INTRODUCTION - Luca Scuderi

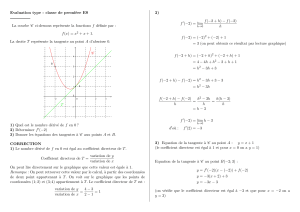
1
Chapitre 3 : Mesures de dispersion et de forme,
observations atypiques et extrêmes,
corrélation, concentration
Autres caractéristiques d’une distribution de
fréquences
données brutes
ordonner (données rangées)
condenser (données condensées)
ventiler (données groupées en classes)
Mesures de la tendance centrale (mode, moyenne,
médiane) : insuffisant.
Calculer la dispersion
en absolu : l’étendue
autour de la tendance centrale :
- La variance
- L’écart-type (autour de la moyenne)
- L’écart semi-interquartiles (autour de la médiane)

2
dispersion « faible » dispersion « forte »
•• ••• ••• •••• • • ••••
Données brutes
Polygone
des fréquences
x
x
x
x
(Ouellet p.56)
Étendue
1. Données rangées :
1
xxN
(population)
1
xxn
(échantillon).
2. Données condensées :
1
xxk
.
3. Données groupées en classes :
0
bbk
.
Le champ des données est l’intervalle dans lequel elles
tombent. L’étendue est la longueur de ce champ.

3
Valeur absolue et distance
Soit x un nombre réel. On définit la valeur absolue de x
comme
2
xx
0 si
0 si
xx
xx
x
.
Distance entre deux nombres réels x et y :
),(d yxyx
Positive : d(x,y) ≥ 0
Symétrique :
),,(d ),(d xyyx
car
),(d)( ),(d yxyxyxxyxy

4
Variance
Pas interprétable en soi. Calcul transitoire pour
l’écart-type, qui est sa racine carrée.
Formule varie légèrement entre population
(somme des carrés des écarts divisée par N)
et échantillon (division par n-1).
Cette différence, mineure, est justifiée pour des
raisons théoriques.
Variance de la population :
1. Données rangées
N
x
N
iXi
X
1
2
2)(
.
moyenne des carrés des distances
Formule difficile à lire sous cette forme.
En fait résultat d’un calcul simple sur un tableau.
i
x
Xi
x
2
)( Xi
x
1
x
X
x
1
2
1)( X
x
2
x
X
x
2
2
2)( X
x
N
x
XN
x
2
)( XN
x
Total
X
N
0
2
X
N

5
2. Données condensées
k
iXii
k
iXii
Xxf
N
xn
1
2
1
2
2)(
)(
.
k est le nombre de modalités distinctes
Même formule que pour les données rangées, mais
uniquement à partir des modalités distinctes.
Les multiplicités (ni) de ces modalités doivent donc
apparaître.
3. Données groupées en classes
k
iXii
k
iXii
Xmf
N
mn
1
2
1
2
2)(
)(
k est le nombre de classes.
Comme si on donnait la valeur mi aux modalités
tombant dans la i° classe.
Comme dans le cas des données condensées
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
1
/
64
100%