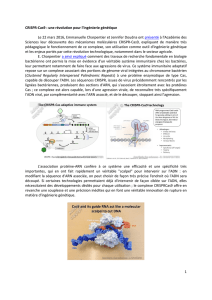
Génomique structurale - Cours-univ

Génomique structurale
I) Analyse du génome humain
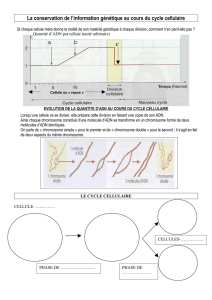
Le caryotype permet de tirer certaines informations, mais il existe une grande différence
d’échelle entre un microscope et les outils de séquençage (1000 bases =1kb est une taille très
petite par rapport à l’ensemble du génome humain). Les outils sont donc compliqués car la
taille est très petite à ce niveau.
1) Microscopie : le caryotype
Il faut observer les cellules en métaphase, et pour ce faire on se sert de poisons comme la
colchicine. Celle-ci détruit les microtubules et empêche donc le passage en anaphase, les
chromosomes ne peuvent pas être tirés vers les pôles.
Il faut ensuite lyser les cellules sans utiliser de technique abîmant le matériel génétique
comme la sonication (trop violente) ou des détergents (provoquent des dégâts). On se sert par
exemple d’un choc hypotonique.
Enfin on peut déposer des colorants (ex : bleu de Giemsa pour observer les bandes G) et étaler
sur une lamelle pour observer le caryotype. Une retouche informatique (photoshop) permet
enfin d’obtenir les caryotypes classiques.
Chaque bande ainsi obtenue est numérotée, la notation est la suivante (figure 1):
Numéro de chromosome + bras (p = petit, q = grand)
+ Numéro de bande (dans le sens centromère télomère)
Exemple : 11p13 (13eme bande en partant du centromère sur le petit bras du chromosome 13)
Le centromère est l’endroit où le chromosome est attaché dans le phénomène de division
cellulaire.
Il existe des informations remarquables concernant l’ADN :
Il n’y a que 1000 à 2000 gènes dans le génome ce qui a surpris les généticiens, ce nombre
étant extrêmement faible par rapport à la complexité d’un organisme.
De plus dans un chromosome il y a deux fois plus de protéines que d’ADN.
Figure 4 :
On voit les bandes claires ( R ) pauvres en GC et riches en AT et les bandes sombres (G)
riches en GC.
Les boucles « loops » sont les régions plus fortement transcrites.
Les régions associées à la matrice (MARs), riches en AT (bandes R), sont moins compactes
sur le chromosome.
Figure 2 :
La densité de la chromatine n’est pas homogène. Les régions riches en AT sont sous forme
d’hétérochromatine (dense aux électrons et donc sombre) souvent située en bordure, près de la
membrane interne. L’euchromatine moins dense aux électrons représente les régions riches en
GC, ce qui les rend plus accessibles surtout pour les protéines (facteurs de transcription…) et
pour la sortie des ARN.

D’après de récentes publications, l’euchromatine est très organisée. Si on marque avec une
sonde une certaine région, celle-ci occupera toujours la même position relative dans le noyau
de génération en génération.
Figure 3 : les niveaux de compaction
2) Analyses moléculaires
a) étalement sur gel
Si on étale l’ADN sur gel d’agarose dans le cadre de l’apoptose, on obtient :
Certaines protéines se fixent sur l’ADN et empêchent ainsi la coupure à cet endroit, entre les
nucléosomes.
b) Le télomère
Le télomère est l’extrémité d’un chromosome. Du point de vue de la réplication, les
séquences télomériques sont des séquences très spéciales. A l’extrémité de l’ADN, l’amorce
ARN servant à la duplication ne peut pas être remplacée par de l’ADN (il faut toujours une
amorce ARN avant de répliquer). Ceci entraîne un raccourcissement de l’ADN.
Figure 5a
Les cellules sont donc vouées à disparaître, en mourant une fois que l’érosion est assez
importante. C’est une sorte d’horloge moléculaire qui compte les divisions cellulaires (10-15
divisions par cellule en moyenne).
L’intérêt évolutif est d’empêcher l’accumulation d’erreurs (pouvant entraîner des cancers…).
De plus les espèces ne sont pas faites pour vivre longtemps, le renouvellement des individus
permettant une meilleure sélection.
Certains types cellulaires ont une solution à ce problème, permettant le renouvellement des
cellules (ex : cellules germinales). C’est une enzyme, la télomérase, qui allonge les télomères.
Figure 5b : la séquence télomérique est une séquence répétée (ex : GGGTTA)
La télomérase a un cofacteur qui est une molécule d’ARN à séquence complémentaire à
l’extrémité 3’. Elle laisse une partie libre qui dépasse côté 5’ (donc du côté 3’ de l’ADN). La

