intégration
favori des DSI, qui a rendu extrêmement problématique la migration vers un nouveau modèle. Dans une certaine mesure,
l’hégémonie de modèle relationnel a donc inhibé l’innovation technologique.
Puis vint le séisme du web suivi de ses répliques : le e-commerce, les réseaux sociaux et depuis peu le big data…
1 L’isolation est l’une des quatre conditions que doit vérifier une transaction pour lesquelles l’acronyme ACID constitue un mnémonique utile.

© Alcyonix SQLI Group, 2014
2
LE DOGME REMIS EN QUESTION
… et avec eux de nouveaux besoins et des priorités chamboulées qui ont résolument changé la donne. Pour un site d’e-
commerce ou pour un réseau social par exemple, les exigences de disponibilité et de capacité à monter en charge ont
désormais largement supplanté les exigences d’intégrité des données ou d’isolation des transactions. Pour une entreprise
comme Amazon, une plateforme indisponible, ne serait-ce que quelques minutes, signifie une perte de dizaines de milliers de
commandes. Dans ces conditions, une adhérence stricte à l’isolation des transactions qui risquerait de pénaliser les
performances est inenvisageable. La solution est humaine et pragmatique : dans les très rares situations où un client se trouvera
lésé, suite à une collision entre deux transactions par exemple, le service client lui transmettra un mot d’excuse assorti d’un bon
d’achat proportionné au préjudice subi.
Par ailleurs, une grande partie des données que l’on cherche aujourd’hui à valoriser dans un SI n’est pas disponible sous forme
de tables structurées. Il s’agit plutôt de données non-structurées éparpillées dans un fatras de fichiers Excel, de logs ou même
de fichiers audio pour lesquels un SGBDR n’est d’aucun secours.
La possibilité de distribuer le stockage et les traitements, au besoin sur des milliers de machines, est désormais cruciale pour
assurer la disponibilité des systèmes e-commerce. Pour cela, il existe un éventail de solutions que l’on désigne couramment par
le terme NoSQL. Impossible d’en donner une définition fonctionnelle précise, tout au plus peut-on énumérer quelques
caractéristiques communes à ces systèmes : ils sont le plus souvent (1) clusterisables, (2) dépourvus de schémas, (3)
dépourvus de transactions, (4) non-relationnels et (5) proposés en open-source. On peut les répartir en 4 catégories :
1. Les entrepôts clé-valeur : c’est la base NoSQL la plus simple qui soit, elle se réduit à une simple table de hachage
persistance au moyen de laquelle on pourra enregistrer ou récupérer… n’importe quoi (la valeur) au moyen d’une clé ! Le
« n’importe quoi » (=blob) n’a aucune structure a priori. C’est à l’application cliente de comprendre la structure de ce blob.
Les caddies des clients d’un site e-commerce peuvent être implémentés de cette manière.
2. Les bases orientées documents : similaires au cas précédent, elles présupposent néanmoins que les valeurs stockées
sont des documents structurés et auto-descriptifs, de type XML, JSON ou autre, que l’on peut examiner. Un site d’e-
commerce qui doit disposer d’un schéma flexible pour entreposer la description de ses produits pourrait utiliser ce type de
solution.
3. Les bases de données orientées colonnes : structurées en lignes et en colonnes comme dans les SGBDR, les
enregistrements sont toutefois rassemblés en groupes de colonnes et les opérations d’agrégation y sont très performantes.
Pour l’enregistrement d’un client p.ex. un premier groupe contiendrait les commandes et un second le profil utilisateur. Les
CMS ou les plateformes de blogs qui hébergent des articles avec leurs commentaires, leurs liens, les rétro-liens et des tags
pourraient en faire bon usage. Les redondances et la dé-normalisation des données sont ici monnaie courante.
4. Les bases de données orientées graphe : elles autorisent le stockage d’entités connectées par des associations
directionnelles dotées de propriétés. Dans toutes les situations où des entités appartiennent simultanément à plusieurs
domaines (sociaux, professionnels, géographiques), comme les réseaux sociaux p.ex., ce type de solution permettra la
navigation d’une entité à l’autre, beaucoup plus efficacement que ne sauraient le faire les SGBDR (forts mal nommés).
POURQUOI ET QUAND CHOISIR UNE SOLUTION NOSQL ?
Pas de concepts profonds, ni d’algèbres mystérieuses donc pour le NoSQL, mais un retour à une forme de rusticité
technologique. Faire très efficacement juste ce qu’il faut, telle pourrait être en l’occurrence la devise. La complexité n’a
évidemment pas disparue comme par enchantement, mais elle a migré. Plutôt que d’être encapsulée dans une solution à
vocation universelle, comme un SGBDR, la complexité bascule désormais dans le code applicatif chargé d’assurer un minimum
de cohérence des données, on peut accepter par exemple dans certaines situations des incohérences temporaires (eventual
consistency). Une certaine rigidité du modèle de données fera aussi partie du prix à payer. Pour le coup, la complexité sera
entièrement dédiée à résoudre un certain type de problème de performance. En ce sens elle sera optimale.
Ne nous leurrons pas, les solutions NoSQL ont pour l’instant le charme propre aux terres inexplorées. Accroître la productivité
des programmeurs grâce à la simplicité de ces nouvelles plateformes et augmenter drastiquement les performances seront les
principales motivations d’un tel choix. Les projets pour lesquels la réduction du time to market est déterminante et ceux pour
lesquels un avantage compétitif justifie une prise de risque technologique pourront utiliser avec profit ces nouvelles solutions.
Les SGBDR ne sont pas morts pour autant, ils coexisteront pour longtemps, dans le cadre de ce que Martin Fowler nomme fort
poétiquement la persistance polyglotte, avec ces solutions non orthodoxes.
Mais, insistons encore une fois là-dessus, le recours à l’option NoSQL se fera avant tout sur la base d’un examen lucide et
chiffré des compromis acceptables entre consistance des données et disponibilité des systèmes. Il s’agit donc au moins autant
d’un choix commercial que d’un choix technologique.

© Alcyonix SQLI Group, 2014
3
PS : Merci, une fois encore, à Manuel Alves pour sa relecture sans concession et pour m’avoir fait bénéficier de son inégalable
exigence de cohérence logique.
1
/
3
100%