Cours de structure des Ordinateurs
De nos jours l'informatique est devenue une compétition commerciale et
technologique dans laquelle l’évolution des composants et des systèmes
est quotidienne. Ce cours sera donc mis à jour en temps réel en fonction
de l'évolution des produits.
1. Présentation Du Cours
Ce cours expose les principes de fonctionnement des ordinateurs. Il s’agit
ici de comprendre, à bas niveau, l’organisation de ces machines.
De la couche la plus basse (langage machine) jusqu’à celle haute
(langage proche du langage humain), en passant par l’étude du codage
de l’information, de circuits logiques etc.
Nous nous appuierons sur l’étude détaillée de l’architecture PC de John
Van Neumann, dont nous étudierons ses principaux éléments matériels et
logiciels, les fonctions de base de son système d’exploitation, et ses
mécanismes de communication avec l’extérieur (entrées/sorties).
Puis nous conclurons ce cours par une mise au point du langage
assembleur et un panorama des différentes architectures actuelles
(processeurs CISC « Complex Instruction Set Computer ou Ordinateur a
jeu d’instruction Complexe » et RISC « Reduced Instruction Set Computer
ou Ordinateur a jeu d’instruction Réduit », etc.).
2. Plan du Cours
0. Introduction
0.1. Principes De Fonctionnement D’un Ordinateur
0.2. Architecture de base d’un ordinateur
Chapitre I : CODAGE DE L’INFORMATION
Chapitre II : ALGEBRE DE BOOLE
Chapitre III : CIRCUITS COMBINATOIRES
Université Protestante de Lubumbashi
Cours d’Architecture Des Ordinateurs - 2é BAC Informatique de
Gestion 2019-2020

Cours de structure des Ordinateurs
Chapitre IV : LE SYSTEME D’EXPLOITATION
Chapitre V : STRUCTURE DES COMPOSANTS HARDWARE
Chapitre VI : LES MEMOIRES
Chapitre VII : ASSEMBLEUR
Annexe : Exercices
1. Références Bibliographiques
a. Namur Cours de Hardware - en informatique 2015 – 2016
b. T.Dumartin Architecture des ordinateurs Note de cours 2013
c. Architecture des Ordinateurs Nicolas Delestre, Michel
Mainguenaud 2004
d. Emmanuel Viennet Architecture des ordinateurs 2015
e. Tisserant S, Architecture et Technologie des Ordinateurs, Louis
Pasteur, 2010
f. Martin B., Codage, cryptologie et applications, Presses
Polytechniques et Universitaires Romandes (PPUR), 2004
g. Comment ça marche, « Représentation des nombres entiers et
réels »,
<http://www.commentcamarche.net/contents/base/representation
.php3>

Cours de structure des Ordinateurs
0. Introduction
0.1. Principes De Fonctionnement D’un Ordinateur
Le fonctionnement d’un ordinateur repose sur le respect des principes
architecturaux (structure de la matière, la logique,…) issus de la physique
appliquée et de l’électricité exploitant les phénomènes de conduction
des électrons.

Cours de structure des Ordinateurs
0.2. Architecture de base d’un ordinateur
Dans cette partie, nous décrivons rapidement l’architecture de base d’un ordinateur
et les principes de son fonctionnement.
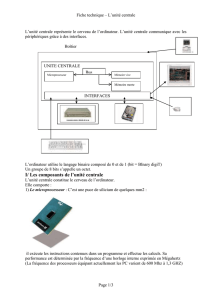
Un ordinateur est une machine de traitement de l’information. Il est capable
d’acquérir de l’information, de la stocker, de la transformer en effectuant des
traitements quelconques, puis de la restituer sous une autre forme. Le mot
informatique vient de la contraction des mots information et automatique.
Nous appelons information tout ensemble de données. On distingue généralement
différents types d’informations : textes, nombres, sons, images, etc., mais aussi les
instructions composant un programme. Cependant toute information est manipulée
sous forme binaire (ou numérique) par l’ordinateur.
0.2.1. Principes de fonctionnement
Les deux principaux constituants d’un ordinateur sont la mémoire principale et le
processeur. La mémoire principale (MP en abrégé) permet de stocker de
l’information (programmes et données), tandis que le processeur exécute pas à pas
les instructions composant les programmes.
0.2.2. Notion de programme
Un programme est une suite d’instructions élémentaires, qui vont être exécutées
dans l’ordre par le processeur. Ces instructions correspondent à des actions très
simples, comme additionner deux nombres, lire ou écrire une case mémoire, etc.
Chaque instruction est codifiée en mémoire sur quelques octets.
Le processeur est capable d’exécuter des programmes en langage machine,
c’est à dire composés d’instructions très élémentaires suivant un codage précis.
Chaque type de processeur est capable d’exécuter un certain ensemble
d’instructions, son jeu d’instructions.
Pour écrire un programme en langage machine, il faut donc connaître les détails
du fonctionnement du processeur qui va être utilisé.
0.2.3. Le processeur
Le processeur est un circuit électronique complexe qui exécute chaque instruction
très rapidement, en quelques cycles d’horloges. Toute l’activité de l’ordinateur est

Cours de structure des Ordinateurs
cadencée par une horloge unique, de façon à ce que tous les circuits électroniques
travaillent ensembles. La fréquence de cette horloge s’exprime en MHz (millions
de battements par seconde). Par exemple, un ordinateur “PC Pentium 133” possède
un processeur de type Pentium et une horloge à 133 MHz.
Pour chaque instruction, le processeur effectue schématiquement les opérations
suivantes :
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
1
/
114
100%