télomérase a une activité Reverse Transcriptase (RT) et va allonger l’ADN en se servant de
l’ARN qui dépasse comme matrice. Une fois l’ADN ainsi allongé, une amorce vient se fixer à
la place de la télomérase et réplique la partie manquante.
Cette télomérase est souvent présente dans les cellules cancéreuses.
Rem : il existe une compétition entre activité exonucléase coupant l’extrémité et télomérase.
Les bactéries ont un ADN circulaire, et n’ont donc pas ce type de problèmes.
E. coli a un génome de 4,63Mbases. Mais il n’y a que 4403 gènes !
Chez l’homme, le chromosome est 50 fois plus grand et on n’a que 10 à 15 gènes par
0,75Mbases. Les introns sont généralement plus grands que les exons, les zones non codantes
(régions intergéniques) sont plus grandes et nombreuses. Il y en a peu chez les bactéries.
II) Le séquençage
1) Introduction
Figure 6 : La génétique moléculaire moderne commence dans les années 60
L’électrophorèse capillaire s’effectue dans des minces couches de verre et permet d’utiliser
des nano échantillons, très peu de quantités pour des microanalyses.
La PCR est une réplication d’ADN in vitro, la dénaturation de l’ADN se fait par la chaleur.
Les premières PCR se faisaient avec des bains maries et des ajouts de polymérases à chaque
tour (la protéine se dénaturait avec la chaleur).
Les séquenceurs sont des systèmes utilisant des électrophorèses capillaires, et permettent de
séquencer 0,3Mbases par jour par machine.
Il y a eu 3 grandes phases avec des logiques différentes :
Phase 1 : de la fonction à la protéine, de la protéine à l’ADN.
Phase 2 : du clone à la protéine, séquence, expression, fonctionnement
Phase 3 : cartographie, séquençage et annotation, systématique des génomes : de la banque de
données à la biologie.
Il faut donc maîtriser tous ces outils.
Figure 9 : 2 stratégies d’acquisition des séquences
En 2006, on a donc séquencé 305 génomes, 760 séquençages de procaryotes et 531
d’eucaryotes étant encore en cours.
La technique shotgun consiste à insérer des fragments d’ADN dans un plasmide dont on
connaît la séquence, et sur lequel on choisit les amorces pour l’amplifier.
Une fois tous les fragments séquencés, un ordinateur va faire des calculs pour savoir quel
fragment est associé à quel autre…
Les séquences répétées posent un problème, l’ordinateur a du mal à rabouter. Il faut recouper
avec la cartographie pour ne pas se tromper.
Les grandes retombées des projets de séquençage sont :
- technologies (séquenceurs automatiques, procédures automatisées pour préparation des
ADNs)
- informatique : programmes d’analyse du génome, serveurs
- fondamentales (connaissances et comparaison de génomes, phylogénie)
- médicales et médico-légales : maladies génétiques, identification de criminels,
pharmacogénomique, clusters d’allèles de susceptibilité…

Comparaison de taille de quelques génomes :
Levure = 6200 gènes, drosophile = 13000 gènes, C. elegans : 18000 gènes, arabidopsis :
26000 gènes, homme : 31000 gènes.
2) Séquences d’ADN : comment les faire et comment les caractériser ?
- Extraire l’ADN et retirer les protéines… il en faut une certaine quantité purifiée et isolée
- l’amplifier par PCR ou clonage
- digérer l’ADN génomique
- liguer les fragments dans les vecteurs
- introduire le vecteur dans l’hôte
Le clonage nécessite un couple vecteur – hôte. Il est utilisé si on ne connaît pas la séquence.
Le vecteur doit avoir origine de réplication, sire de clonage… La descendance à partir de
l’organisme recombinant est clônale : il n’y a qu’un vecteur par hôte.
Cloner un gène, c’est disposer sa séquence isolée dans un système vecteur – hôte qui permette
son expansion clonale : on obtient des banques qui peuvent être génomiques ou d’ADNc
(uniquement codant, en utilisant la reverse transcriptase et des ARNs au lieu de l’ADN
génomique).
La taille des fragments ne doit pas être trop petite (il faut couvrir tout le génome) ni trop
grande (risque d’erreurs). Si on obtient assez de recombinants on peut couvrir tout le génome,
mais il peut arriver qu’il en manque.
Les fragments chevauchants sont plus faciles à analyser (plusieurs fragments de tailles variées
mais qui se chevauchent, qui contiennent des bouts de séquence identique) : il y a un certain
taux de redondance et la perte d’un clone peut être compensée.
Figure 10 : notion de quantité de recombinants qu’il faut avoir : entre 105 et 106…
A mille colonies par boîte, il faudrait donc entre 100 et mille boîtes.
Si on recherche une séquence correspondant à une certaine protéine, on peut se servir d’un
ARN, faire une transcription reverse (RT) et se servir du produit comme sonde : on fait des
répliques des boîtes sur membrane de nitrocellulose et on observe où la sonde s’hybride.
Mais une banque contient également les régions non codantes !
Pour retrouver les séquences codantes si on a une séquence génétique, on a différents indices
qui ne sont pas toujours très faciles à étudier :
- dans une séquence totalement aléatoire, il y a une chance sur 64 de tomber sur un codon
stop, ce qui est plus rare dans une séquence codante (mais dans les introns il peut y en
avoir…).
- des analyses statistiques ont montré qu’en fin d’exon il y a une forte probabilité de séquence
GGT et au départ de l’exon suivant une séquence CAG.
- début de transcription sur un ATG, avec une probabilité plus forte d’avoir : CACC ATG G
- promoteurs : TATA box…
Ceci n’est cependant pas suffisant pour déterminer avec certitude la présence d’une région
codante. Il faut déjà beaucoup de manips et d’analyses informatiques pour arriver à ce
résultat…

3) banques d’ADNc
Les banques d’ADNc sont plus utiles dans ce contexte, il s’agit de banques obtenues
directement à partir de reverse transcriptions de tous les ARNm.
Les ADNc sont les ADNs obtenus après RT d’ARN.
Un ARN a une coiffe en 5’, une partie non codante UTR, une partie codante, une queue poly
A. L’ATG ne se trouve pas directement à l’extrémité 5’, il y a d’abord une région 5’ UTR.
Les régions non traduites peuvent être très longues (plusieurs centaines de bases) et
permettent de protéger l’ARN qui est très sensible. Elles jouent aussi un rôle dans la
régulation de la traduction. La forme des boucles que forme cette région en 5’ permet la
reconnaissance de la grosse sous-unité ribosomique
Il faut extraire l’ARNm, or les ARNt sont plus nombreux, et les ARNr sont encore plus
nombreux. On les purifie par chromatographie en utilisant des billes sur lesquelles sont
greffés des séquences oligo dT permettant de fixer le polyA des ARNm.
Le sel favorise les liaisons hydrogène (enlève l’eau qui fait compétition à ces liaisons) et on le
retire donc tout en chauffant doucement pour décrocher les ARNm des billes.
Figure 11 :
L’ARNm est rétro transcrit par la Reverse Transcriptase, on se sert d’une amorce polyT. Mais
on ne dispose pas d’amorce pour transcrire dans l’autre sens : on fait agir la RNase H qui va
couper l’ARN, permettant d’obtenir ainsi une amorce côté 5’ à l’origine d’un ADN double
brin. Il faut une ligase pour lier les bouts d’ADN obtenus
Le rendement de ces étapes est très variable, une RT parcourt en moyenne de 0,5 à 1 kb, la
quantité des ARN totalement rétro transcrits est donc assez faible. Les extrémités 5’ sont
souvent perdues.
Il faut ensuite cloner cet ADNc, par exemple dans un vecteur bactériophage.
Le bactériophage lysogène est intéressant : si on l’ouvre au milieu du gène permettant la
lysogénie, on aura un phage purement lytique si de l’ADN est inséré, et un phage lysogène
dans le cas contraire.
Le phage vit très longtemps, et permet donc une conservation à long terme.
L’avantage de L’ADNc est qu’on obtient la séquence codante, dont on peut directement lire la
séquence en acides aminés et la comparer à des bases de données de familles protéiques. La
petite taille des fragments donne une facilité de manipulation, et on peut aussi tester
l’expression (transitoire ou stable).
L’expression nécessite un promoteur, et peut être faite chez un procaryote présentant
l’avantage de se reproduire rapidement mais dont les protéines ne sont pas modifiées après
traduction comme chez les eucaryotes et ne sont donc pas toujours fonctionnelles.
Chez les eucaryotes, le promoteur est reconnu par les ARN polymérases et on aura expression
de la protéine à coup sûr.
Les plasmides, non répliqués, vont être dilués au fur et à mesure des divisions, c’est
l’expression transitoire. Une expression stable est possible par insertion dans l’ADN
génomique, ce qui est un phénomène assez aléatoire.
Une fois que l’on a obtenu une boîte avec différents clones d’ADNc, il va falloir retrouver
celui qui nous intéresse. Si on connaît la séquence, il suffit de se servir d’une sonde. Dans le
 6
7
8
9
10
11
12
13
6
7
8
9
10
11
12
13
1
/
13
100%